PART 6
CP19
1) 단일표본 카이제곱 검정
- 독립성검정 : 두 변수와 관련이 있는지 여부 확인 (야채를 먹는 것과 건강이 관련이 있는가)
- 동질성검정 : 두 개 이상의 그룹이 서로 유사하거나 다른지 확인하기 위함 (서로 다른 반의 학생들 성적이 비슷한지)
- 적합성 검정 : 데이터 샘플이 특정 분포를 가진 모집단에 나온 것인지 확인 (학생 표본이 전체 학교 인구를 대표하는지)
- 단일표본 카이제곱 검정 :범주형 변수의 관측 빈도를 기대 빈도와 비교하는 통계 검정을 의미함.
범주형 데이터 분포가 모두 동일할 경우 예상되는 분포와 다른가요의 질문과 같음
예측 빈도와 관측 빈도를 비교하는 방법 (예측과 실제 실험 시 차이가 있는지)
2) 카이제곱 검정통계량
카이제곱 검정통계량 식 : x^2 = sum(O-E)^2 / E
x^2 : 카이제곱값
O : 관측된 빈도수
E : 예상된 빈도수
3) 실습
# C19
# 카이제곱 검정
options(scipen = 99)
# 적합도검정
# 관찰빈도 = observed frequency
of <- c(23,17,50)
# 기대빈도 = expected frequency
# 빈도의 총합/그룹의 수
ef <- sum(of)/length(of)
ef
# 카이제곱검정통계량
# O - E
of-ef
# (O-E)^2
(of-ef)^2
# (O-E)^2/E
((of-ef)^2)/ef
# (O-E)^2/E의 합
chi <- sum((of-ef)^2)/ef
# 임계값, 유의수준, 자유도
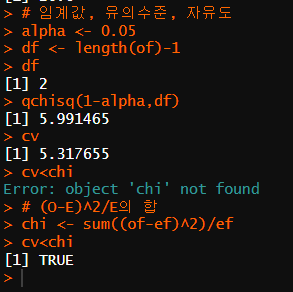
alpha <- 0.05
df <- length(of)-1
df
qchisq(1-alpha,df)
cv
cv<chi
#True = 귀무가설 기각
1-pchisq(chi,df)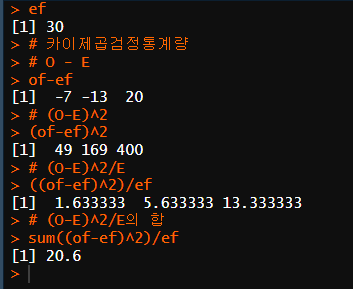

4) 독립성 카이제곱 검정
독립성 카이제곱 검정 : 두 범주형 변수가 서로 관련이 있는지 또는 독립적인지 확인하는데 사용 되는 통계 방법
(서로 다른 두 그룹의 사물 사이에 관계가 있는지 확인)
관측 빈도와 예측 빈도와 비교해 검정하는 것. 만약 유의미한 차이가 있는 경우 두 변수가 독립적이지 않고
둘 사이에 관계가 있다는 결론을 내릴 수 있음.
5) 독립성 카이제곱 검정 계산
기대빈도 : (특정 행열의 곱) / 총빈도(모든행열을 더한 값)
카이 제곱 검정통계량 : sum((관측빈도-예상빈도)^2 / 예상빈도)
6) 실습
# 독립성 검정
# row = 투표참여여부
# col = 성별
row1 <- c(37,32)
row2 <- c(20,31)
col1 <- c(37,20)
col2 <- c(32,31)
# 행 합계
r1 <- sum(row1)
r2 <- sum(row2)
r1;r2
# 열 합계
c1 <- sum(col1)
c2 <- sum(col2)
c1;c2
# 총 빈도
total <- sum(row1,row2)
total
# 기대 빈도
e11 <- (r1*c1)/total
e12 <- (r1*c2)/total
e21 <- (r2*c1)/total
e22 <- (r2*c2)/total
e11;e12;e21;e22
# 검정통계량 카이제곱값
# (O - E)^2/E의 합
chi <- sum((row1[1] - e11)^2/e11,
(row1[2] - e12)^2/e12,
(row2[1] - e21)^2/e21,
(row2[2] - e22)^2/e22)
# 임계값, 유의수준, 자유도
alpha <- 0.05
df <- length(of)-1
df
qchisq(1-alpha,df)
cv
cv<chi
#False = 귀무가설 채택
# 유의확률
p <- 1-pchisq(chi,df)
p
alpha >p
# flase = 귀무가설 채택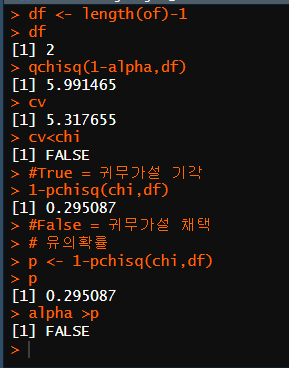
7) 실습2
data <- read.csv("./Syntax(R)/19/ch19ds1.csv")
head(data)
str(data)
# 빈도표
cross_table <- table(data$Voucher)
# 비율
prop.table(table(data$Voucher))
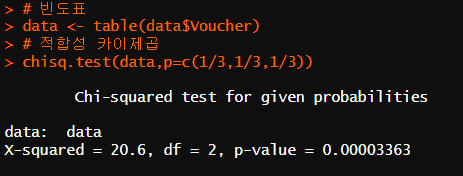
# 적합성 카이제곱
chisq.test(cross_table,p=c(1/3,1/3,1/3))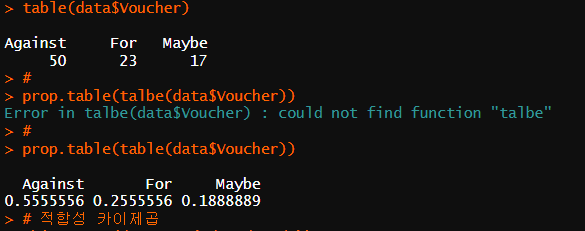
8) 실습3
# 실습3
data <- read.csv("./Syntax(R)/19/ch19ds2.csv")
head(data)
str(data)
# 빈도표
cross_table <-table(data$Vote, data$Sex)
# 비율
prop.table(table(data$Vote, data$Sex))
# 적합성 카이제곱
chisq.test(cross_table,p=c(1/4,1/4,1/4), correct = F)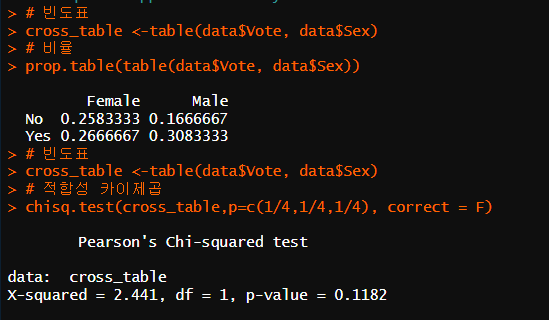
9) 보건의료문제
# 보건의료문제 해결 실습
# 독립성 카이제곱 검정
options(scipen = 99)
# 데이터 준비
library(readxl)
data <- read_excel("./SpyderBD_01/data/sta_data.xlsx", sheet = "chi_p")
head(data)
str(data)
# 교차표
cross_table <- table(data)
cross_table
# 열 합계
addmargins(cross_table,1)
# 비율
prop.table(addmargins(cross_table,1),2)
#
install.packages("gmodels")
library(gmodels)
CrossTable(x = data$dizziness, y= data$obesity, chisq = TRUE)
* 핵심
카이제곱 = 독립성검정(두 변수가 독립적인지 아닌지 파악하는)
'배운 책들 정리 > 만만한 통계 : R 활용' 카테고리의 다른 글
| 0224 만만한 통계 R 외부 챕터 4~6 - 데이터 프레임, 데이터 분석, 데이터 가공 (1) | 2023.02.24 |
|---|---|
| 0223 만만한 통계 R 외부 챕터 15 - 내장 함수, 변수 타입과 데이터 구조 // 기초 문제 연습 (0) | 2023.02.23 |
| 0221 만만한 통계 R - 선형회귀, 단순회귀, 다중회귀 (18) (0) | 2023.02.21 |
| 0220 만만한 통계 R - 상관계수 계산 및 유의성 검정, 보건의료(7,17) (0) | 2023.02.20 |
| 0217 만만한 통계 R - 평균 차이 검정, 분산분석(ANOVA)(14,15) (1) | 2023.02.17 |



