0. 지난 시간 복습 시간
# 지난 시간 복습
exam <- read.csv("./SpyderBD_01/data/csv_exam.csv")
exam
# 문법의 차이
# 데이터$변수이름 쓰는 경우
# 변수이름만 쓰는 경우
# => 파이프라인 기호의 유무 차이
# 예) 수학 점수
library(tidyverse)
exam$math
exam %>%
select(math)
# 데이터 살펴보기
head(exam,10)
exam %>%
head(10)
tail(exam)
exam %>%
tail()
head(exam$science)
exam %>%
select(science) %>%
head
# 행 추출
exam[exam$class == 1,]
exam %>%
filter(class == 1)
# 열 추출
exam[,"math"]
exam[,c("math","science")]
exam %>%
select(math)
exam %>%
select(math,science)
# 행과 열을 동시에 추출
exam %>%
filter() %>%
select()
c3_science <- exam %>%
filter(class == 3) %>%
select(science)
# 오름차순 = 낮은 값에서 높은 값으로 정렬
sort(exam$science)
exam %>%
arrange(math)
# 내림차순 = 높은 값에서 낮은 값으로 정렬
sort(exam$math, decreasing = T)
exam %>%
arrange(desc(math))
# 새로운 변수 생성
exam$score_sum <- exam$math + exam$english + exam$science
exam %>%
mutate(score_sum = math + english + science)
# 범주형 변수 만들기
exam$math_test <- ifelse(exam$math >= 80, "pass", "fail")
exam %>%
mutate(math_test = ifelse(math >= 80, "pass", "fail"))1. 조건에 맞는 데이터만 추출 CP6
1) group by
# 그룹별로 요약하기
aggregate(exam$math~exam$class, mean) # 오류 생길 수 있음
aggregate(exam$math~exam$class, FUN = "mean")
exam %>%
group_by(class) %>%
summarise(math_mean = mean(math))
mpg <- as.data.frame(ggplot2::mpg)
head(mpg)
# 문제) 회사별로 "suv" 자동차의 도시 및 고속도로 통합 연비 평균을 구해 내림차순으로 정렬하고, 1~5위까지 출력하기
mpg %>%
filter(class == "suv") %>%
mutate(total = (hwy + cty)/2) %>%
group_by(manufacturer) %>%
summarise(mean_total = mean(total)) %>%
head(5)
#
# Q1. mpg 데이터의 class 는 "suv", "compact" 등 자동차를 특징에 따라 일곱 종류로 분류한 변수입니다. 어떤 차종의 연비가 높은지 비교해보려고 합니다. class 별 cty 평균을 구해보세요.
# 내 풀이
head(mpg)
mpg %>%
filter(class == "suv" | class == "compact") %>%
mutate(mean_cty = cty+hwy/2)
# 정답
mpg %>%
group_by(class) %>%
summarise(cty_mean = mean(cty))
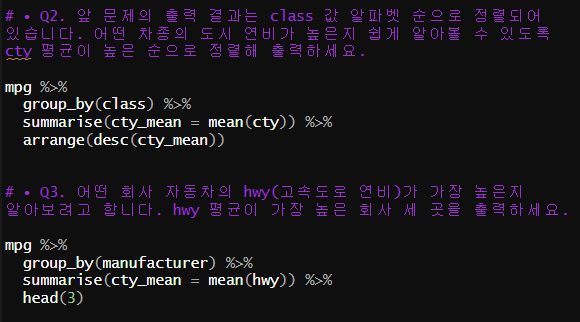
# • Q2. 앞 문제의 출력 결과는 class 값 알파벳 순으로 정렬되어 있습니다. 어떤 차종의 도시 연비가 높은지 쉽게 알아볼 수 있도록 cty 평균이 높은 순으로 정렬해 출력하세요.
mpg %>%
group_by(class) %>%
summarise(cty_mean = mean(cty)) %>%
arrange(desc(cty_mean))
# • Q3. 어떤 회사 자동차의 hwy(고속도로 연비)가 가장 높은지 알아보려고 합니다. hwy 평균이 가장 높은 회사
# 세 곳을 출력하세요.
mpg %>%
group_by(manufacturer) %>%
summarise(cty_mean = mean(hwy)) %>%
head(3)
# • Q4. 어떤 회사에서 "compact"(경차) 차종을 가장 많이 생산하는지 알아보려고 합니다. 각 회사별
# "compact" 차종 수를 내림차순으로 정렬해 출력하세요
head(mpg)
mpg %>%
filter(class == "compact") %>%
group_by(manufacturer) %>%
summarise(freq = n()) %>%
arrange(desc(freq))
2. 데이터 합치기 CP6
1) 데이터 합치기
# 데이터 합치기
# 데이터 준비
data1 <- data.frame(id=c(1,2,3,4,5),
mideterm = c(60,80,70,90,85))
data2 <- data.frame(id=c(1,2,3,4,5),
mideterm = c(70,83,65,95,80))
data1;data2
# 좌우로 합치기 = 다른 열
# 왼쪽 기준으로 합치기
left_join(data1,data2, by = "id")
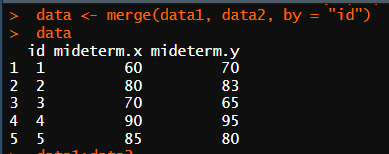
merge(data1, data2, by = "id") # 정확한 조인
# 반 별 선생님 이름 데이터 합치기
name <- data.frame(class = c(1,2,3,4,5),
name = c("kmh","skw","csw","ldh","lyk"))
head(left_join(exam,name, by = "class"))
head(left_join(data1,data2, by = "id"))
data <- merge(data1, data2, by = "id")
data
# 교집합으로 합치기
data <- merge(data1, data2, by = "id")
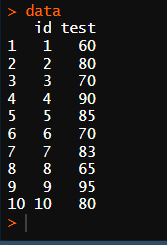
# 위 아래로 합치기 = 같은 열
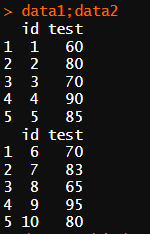
data1 <- data.frame(id = c(1,2,3,4,5),
test = c(60,80,70,90,85))
data2 <- data.frame(id = c(6,7,8,9,10),
test = c(70,83,65,95,80))
data1;data2
data <- bind_rows(data1,data2)
data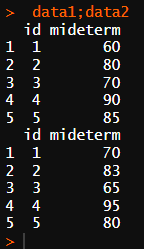
2) 문제풀이 1
# 문제풀이
# 데이터 기본
fuel <- data.frame(fl = c("c","d","e","p","r"),
price_fl=c(2.35,2.38,2.11,2.76,2.22),
stringsAsFactors = F)
fuel
# • Q1. mpg 데이터에는 연료 종류를 나타낸 fl 변수는 있지만 연료 가격을 나타낸 변수는 없습니다. 위에서 만든 fuel 데이터를 이용해서 mpg 데이터에 price_fl(연료 가격) 변수를 추가하세요.
mpg <- left_join(mpg,fuel)
# • Q2. 연료 가격 변수가 잘 추가됐는지 확인하기 위해서 model, fl, price_fl 변수를 추출해 앞부분 5 행을 출력해 보세요
mpg %>%
head(5)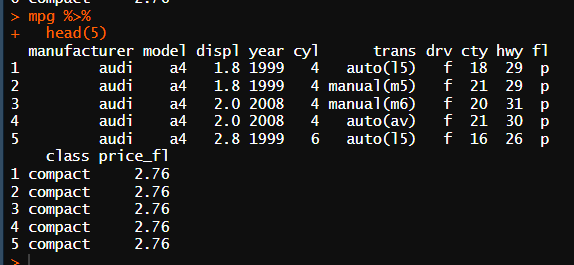
3) 문제풀이 2
# 미국 동북중부 437개 지역의 인구통계 정보를 담고 있는 midwest 데이터를 사용해 데이터 분석 문제를 해결해 보세요. midwest는 ggplot2 패키지에 들어 있습니다.
midwest <- as.data.frame(ggplot2::midwest)
# • 문제 1. popadults 는 해당 지역의 성인 인구, poptotal 은 전체 인구를 나타냅니다. midwest 데이터에 '전체 인구 대비 미성년 인구 백분율' 변수를 추가하세요.
head(midwest)
midwest <- midwest %>%
mutate( ad_total = ((poptotal-popadults)/poptotal)*100)
midwest
# • 문제 2. 미성년 인구 백분율이 가장 높은 상위 5 개 county(지역)의 미성년 인구 백분율을 출력하세요.
midwest %>%
arrange(desc(ad_total)) %>%
select(county,ad_total) %>%
head(5)
# • 문제 3. 분류표의 기준에 따라 미성년 비율 등급 변수를 추가하고, 각 등급에 몇 개의 지역이 있는지 알아보세요.
midwest <- midwest %>%
mutate(grade = ifelse(ad_total>=40, "large",
ifelse(ad_total>=30, "middel","small")))
midwest %>%
group_by(grade) %>%
summarise(freq = n())
head(midwest)
head(midwest)
table(midwest$grade)
# 분류 기준
# large 40% 이상
# middle 30% ~ 40% 미만
# small 30% 미만
# • 문제4. popasian은 해당 지역의 아시아인 인구를 나타냅니다. '전체 인구 대비 아시아인 인구 백분율' 변수를 추가하고, 하위 10개 지역의 state(주), county(지역명), 아시아인 인구 백분율을 출력하세요
midwest %>%
mutate(asian_pct = popasian/poptotal*100) %>%
select(state,county,asian_pct) %>%
head(10)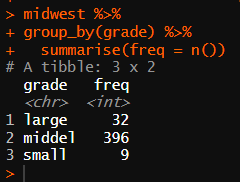
3. 데이터 제거하기 (데이터 정제) CP 7
1) 데이터 제거하기 (데이터 정제) 1
- 데이터 제거란 결측치가 포함되는 내용.
# 데이터 정제
# 결측치 = MV(missing value) = NULL = NA
df <- data.frame(sex=c("M","F",NA,"M","F"),
score = c(5,4,3,4,NA))
df
# 논리형으로 반환(참, 거짓)
is.na(df)
# NA 개수
table(is.na(df))
# 현재 데이터에는 결측치가 2개 있다
# 특정 열에서 NA 개수
table(is.na(df$sex))
# 현재 열에는 결측치가 1개 있다
table(is.na(df$score))
# 결측치가 있는 데이터를 이용해서 함수 사용
mean(df$score)
# 결측치가 있으면 평균 구할 수 없음
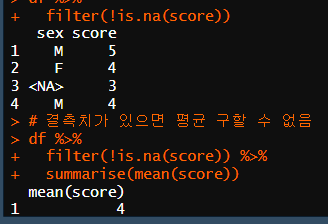
df %>%
filter(!is.na(score)) %>%
summarise(mean(score))
mean(df[!is.na(df$score),]$score)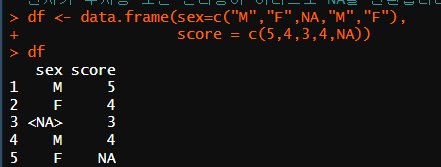
2) 데이터 제거하기 2 (NA제거)
# 함수에서 제공하는 NA 제거 옵션(na.rm =T)
mean(df$score, na.rm = T)
# NA 제거해서 저장한 뒤 함수 적용
df_nona <- df %>%
filter(!is.na(score))
mean(df_nona$score)
# 성별과 점수의 NA 동시에 제거
df %>%
filter(!is.na(sex) & !is.na(score))
# 모든 NA 제거
df_omit <- na.omit(df)
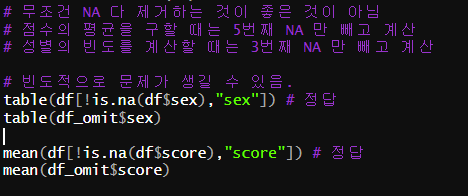
# 무조건 NA 다 제거하는 것이 좋은 것이 아님
# 점수의 평균을 구할 때는 5번째 NA 만 빼고 계산
# 성별의 빈도를 계산할 때는 3번째 NA 만 빼고 계산
# 빈도적으로 문제가 생길 수 있음.
table(df[!is.na(df$sex),"sex"]) # 정답
table(df_omit$sex)
mean(df[!is.na(df$score),"score"]) # 정답
mean(df_omit$score)
exam <- read.csv("./SpyderBD_01/data/csv_exam.csv")
head(exam)
# 결측치 만들기
exam[c(5,10,15),"math"] <- NA
# NA 있으면 평균 계산 안됨
exam %>%
summarise(math_mean = mean(math))
# 해결 방법: 1) NA제거하고 계산
exam %>%
filter(!is.na(math)) %>%
summarise(math_mean = mean(math))
# 2) 함수의 NA 제거 옵션 사용
exam %>%
summarise(math_mean = mean(math, ra.rm = T))
3) 데이터 제거하기 3 (결측치 대체하기)
# 결측치 대체 = imputation = 중심경향척도(평균, 중앙값) 대체
mean(exam$math, na.rm = T)
# 58.76471 (평균)으로 NA값 대체
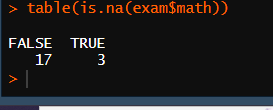
table(is.na(exam$math))
# 현재 결측치 3개를 평균으로 대체
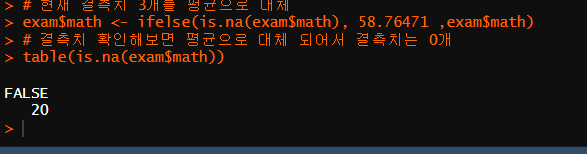
exam$math <- ifelse(is.na(exam$math), 58.76471 ,exam$math)
# 결측치 확인해보면 평균으로 대체 되어서 결측치는 0개
table(is.na(exam$math))
4) 문제
# mpg 데이터를 이용해서 분석 문제를 해결해 보세요.
# mpg 데이터 원본에는 결측치가 없습니다. 우선 mpg 데이터를 불러와 몇 개의 값을 결측치로 만들겠습니다. 아래 코드를 실행하면 다섯 행의 hwy 변수에 NA가 할당됩니다.
mpg <- as.data.frame(ggplot2::mpg) # mpg 데이터 불러오기
mpg[c(65, 124, 131, 153, 212), "hwy"] <- NA # NA 할당하기
# Q1. drv(구동방식)별로 hwy(고속도로 연비) 평균이 어떻게 다른지 알아보려고 합니다. 분석을 하기 전에 우선 두 변수에 결측치가 있는지 확인해야 합니다. drv 변수와 hwy 변수에 결측치가 몇 개 있는지 알아보세요.
table(is.na(mpg$drv)) # 234
table(is.na(mpg$hwy)) # 229
# • Q2. filter()를 이용해 hwy 변수의 결측치를 제외하고, 어떤 구동방식의 hwy 평균이 높은지 알아보세요. 하나의 dplyr 구문으로 만들어야 합니다 // 그룹by
mpg %>%
filter(!is.na(hwy)) %>% # 결측치 제외
group_by(drv) %>% # drv별 분리 (구동방식)
summarise(mean_hwy = mean(hwy)) # hwy 평균 구하기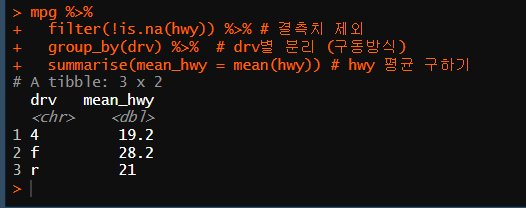
4. 이상치 제거하기 (이상치 정제) CP 7
1) 이상치 제거 (조건식 걸어서)
# 이상치 = outlier
# 1) 존재할 수 없는 값 = 남자 1 & 여자 2 인 경우에 3번 값
# 2) 극단적인 값 = 몸무게
# 데이터 준비하기
outlier <- data.frame(sex = c(1,2,1,3,2,1),
score = c(5,4,3,4,2,99))
# 이상치 확인하기
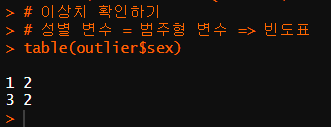
# 성별 변수 = 범주형 변수 => 빈도표
table(outlier$sex)
# 1은 남자, 2는 여자이므로, 나머지 3은 이상치
# 점수 변수 = 연속형 변수 => 요약 통계
# 점수의 정상 분포는 0~5점
summary(outlier$score)
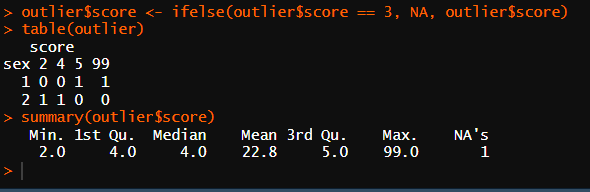
# 최대값 99점은 극단적으로 높은 값
# 확인된 이상치는 NA로 변경해줘야 함
# NA 해결 방법 동일
outlier$sex <- ifelse(outlier$sex == 3, NA, outlier$sex)
table(outlier$sex)
outlier$score <- ifelse(outlier$score == 3, NA, outlier$score)
summary(outlier$score)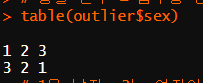
2) 이상치 제거의 오류
# 이상치를 결측치(NA)로 변경한 뒤 결측치 제거
outlier %>%
filter(!is.na(sex) & !is.na(score)) %>%
group_by(sex) %>%
summarise(score_mean = mean(score))
#
outlier_omit <- na.omit(outlier)
table(outlier$sex)
table(outlier_omit$sex)
mean(outlier$score, na.rm = T)
mean(outlier_omit$score, na.rm = T)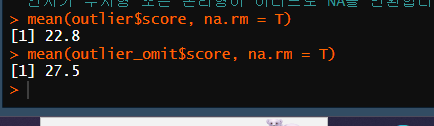
3) 이상치 처리하는 법.
# 이상치 확인하는 통계적 판단 = 데이터 기반 판단
mpg <- as.data.frame(ggplot2::mpg)
# 상자수염그림
cty_bp <- boxplot(mpg$cty)
cty_bp$stats
# 9는 하한값, 26은 상한값, 이 범위를 벗어나면 이상치
# (이상치 처리하기)
mpg$cty <- ifelse(mpg$cty <9 | mpg$cty > 26, NA, mpg$cty)
table(mpg$cty)
# NA를 제거하고 cty 평균 계산
mpg %>%
filter(!is.na(cty)) %>%
summarise(cty_mean = mean(cty))
4) 문제
# 구동방식별로 도시 연비가 다른지 알아보려고 합니다. 분석을 하려면 우선 두 변수에 이상치가 있는지 확인하려고 합니다.
mpg <- as.data.frame(ggplot2::mpg) # mpg 데이터 불러오기
mpg[c(10, 14, 58, 93), "drv"] <- "k" # drv 이상치 할당
mpg[c(29, 43, 129, 203), "cty"] <- c(3, 4, 39, 42) # cty 이상치 할당
# • Q1. drv 에 이상치가 있는지 확인하세요. 이상치를 결측 처리한 다음 이상치가 사라졌는지 확인하세요. 결측처리 할 때는 %in% 기호를 활용하세요. 나머지는 NA로 바꿔야 함 (바로 k로 바꾸지 말고)
# 4,f,k,r에서 k만 제거하라는 뜻 (k를 na로)
table(mpg$drv)
mpg$drv <- ifelse(mpg$drv %in% c("4","f","r"), mpg$drv, NA)
table(mpg$drv)
# • Q2. 상자 그림을 이용해서 cty 에 이상치가 있는지 확인하세요. 상자 그림의 통계치를 이용해 정상 범위를 벗어난 값을 결측 처리한 후 다시 상자 그림을 만들어 이상치가 사라졌는지 확인하세요.
mpg <- as.data.frame(ggplot2::mpg) # 범위 확인하기
boxplot(mpg$cty)$stats # 범위를 조건식으로 지정해서 그 이외 값은 NA로 표시하기
mpg$cty <- ifelse(mpg$cty<9 | mpg$cty>26, NA, mpg$cty)
boxplot(mpg$cty)
# • Q3. 두 변수의 이상치를 결측처리 했으니 이제 분석할 차례입니다. 이상치를 제외한 다음 drv 별로 cty 평균이 어떻게 다른지 알아보세요. 하나의 dplyr 구문으로 만들어야 합니다
mpg %>%
filter(!is.na(mpg$cty)) %>%
group_by(drv) %>%
summarise(mean(cty))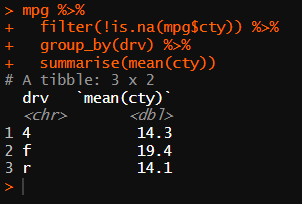
4. 그래프 만들기 CP 8
1) 일반적인 그래프 정의
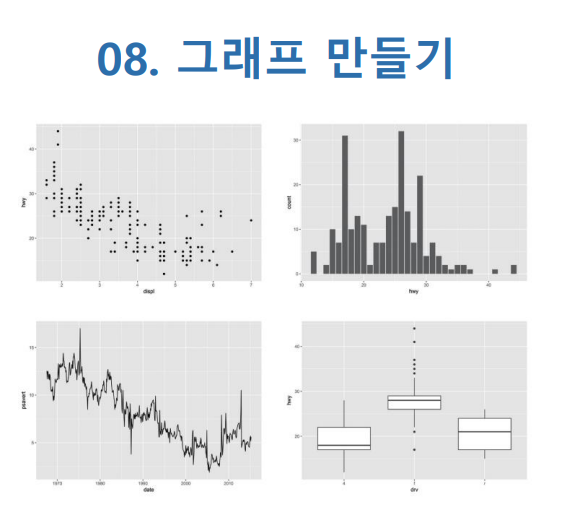
(좌측부터 1234)
* 산점도 (y= 고속도로 연비, x=배기량)* 히스토그램 (y=빈도, x=고속도로 연비)* 선 그래프 (y=개인 저축율, x=날짜)* 상자수열그림 (y=고속도로 연비, x= 구간)
2) R로 만들 수 있는 그래프
3) ggplot2 레이어
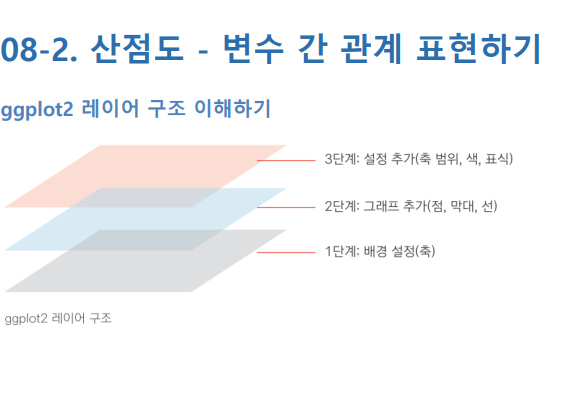
ggplot에서 명령어를 합칠 때는 + 연산자를 사용한다.
4) 산점도 만들기
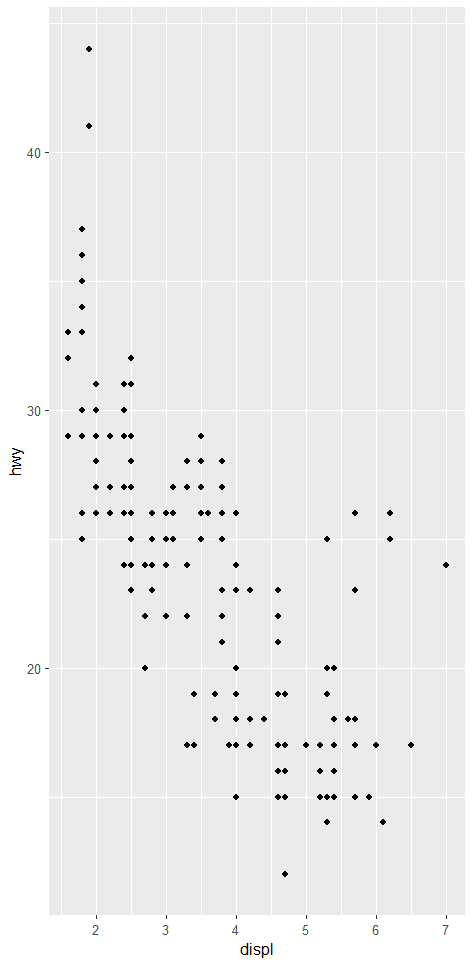
상관분석, 회귀분석 할 때 Scater Plot(산점도)을 사용함
* 핵심
- group_by는 항상 앞에서 그룹 이야기를 꺼낼 때 자주 사용한다. // ~~~in
- summarise에서 변수를 카운팅하는 횟수인 n()는 변수를 카운팅 해준다.
- merge 함수가 정렬을 할 때 범용성 있게 쓰인다.
- 평균을 구할 때 NA제거 (na.omit(df))는 통계 오류를 범할 수 있기 때문에 잘써야 한다.
'배운 책들 정리 > 만만한 통계 : R 활용' 카테고리의 다른 글
| 0302 만만한 통계 R 외부 챕터 9~10 - 데이터 분석 프로젝트 2, 텍스트 마이닝 (0) | 2023.03.02 |
|---|---|
| 0228 만만한 통계 R 외부 챕터 8~9 - 그래프 만들기, 데이터 분석 프로젝트 (0) | 2023.02.28 |
| 0224 만만한 통계 R 외부 챕터 4~6 - 데이터 프레임, 데이터 분석, 데이터 가공 (1) | 2023.02.24 |
| 0223 만만한 통계 R 외부 챕터 15 - 내장 함수, 변수 타입과 데이터 구조 // 기초 문제 연습 (0) | 2023.02.23 |
| 0222 만만한 통계 R - 카이제곱 검정과 기타 비모수 검정 (CP19) (0) | 2023.02.22 |



