15 R 내장함수, 변수 타입과 데이터 구조
1) 연속형 변수 (빈도 분석)
연속형 변수 (숫자) : 평균, 표준편차 -> SUMMARY() -> 차이검정(독립표본T검정)
2) 범주형 변수 (카이제곱)
범주형 변수 (그룹/문자) : 빈도, 비율 -> TABLE() -> 카이제곱 검정
3) 실습 1 (행추출)
# 내장함수
# 데이터 준비하기
exam <- read.csv("./SpyderBD_01/data/csv_exam.csv")
exam
# 데이터 추출
# 인덱스 : 데이터의 위치(번호, 이름)
# 행과 열 => 행번호, 행이름, 열번호, 열이름
# 인덱스 사용법:데이터[행,열]
# 행 추출
exam[1,]
exam[15,]
exam[c(1:10),]
exam[c(11:20),]

2) 실습2 (이름으로 추출까지)
exam[seq(1,20,by=2),]
exam[seq(0,20,by=2),]
# 조건을 만족하는 행 추출
str(exam)
# 같다
exam[exam$class == 1,]
# 같지 않다 (!=)
exam[exam$class != 1,]
# 크다 = 초과 (>)
exam[exam$english > 97,]
# 크거나 같다 = 이상 (>=)
exam[exam$english > 97,]
# 수학점수 50점 // 작다 == 미만 (<)
exam[exam$math <= 50,]
# 작거나 같다 = 이하 (<=)
exam[exam$math <= 50,]
# 조건 두 개 이상
# and
exam[exam$class == 3 & exam$science >= 50,]
# or
exam[exam$math > 70 | exam$science <= 30,]
#
exam[exam$math > 70 | exam$class == 3 & exam$science <= 30,]
# 열번호
str(exam)
#
exam[,1] # id
exam[,2] # class
exam[,3] # math
exam[,4] # english
exam[,5] # science
exam[,6]
exam[,c(1:3)]
exam[,c(3:5)]
exam[,c(1,3,5)]
# 열이름으로 열 추출
exam[,"id"] # id
exam[,"class"] # class
exam[,"math"] # math
exam[,"english"] # english
exam[,"science"] # science
# 열 이름으로 여러개열 추출
exam[,c("id","class","math")]
exam[,c("math","english","science")]
exam[,c("id","math","science")]
3) 실습3 (행 조건 & 열 여러개)
#
# 행과 열을 동시에 추출
# 행번호 & 열번호
exam[1,5]
# 행번호&열이름
exam[1,"science"]
# 행 조건 & 열번호
exam[exam$math > 80,5]
# 행 조건 & 열이름
exam[exam$math > 80,"science"]
# 행 조건 & 열 여러개
exam[exam$math > 80,c(4,5)]
exam[exam$math > 80,c("english","science")]
4) 실습4 (수학 점수 50 이상, 영어 점수 80 이상인 학생들을 대상으로 각 반의 전 과목 총평균을 구하라.)
# 문제) 수학 점수 50 이상, 영어 점수 80 이상인 학생들을 대상으로 각 반의 전 과목 총평균을 구하라.
subset <- exam[exam$math >= 50 & exam$english >= 80,]
subset
subset$total <- (subset$math + subset$english + subset$science)
subset
subset$mean_score <- subset$total/3
subset
# 각 반의 평균을 구하는 것
exam$total <- (exam$math + exam$english + exam$science)/3
head(exam)
aggregate(data = exam[exam$math >= 50 & exam$english >= 80,],total~class, FUN = "mean")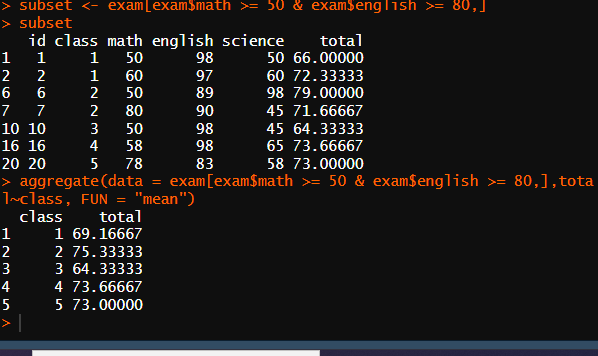
5) 실습 5 (tidy문법)
# tidy문법
# tidyverse
install.packages("tidyverse")
library(tidyverse)
# 파이프라인 = shift + ctrl + m
exam %>%
filter(math >= 50 & english >= 80) %>% # 행추출
mutate(total=( math + english + science)/3) %>% # 새로운 변수 생성
group_by(class) %>% #그룹 생성
summarise(mean_score = mean(total)) # 요약 결과 생성(예, 평균)
%>% (파이프라인) : 순차적으로 함수를 실행시키는. 명령어와 명령어를 연결하는 키다.
6) 실습 6 (ggplot2::mpg)
#
# "compact"와 "suv" 차종의 '도시 및 고속도로 통합 연비' 평균
# mpg 데이터 : ggplot2에서 제공하는 내장데이터
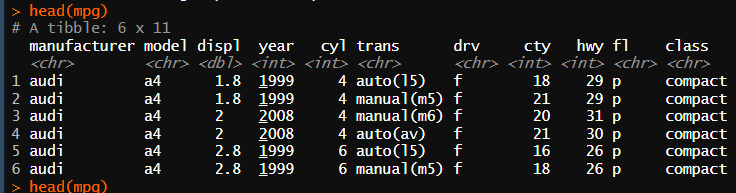
mpg <- as.data.frame(ggplot2::mpg)
head(mpg)
str(mpg)
# 내장함수 사용
compact <- mpg[mpg$class == "compact",]
suv <- mpg[mpg$class == "suv",]
# 통합연비 구하기
compact$total <- (compact$cty +compact$hwy)/2
suv$total <- (suv$cty+suv$hwy)/2
head(compact)
head(suv)
# 연비가 높은게 더 좋은거
mean(compact$total)
mean(suv$total)



7) 실습 7 (tidyverse 사용)
# tidyverse 사용
mpg %>%
filter(class == "compact" | class == "suv") %>%
mutate(total=(cty+hwy)/2) %>% # 새로운 변수 생성
group_by(class) %>% #그룹 생성
summarise(mean_score = mean(total)) # 요약 결과 생성(예, 평균)
8) 변수타입
* 숫자 (연속 변수) // Numeric 타입
소수점 x : int
소수점 o : numeric
*문자 (범주 변수) // Factor 타입
character
9) 변수타입 실습
# 데이터타입 = 변수타입 = 자료형
# 값을 숫자로 입력한 경우
var1 <- c(1,2,3,1,2)
var1
var2 <- factor(c(1,2,3,1,2))
var2
var1+1
var2+1
class(var1)
class(var2)
# 값을 문자로 입력한 경우
var3 <- c("a","b","b","c")
var3
var4 <- factor(c("a","b","b","c"))
var4
var3+2
var4+2
class(var3)
class(var4)문자는 " "가 있고, 숫자는 " " 가 없다.
10) 함수적용 실습
# 함수적용
var1
mean(var1)
var2
mean(var2)
var3
mean(var3)
var4
mean(var4)
summary(var1)
summary(var2)
mean(var3)
table(var3)
summary(var3)
var4
mean(var4)
table(var4)
summary(var4)
11) 데이터타입 변경 실습 & 문제
# 데이터타입변경
var1;var2
class(var1);class(var2)
var2 <- as.numeric(var2)
class(var1);class(var2)
# as.character():문자형으로 변경
# as.factor() : 범주형으로 변경
# as.integer() : 정수형으로 변경
# as.Date() : 날짜형으로 변경

mpg <- as.data.frame(ggplot2::mpg)
head(mpg)
str(mpg)
# Q1
class(mpg$drv)
# Q2
mpg$drv<- as.factor(mpg$drv)
class(mpg$drv)
# Q3
levels(mpg$drv)
a) mpg 데이터의 drv 변수는 자동차 구동 방식을 나타낸다. mpg 데이터를 이용해 아래 문제를 해결하시오
Q1. drv 변수의 타입을 확인
Q2. drv 변수 as.factor()를 이용해 벼노한 후 다시 타입 확인
Q3. drv 범주의 구성 확인
12) 15-3 데이터 구조
# 자료구조
# 1. 벡터 : 하나의 값, 여러 개의 값, 같은 데이터 타입
a <- 3
a
b <- c(1:5)
b
c <- "hi"
d <- c("a","b","c","a")
d
class(a);class(b);class(c);class(d)
# 2. 데이터프레임 : 행과 열로 구성된 2차원, 열들이 서로 다른 데이터타입 가질 수 있음
df <- data.frame(var1=c(1,2,3),var2=c("a","b","c"))
df
class(df)
class(df$var1);class(df$var2)
# 3. 매트릭스 : 행과 열로 구성된 2차원, 같은 데이터타입만 저장 가능
mx <- matrix(c(1:12),ncol = 4)
class(mx)
# 4. 어레이 : 행과 열로 구성된 매트릭스가 여러 겹이 있는 구조
ar <- array(1:18, dim=c(3,6,3))
class(ar)
# 5. 리스트 : 모든 데이터 구조를 저장할 수 있음
ls <- list(list1= a,
list2= df,
list3= mx,
list4= ar)
ls
class(ls)* 벡터, 데이터프레임, 매트릭스, 어레이, 리스트 구분 필요!
13) 실습 (리스트 활용)
# 벡터를 꺼내서 사용하기
ls$list1
vec <- ls$list1
vec
# = a
# 데이터프레임을 꺼내서 사용하기
ls$list2
# 매트릭스를 꺼내서 사용하기
ls$list3
# 어레이를 꺼내서 사용하기
ls$list4
14) 실습 (상자수염그림)
# 리스트를 실제 활용하는 예
mpg <- as.data.frame(ggplot2::mpg)
# 상자수염그림
bp <- boxplot(mpg$hwy)
bp
bp$stats
# 하한값
bp$stats[1]
lower_limit <- bp$stats[1,]
lower_limit
# 상한값
bp$stats[1]
upper_limit <- bp$stats[5,1]
upper_limit
양 끝 실선은 경계치 (하한값, 상한값) // 이를 벗어나면 이상치
3. 데이터 분석을 위한 연장 챙기기
1) 실습1 (qplot을 통한 그래프 확인)
# 패키지
library(ggplot2)
x <- c("a","a","b","c")
# quick plot : 탐색적 목적으로 빠르게 시각화
# 막대그래프 : 범주형변수의 빈도 표현
qplot(x)
#
mpg <- as.data.frame(ggplot2::mpg)
# 히스토그램: 연속형변수(구간)의 빈도 표현
qplot(data = mpg, x = hwy)
# 상자수염그림
qplot(data = mpg, x = drv, y = hwy, geom = "boxplot")
2) 실습 문제1
# Q1
x <- c(80,60,70,50,90)
# Q2
mean(x)
# Q3
a <- mean(x)
a
3) 실습 문제2 (데이터프레임)
# CP3
# 데이터프레임
english <- c(70,80,90,100)
math <- c(50,60,70,80)
class <- c(1,1,2,2)
english;math;class
df_mideterm <- data.frame(english,math,class)
df_mideterm
# 2) 직접 생성
df_mideterm <- data.frame(english = c(70,80,90,100),
math = c(50,60,70,80),
class = c(1,1,2,2))
df_mideterm

4) 실습 문제3 (데이터프레임, 평균값)

# Q1
apple <- c(1800,24)
strawberry <- c(1500,38)
water <- c(3000,13)
fr<- data.frame(fruit=c("apple","strawberry","water-melon"),
prcie=c(1800,1500,3000),
quantity = c(24,38,13))
fr
# Q2
mean(fr$prcie)
mean(fr$quantity)
5) 실습 (외부 데이터 및 colnames 활용)
# 외부데이터 불러오기
# 엑셀데이터
library(readxl)
df_exam <- read_excel("./SpyderBD_01/data/excel_exam.xlsx")
head(df_exam)
# 평균
mean(df_exam$math)
mean(df_exam$english)
mean(df_exam$science)
# 코드 빠진 경우가 은근 많음
df_exam <- read_excel("./SpyderBD_01/data/excel_exam_novar.xlsx", col_names = F)
head(df_exam)
colnames(df_exam) <- c("id","class","math","english","science")

6) 시트에 열 이름이 없는 경우
# 데이터가 시트로 구별되어 있는 경우
# 시트 번호
df_exam <- read_excel("./SpyderBD_01/data/excel_exam_sheet.xlsx", sheet = "exam")
# 시트 이름
# csv데이터
# 열 이름이 있는 경우
df_csv_exam <- read.csv("./SpyderBD_01/data/csv_exam.csv")
head(df_csv_exam)
# 열 이름이 없는 경우
df_csv_exam <- read.csv("./SpyderBD_01/data/csv_exam.csv", header = F)
head(df_csv_exam)
* 핵심
파이프라인
데이터프레임 사용법
'배운 책들 정리 > 만만한 통계 : R 활용' 카테고리의 다른 글
| 0227 만만한 통계 R 외부 챕터 6~8 - 데이터 추출, 데이터 합치기, 데이터 정제, 그래프 (0) | 2023.02.27 |
|---|---|
| 0224 만만한 통계 R 외부 챕터 4~6 - 데이터 프레임, 데이터 분석, 데이터 가공 (1) | 2023.02.24 |
| 0222 만만한 통계 R - 카이제곱 검정과 기타 비모수 검정 (CP19) (0) | 2023.02.22 |
| 0221 만만한 통계 R - 선형회귀, 단순회귀, 다중회귀 (18) (0) | 2023.02.21 |
| 0220 만만한 통계 R - 상관계수 계산 및 유의성 검정, 보건의료(7,17) (0) | 2023.02.20 |



