1. 외부 챕터 4~5 (데이터 프레임, 데이터 분석 기초)
1) 실습 (csv파일 저장 및 불러오기)
# Q1
apple <- c(1800,24)
strawberry <- c(1500,38)
water <- c(3000,13)
fr<- data.frame(fruit=c("apple","strawberry","water-melon"),
prcie=c(1800,1500,3000),
quantity = c(24,38,13))
fr
head(fr)
# csv파일로 저장하기
write.csv(fr, file="./SpyderBD_01/data/sales.csv",row.names=F)
# 데이터 객체 삭제
rm(sales)
sales
# rdata로 저장하기
save(sales,file="./SpyderBD_01/data/sales.rda")
# rdata 불러오기
load("./SpyderBD_01/data/sales.rda")
sales
# csv파일 불러오기
sales <- read.csv("./SpyderBD_01/data/sales.csv")
head(sales)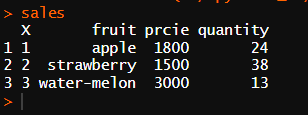
정리
rds : 하나만 저장
rda : 여러개 저장
2)실습 (데이터 확인)
# 텍스트데이터
df_txt_exam <- read.csv("./SpyderBD_01/data/csv_exam.txt",sep="\t")
str(df_txt_exam)
# 데이터 파악하기
exam <- read.csv("./SpyderBD_01/data/csv_exam.csv")
dim(exam)
# 데이터 앞부분 보기, 기본 값이 6개의 행
head(exam)
# 2개의 행만 보고 싶다면
head(exam,2)
# 데이터 뒷부분 보기, 기본 값이 6개의 행
tail(exam)
# 2개의 행만 보고 싶다면
tail(exam,2)
# 데이터 전체 구조나 속성 보기
str(exam)
dim(exam)
# 행 개수만 알고 싶다면
dim(exam)[1]
# 열 개수만 알고 싶다면
dim(exam)[2]
3) 실습 (데이터 분포 확인)
# 새로운 창에서 전체 데이터 보기
View(exam)
# 데이터 분포 보기
summary(exam)
# 원하는 데이터만
summary(exam$math)
# 반의 정보 확인
table(exam$class)
# 내장 데이터 불러오기
mpg <- as.data.frame(ggplot2::mpg)
head(mpg)
tail(mpg)
str(mpg)
dim(mpg)
summary(mpg)
table(mpg$trans)
table(mpg$model)
4) 내장 데이터 불러오기(ggplot2::mpg) & 복사본 생성 & 이름 변경
# 내장 데이터 불러오기
mpg <- as.data.frame(ggplot2::mpg)
head(mpg)
tail(mpg)
str(mpg)
dim(mpg)
summary(mpg)
table(mpg$trans)
table(mpg$model)
# 데이터 수정
library(tidyverse)
# 샘플 데이터 수정
df_raw <- data.frame(var1 = c(1,2,1),
var2 = c(2,3,2)
)
df_raw
# 복사본 만들기
df_new <- df_raw
df_new
# 변수 이름 변경 (변경하고 싶은 이름=변경되기 전 이름)
df_new <- rename(df_new,
v2 = var2)
df_new5) mpg 데이터 실습 문제 (복사본 생성 & 이름 변경)
# mpg 데이터의 변수명은 긴 단어를 짧게 줄인 축약어로 되어있습니다. cty 변수는 도시 연비, hwy 변수는 고속도로 연비를 의미합니다. 변수명을 이해하기 쉬운 단어로 바꾸려고 합니다. mpg 데이터를 이용해서 아래 문제를 해결해 보세요
# Q1. ggplot2 패키지의 mpg 데이터를 사용할 수 있도록 불러온 뒤 복사본을 만드세요.
mpg <- as.data.frame(ggplot2::mpg)
mpg
new_mpg <- mpg
new_mpg
# • Q2. 복사본 데이터를 이용해서 cty는 city로, hwy는 highway로 변수명을 수정하세요.
new_mpg <- rename(new_mpg,
city = cty,
highway = hwy)
# • Q3. 데이터 일부를 출력해서 변수명이 바뀌었는지 확인해 보세요. 아래와 같은 결과물이 출력되어야 합니다.
head(new_mpg)
6) 파생변수
파생변수란 새로운 변수를 의미
# 새로운 변수 만들기
df <- data.frame(var1 = c(4,8,6),
var2 = c(2,5,4)
)
df
# 합계 변수
df$sum <- df$var1+df$var2
df
# 평균 변수
df$mean <- df$sum/2
df
#
(df$var1+df$var2)/ncol(df)
# 통합연비 변수
mpg$total <- (mpg$cty+mpg$hwy)/2
head(mpg)
summary(mpg$total)
hist(mpg$total)
# 통합연비 변수를 범주형 변수로 만들기
# ifelse(조건,조건을 만족할 때 값, 조건을 만족하지 않을 때 값)
mpg$test <- ifelse(mpg$total >= 20, "pass", "fail")
head(mpg)
# 빈도표
table(mpg$test)
# 막대그래프
library(ggplot2)
qplot(mpg$test)
# 3개의 그룹을 가지는 범주형 변수 만들기
25보다 크면 a등급
20보다 크면 b등급
나머지는 c등급
mpg$grade <- ifelse(mpg$total >= 25, "A",
ifelse(mpg$total>=20, "B", "C"))
head(mpg)
table(mpg$grade)
# 4개의 그룹을 가지는 범주형 변수 만들기
# 30보다 크면 A,
# 25보다 크면 B,
# 20보다 크면 C,
# 나머지는 D
mpg$grade_new <- ifelse(mpg$total >= 30, "A",
ifelse(mpg$total>=25, "B",
ifelse(mpg$total>=20, "C", "D")))
head(mpg)
table(mpg$grade_new)
qplot(mpg$grade_new)
7) 실습문제 1 (인구통계 분석)
# 교수님
# ggplot2 패키지에는 미국 동북중부 437개 지역의 인구통계 정보를 담은 midwest라는 데이터가 포함되어 있습니다. midwest 데이터를 사용해 데이터 분석 문제를 해결해보세요.
# • 문제 1. ggplot2 의 midwest 데이터를 데이터 프레임 형태로 불러와서 데이터의 특성을 파악하세요.
library(dplyr)
library(ggplot2)
new_mid <- as.data.frame(ggplot2::midwest)
head(new_mid)
tail(new_mid)
str(new_mid)
View(new_mid)
summary(new_mid)
# • 문제 2. poptotal(전체 인구)을 total 로, popasian(아시아 인구)을 asian 으로 변수명을 수정하세요.
new_mid <- rename(new_mid,total=poptotal,
asian=popasian)
head(new_mid)
# • 문제 3. total, asian 변수를 이용해 '전체 인구 대비 아시아 인구 백분율' 파생변수를 만들고, 히스토그램을 만들어 도시들이 어떻게 분포하는지 살펴보세요.
new_mid$asian_pct <- (new_mid$asian/new_mid$total)*100
head(new_mid)
hist(new_mid$asian_pct)
# • 문제 4. 아시아 인구 백분율 전체 평균을 구하고, 평균을 초과하면 "large", 그 외에는 "small"을 부여하는 파생변수를 만들어 보세요.
ap_mean<- mean(new_mid$asian_pct)
new_mid$asian_pct_group <- ifelse(new_mid$asian_pct > ap_mean, "large","small")
head(new_mid)
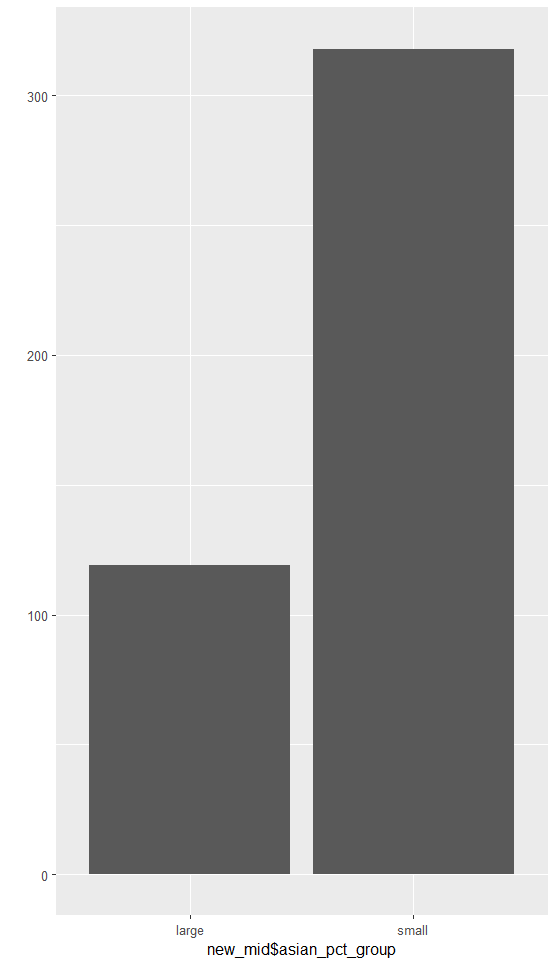
# • 문제 5. "large"와 "small"에 해당하는 지역이 얼마나 되는지, 빈도표와 빈도 막대 그래프를 만들어 확인해보세요
table(new_mid$asian_pct_group)
qplot(new_mid$asian_pct_group)




2. 외부 챕터 6 - 자유자재로 데이터 가공
1) dplyr 패키지 내용 확인

bind_rows = union all (sql문과 같음)
2) 조건식을 통해 제어
# 오후
# 데이터 전처리
# 조건에 맞는 행(데이터) 추출
library(tidyverse)
exam <- read.csv("./SpyderBD_01/data/csv_exam.csv")
head(exam)
# 파이프라인 : shift + ctrl + m
# %>%
# 조건에 맞는 행(데이터) 추출
exam %>%
filter(class == 1)
exam %>%
filter(class !=5)
# 크다 = 초과
exam %>%
filter(math >80)
# 크거나 같다 = 이상
exam %>%
filter(math >=80)
# 작거나 같다 = 이하
exam %>%
filter(english<= 68)
# 여러 개의 조건
# and = 교집합 / or 합집함
# and
exam %>%
filter(class == 2 & science > 60)
# or = 조건 중 하나라도 만족하는 경우
exam %>%
filter(class == 2 & science > 60)ㅊ]
# or 조건을 여러개 사용
exam %>%
filter(class == class 1 class ==3, class+5)
exam %>%
filter(class %in% c(1,3,5))
# 조건에 맞는 행을 데이터로 저장
class135 <- exam %>%
filter(class == 1 | class == 3 | class == 5)
class135
# 1반만 추출하여 저장
class1 <- exam %>%
filter(class == 1)
# 3반만 추출하여 저장
class3 <- exam %>%
filter(class == 3)
class1;class3
# 각 반의 수학 평균 점수
mean(class1$math)
mean(class3$math)
#
# 산술연산자
# 더하기
3+4
# 나누기의 몫
4%/%2
5%/%2
# 나누기의 나머지
4%%2
5%%23) 실습 문제
# mpg 데이터를 이용해 분석 문제를 해결해 보세요.
# • Q1. 자동차 배기량에 따라 고속도로 연비가 다른지 알아보려고 합니다. displ(배기량)이 4 이하인 자동차와 5 이상인 자동차 중 어떤 자동차의 hwy(고속도로 연비)가 평균적으로 더 높은지 알아보세요.
# 독립표본 t검정
mpg <- as.data.frame(ggplot2::mpg)
mpg_4 <- mpg %>% filter(mpg$disp <= 4)
mpg_5 <- mpg %>% filter(mpg$disp >= 5)
mean(mpg_4$hwy)
mean(mpg_5$hwy)
# • Q2. 자동차 제조 회사에 따라 도시 연비가 다른지 알아보려고 합니다. "audi"와 "toyota" 중 어느 manufacturer(자동차 제조 회사)의 cty(도시 연비)가 평균적으로 더 높은지 알아보세요.
mpg_audi<- mpg %>% filter(mpg$manufacturer == "audi")
mpg_toyota <- mpg %>% filter(mpg$manufacturer == "toyota")
mean(mpg_audi$cty)
mean(mpg_toyota$cty)
# • Q3. "chevrolet", "ford", "honda" 자동차의 고속도로 연비 평균을 알아보려고 합니다. 이 회사들의
# 자동차를 추출한 뒤 hwy 전체 평균을 구해보세요
mpg_all <-mpg %>% filter(mpg$manufacturer %in% c("chevrolet","ford","honda"))
mpg_all
mean(mpg_all$hwy)5) 파이프라인을 통해 필터, 셀렉 기능 사용하기
# 열 = 변수 추출
head(exam)
exam %>%
select(math)
# 변수 여러 개 추출
exam %>%
select(math,english,science)
# 특정 변수 제외하고 추출
exam %>%
select(-id,-math)
# 변수를 추출하여 저장
score <- exam %>%
select(math,english,science)
score
# 행과 열을 동시에 추출
exam %>%
filter() %>%
select()
c3_science <- exam %>%
filter(class == 3) %>%
select(science)
# 데이터 앞부분만 빠 르게 조회하고 싶을 때
exam %>%
filter() %>%
select()
# 3개의 행만 보기
exam %>%
filter(class %in% c(1,3,5)) %>%
select(english,science) %>%
head(3)
# 기본값 = 6개 행 보기
exam %>%
filter(class %in% c(1,3,5)) %>%
select(english,science) %>%
head
exam %>%
filter(class %in% c(1,3,5)) %>%
select(english,science) %>%
head()6) 문제풀기 (filter, select 사용)
# mpg 데이터를 이용해서 분석 문제를 해결해보세요.
# • Q1. mpg 데이터는 11 개 변수로 구성되어 있습니다. 이 중 일부만 추출해서 분석에 활용하려고 합니다. mpg
# 데이터에서 class(자동차 종류), cty(도시 연비) 변수를 추출해 새로운 데이터를 만드세요. 새로 만든데이터의 일부를 출력해서 두 변수로만 구성되어 있는지 확인하세요.
mpg <- as.data.frame(ggplot2::mpg)
mpg_class_cty<- mpg %>%
filter() %>%
select(class,cty)
head(mpg_class_cty)
# • Q2. 자동차 종류에 따라 도시 연비가 다른지 알아보려고 합니다. 앞에서 추출한 데이터를 이용해서 class(자동차 종류)가 "suv"인 자동차와 "compact"인 자동차 중 어떤 자동차의 cty(도시 연비)가 더 높은지 알아보세요
# 독립표본 t검정
suv<- mpg %>%
filter(class == "suv")
compact<- mpg %>%
filter(class == "compact")
mean(suv$cty)
mean(compact$cty)
7) 순서대로 정렬
# 정렬하기
# 오름차순 = 낮은 값에서 높은 값으로 정렬
exam %>%
arrange(id)
exam %>%
arrange(math)
# 내림차순 = 높은 값에서 낮은 값으로 정렬
exam %>%
arrange(desc(math))
# 변수 여러개로 정렬
exam %>%
arrange(class,science)
exam %>%
arrange(class,desc(math))mpg 데이터를 이용해서 분석 문제를 해결해보세요. • "audi"에서 생산한 자동차 중에 어떤 자동차 모델의 hwy(고속도로 연비)가 높은지 알아보려고 합니다. "audi"에서 생산한 자동차 중 hwy가 1~5위에 해당하는 자동차의 데이터를 출력하세요.
7) 순서대로 정렬 실습 문제
# mpg 데이터를 이용해서 분석 문제를 해결해보세요.
# • "audi"에서 생산한 자동차 중에 어떤 자동차 모델의 hwy(고속도로 연비)가 높은지 알아보려고 합니다.
# "audi"에서 생산한 자동차 중 hwy가 1~5위에 해당하는 자동차의 데이터를 출력하세요
mpg <- as.data.frame(ggplot2::mpg)
head(mpg)
audi<- mpg %>%
filter(manufacturer == "audi")
top_audi<- audi %>%
arrange(desc(hwy)) %>%
head(5)
8) 파생변수 추가하기
# 새로운 변수 생성
# 변수 하나
str(exam)
exam %>%
mutate(score_sum = math + english + science)
str(exam)
# 변수 2개
exam %>%
mutate(score_sum = math + english + science,
score_mean = (math + english + science)/3
)
exam %>%
mutate(score_sum = math + english + science,
score_mean = score_sum/3
)
exam %>%
mutate(score_sum = math + english + science,
score_mean = score_sum/3
)
# 범주형 변수 만들기
a <- exam %>%
mutate(math_test = ifelse(math >= 80, "pass", "fail"))
a
a %>%
filter(math_test == "pass")
# 새로 만든 변수를 이용해서 바로 함수에 적용
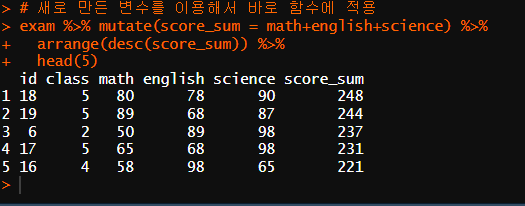
exam %>% mutate(score_sum = math+english+science) %>%
arrange(desc(score_sum)) %>%
head(5)
9) 문제풀이 - mutate 활용
# 문제풀이
# mpg 데이터를 이용해서 분석 문제를 해결해보세요.
# mpg 데이터는 연비를 나타내는 변수가 hwy(고속도로 연비), cty(도시 연비) 두 종류로 분리되어 있습니다. 두 변수를 각각 활용하는 대신 하나의 통합 연비 변수를 만들어 분석하려고 합니다.
# • Q1. mpg 데이터 복사본을 만들고, cty 와 hwy 를 더한 '합산 연비 변수'를 추가하세요.
mpg<- as.data.frame(ggplot2::mpg)
mpg_copy <- mpg
mpg_copy<- mpg_copy %>%
mutate(sum_cty_hwy = cty+hwy)
# • Q2. 앞에서 만든 '합산 연비 변수'를 2 로 나눠 '평균 연비 변수'를 추가세요.
mpg_copy<- mpg_copy %>%
mutate(mean_cty_hwy = sum_cty_hwy/2)
# • Q3. '평균 연비 변수'가 가장 높은 자동차 3 종의 데이터를 출력하세요.
mpg_copy %>%
mutate(mean_cty_hwy = sum_cty_hwy/2) %>%
arrange(desc(mean_cty_hwy)) %>%
head(3)
# • Q4. 1~3 번 문제를 해결할 수 있는 하나로 연결된 dplyr 구문을 만들어 출력하세요. 데이터는 복사본 대신 mpg 원본을 이용하세요
mpg %>%
mutate(sum_cty_hwy = cty+hwy,
mean_cty_hwy = sum_cty_hwy/2,
) %>%
arrange(desc(mean_cty_hwy)) %>%
head(3)

10) 집단별 요약 - group-by
# 요약하기
exam %>%
summarise(math_mean = mean(math),
english_mean = mean(english),
science_mean = mean(science))
# 그룹별로 요약하기(분석시 anova 분석)
exam %>%
group_by(class) %>%
summarise(math_mean = mean(math),
english_mean = mean(english),
science_mean = mean(science))
# 다른 요약 통계량
exam %>%
group_by(class) %>%
summarise(science_mean = mean(science),
science_sum = sum(science),
science_median = median(science),
science_frequency = n())
# 제조 회사와 구동 방식 별로 고속도로 연비 평균 값
mpg %>%
group_by(manufacturer,drv) %>%
summarise(hwy_mean = mean(hwy))
# 중복제거
mpg %>%
group_by(manufacturer,drv) %>%
summarise(hwy_mean = mean(hwy))
# 추가한거
mpg %>%
group_by(manufacturer,drv) %>%
mutate(hwy_mean = mean(hwy))
head(mpg)
* 핵심
- 데이터 불러오기
- 파이프라인 활용법
- 조건식 사용
'배운 책들 정리 > 만만한 통계 : R 활용' 카테고리의 다른 글
| 0228 만만한 통계 R 외부 챕터 8~9 - 그래프 만들기, 데이터 분석 프로젝트 (0) | 2023.02.28 |
|---|---|
| 0227 만만한 통계 R 외부 챕터 6~8 - 데이터 추출, 데이터 합치기, 데이터 정제, 그래프 (0) | 2023.02.27 |
| 0223 만만한 통계 R 외부 챕터 15 - 내장 함수, 변수 타입과 데이터 구조 // 기초 문제 연습 (0) | 2023.02.23 |
| 0222 만만한 통계 R - 카이제곱 검정과 기타 비모수 검정 (CP19) (0) | 2023.02.22 |
| 0221 만만한 통계 R - 선형회귀, 단순회귀, 다중회귀 (18) (0) | 2023.02.21 |



