0 지난 시간 복습
범주형 : 빈도표 (이상치 확인 후 결측치로 바꾸기)
연속형(최소,최대,평균,중앙값) : 요악통계
1 그래프 만들기 CP 8
1) 그래프 종류 1
- 산점도 : 변수 사이의 상관 관계를 확인
- 히스토그램 (연속형 변수) : 단일 변수의 분포를 보여주는 그래프. (데이터 모양과 산포를 식별하는데 도움이 됨)
(데이터를 간격으로 나눠 그래프의 막대는 각 간격의 관측치 수를 나타냄)
- 선그래프 : 시간 또는 기타 연속 간격에 따른 두 변수 간의 관계를 보여줌. 데이터 추세 또는 패턴을 파악하는데 용이함.
(시간 경과에 따라 데이터가 어떻게 변하는지)
- 상자수염그림 : 단일 변수의 데이터 범위, 중앙값, 사분위수 범위(IQR)을 보여줌. 상자는 중앙값을 나타냄.위스커는 데이터의 최소값과 최대값 또는 사용자가 정의한 특정 범위까지 확장됨.
*각각의 특징 요약
히스토그램은 빈도를 표시하는 데 유용합니다.
상자 및 수염 그림은 데이터의 분포를 보여주고 이상값을 식별하는 데 적합합니다.
반면에 선 그래프는 변수가 시간 또는 기타 연속 간격에 따라
어떻게 변하는지 보여주고 데이터의 추세를 식별하는 데 유용합니다.
* 위스커 : 상자 및 수염 플롯에서 확장되는 선을 의미함 (이상치에 해당 됨)
2) ggplot2 레이어 구조 이해하기 - 실습 1
# 그래프
library(ggplot2)
# 산점도
mpg <- as.data.frame(ggplot2::mpg)
ggplot(data=mpg, aes(x=displ, y=hwy))+ #배경 설정
geom_point() # 기하학적 객체 설정 = 무엇을 그릴지 결정
# 꾸미기
3) x,y축 조정, xy축 조정
# x축 조정
ggplot(data=mpg, aes(x=displ, y=hwy))+ #배경 설정
geom_point() + # 기하학적 객체 설정 = 무엇을 그릴지 결정
xlim(3,6)
# 경고메시지 : 명령어가 실행되므로 무시해도 괜찮음, 하지만 참고해야 됨 = 그림에 표현 되지 않은 데이터가 있다는 내용
# y축 조정
ggplot(data=mpg, aes(x=displ, y=hwy))+ #배경 설정
geom_point() + # 기하학적 객체 설정 = 무엇을 그릴지 결정
ylim(20,40)
# x,y축 조정
ggplot(data=mpg, aes(x=displ, y=hwy))+ #배경 설정
geom_point() + # 기하학적 객체 설정 = 무엇을 그릴지 결정
xlim(3,6) +
ylim(20,40)



4) 문제 - xy축 조건식
# mpg 데이터와 midwest 데이터를 이용해서 분석 문제를 해결해 보세요.
# • Q1. mpg 데이터의 cty(도시 연비)와 hwy(고속도로 연비) 간에 어떤 관계가 있는지 알아보려고 합니다.x 축은 cty, y 축은 hwy 로 된 산점도를 만들어 보세요.
mpg <- (ggplot2::mpg)
ggplot(data = mpg, aes(x=mpg$cty, y=mpg$hwy))+
geom_point()
# 우상향 곡선
# 상관계수
cor(mpg$cty, mpg$hwy)
# 상관분석
cor.test(mpg$cty, mpg$hwy)
# • Q2. 미국 지역별 인구통계 정보를 담은 ggplot2 패키지의 midwest 데이터를 이용해서 전체 인구와 아시아인 인구 간에 어떤 관계가 있는지 알아보려고 합니다. x 축은 poptotal(전체 인구), y 축은 popasian(아시아인 인구)으로 된 산점도를 만들어 보세요. 전체 인구는 50 만 명 이하, 아시아인 인구는 1 만 명 이하인 지역만 산점도에 표시되게 설정하세요
midwest <- (ggplot2::midwest)
ggplot(data = midwest, aes(x=poptotal, y=popasian))+
geom_point() +
xlim(0,500000) +
ylim(0,10000)

# 상관계수
cor(midwest$poptotal,midwest$popasian)
# 상관분석
cor.test(midwest$poptotal,midwest$popasian)
5) 막대 그래프 - 집단 간 차이 표현하기
- 빈도분석 (범주형 데이터) geom_bar : 카이제곱의 차이 (두 범주 데이터 세트 간의 차이를 분석)
- 빈도가 아닌 다른 값 (t검정) geom_col : 평균의 차이 (이를 통해 그룹 간에 상당한 차이가 있는지 확인하여 기본 모집단에 대한 결론을 도출함)
6) 막대 그래프 실습
# 막대 그래프
# 데이터 준비
mpg <- as.data.frame(ggplot2::mpg)
# drv = 범주형 변수 => 빈도표
table(mpg$drv)
# 빈도 막대그래프 = 막대의 높이가 곧 빈도
ggplot(data = mpg, aes(x = drv))+
geom_bar()
# cty = 연속형 변수 => 요약통계
summary(mpg$cty)
# 히스토그램
ggplot(data = mpg, aes(x = cty))+
geom_bar()
# 구간 수 설정(기본값이 30)
ggplot(data = mpg, aes(x = cty))+
geom_bar(bins = 15)
# 빈도가 아닌 다른 값으로 막대그래프 그리기
# 데이터 전처리
library(tidyverse)
drv_hwy <- mpg %>%
group_by(drv) %>%
summarise(hwy_mean=mean(hwy))
drv_hwy
# 평균값으로 막대 그래프
ggplot(data=drv_hwy, aes(x=drv, y=hwy_mean))+
geom_col()


6) 막대 그래프 실습 2
# 막대 순서 조정
# 오름차순
ggplot(data=drv_hwy, aes(x=reorder(drv, hwy_mean), y=hwy_mean))+
geom_col()
# 내림차순
ggplot(data=drv_hwy, aes(x=reorder(drv, -hwy_mean), y=hwy_mean))+
geom_col()+
xlab("drv") #x축 제목 설정
7) 막대 그래프 실습 문제
# mpg 데이터를 이용해서 분석 문제를 해결해 보세요.
# • Q1. 어떤 회사에서 생산한 "suv" 차종의 도시 연비가 높은지 알아보려고 합니다. "suv" 차종을 대상으로 평균 cty(도시 연비)가 가장 높은 회사 다섯 곳을 막대 그래프로 표현해 보세요. 막대는 연비가 높은 순으로 정렬하세요.
mpg <- as.data.frame(ggplot2::mpg)
df <- mpg %>%
filter(class == "suv") %>%
group_by(manufacturer) %>%
summarise(mean_cty=mean(cty)) %>%
arrange(desc(mean_cty)) %>%
head(5)
# 만든 데이터를 기반으로 막대 그래프 그리기
ggplot(data = suv_cty, aes(x=reorder(manufacturer, -cty_mean), y=cty_mean)) +geom_col()
# ggplot 사용 시 기본적으로 정렬 시 알파벳 순으로 정렬해줌
ggplot(data = df, aes(x=reorder(manufacturer, -mean_cty), y=mean_cty)) +geom_col()+
xlab("manufacturer")+
ylab("mean_cty")
# • Q2. 자동차 중에서 어떤 class(자동차 종류)가 가장 많은지 알아보려고 합니다. 자동차 종류별 빈도를 표현한 막대 그래프를 만들어 보세요
# 빈도표 작성
table(mpg$class)
# 빈도 막대 그래프
ggplot(data = mpg, aes(x = class))+
geom_bar()



8) 선 그래프
# 선그래프
economics <- as.data.frame(ggplot2::economics)
str(economics)
# 실업자 수로 선 그래프 그리기
# unemploy = number of unemployed in thousands
ggplot(data = economics, aes(x=date, y= unemploy))+
geom_line()
# pce = personal consumption expenditures, in billions of dollars
ggplot(data = economics, aes(x = date, y = pce))+
geom_line()
# pop = total population, in thousands // 소비양이 많아진다.
ggplot(data = economics, aes(x = date, y = pop))+
geom_line()


9) 문제 1
# economics 데이터를 이용해서 분석 문제를 해결해 보세요.
# • Q1. psavert(개인 저축률)가 시간에 따라서 어떻게 변해왔는지 알아보려고 합니다. 시간에 따른 개인 저축률의 변화를 나타낸 시계열 그래프를 만들어 보세요
economics <- as.data.frame(ggplot2::economics)
str(economics)
# psavert = personal savings rate
ggplot(data = economics, aes(x=date, y= psavert))+
geom_line()
# 상자그림 = 상자수염그림
mpg <- as.data.frame(ggplot2::mpg)
# 구동방식 별로 도시 연비가 어떻게 다른지에 대해서 상자그림으로 확인
ggplot(data = mpg, aes(x = drv, y = cty))+
geom_boxplot()
# 이상치 확인
boxplot(mpg$hwy)$stats
# 12보다 작거나, 37보다 크면 이상치로 판단


10) 문제 2
# mpg 데이터를 이용해서 분석 문제를 해결해 보세요.
# • Q1. class(자동차 종류)가 "compact", "subcompact", "suv"인 자동차의 cty(도시 연비)가 어떻게 다른지 비교해보려고 합니다. 세 차종의 cty를 나타낸 상자 그림을 만들어보세요.
mpg <- as.data.frame(ggplot2::mpg)
# class(자동차 종류)가 "compact", "subcompact", "suv"인 자동차 추출
css <- mpg %>%
filter(class %in% c("compact", "subcompact", "suv"))
ggplot(data = css, aes(x = class, y = cty))+
geom_boxplot()
#
2 데이터 분석 프로젝트 CP9
1) 분석 준비하기
- 한국복지패널데이터
- 건강보험청구(전국민건강보험)
- 국민건강영양조사
- 의료패널
- 가구조사 (가구원)
2) 분석 실습 - 로드 및 이름 변경
# 데이터 분석 프로젝트
# SPSS 파일 열기 위한 패키지 설치
install.packages("foreign")
library(foreign)
raw_data <- read.spss("./SpyderBD_01/data/Koweps_hpc10_2015_beta1.sav", to.data.frame = T)
# 데이터 전처리 과정 중에 데이터에 문제가 생기면
# 여기서부터 다시 시작
data <- raw_data
# 데이터 살펴보기
# View(data)
# 분석에서 사용할 변수 추출
welfare <- data %>%
select(h10_g3,
h10_g4,
h10_g10,
h10_g11,
h10_eco9,
p1002_8aq1,
h10_reg7
)
head(welfare)
# 변수 이름 변경
welfare <- rename(welfare,
sex = h10_g3,
birth_year = h10_g4,
marital_status = h10_g10,
religion = h10_g11,
job_code = h10_eco9,
income = p1002_8aq1,
rgion = h10_reg7)
head(welfare)
# 데이터 준비 완료
2) 데이터 분석 절차 - 첫번째 주제 (성별에 따른 월급 차이)
# 데이터 분석 절차
# 1. 데이터 분석 주제 설정
# 2. 주제에 필요한 변수 검토, 전처리 = 결측치, 이상치
# 3. 변수 간 관계 분석
# 첫번째 주제 : 성별에 따른 월급 차이
# 1. 성별에 따른 월급 차이가 있는지
# 2. 성별, 월급 변수 검토
# 3. 성별과 월급의 관계 분석
# 성별 변수 검토 = 범주형 변수 = 빈도
# 이상치, 결측치 확인
# 이상치 없음
table(welfare$sex)
# 결측치 없음
table(is.na(welfare$sex))
# 월급 변수 검토 = 연속형 변수 = 요약통계
summary(welfare$income)

3) 결측치 NA 변경, 독립표본 t검정, 등분산 가정
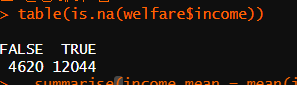
# 이상치는 월급이 없는 사람 = 0 이라는 값을 가진 사람 제외 => 결측치 NA로 변경해야 함
table(is.na(welfare$income))
# 현재 결측치 12030개
welfare$income <- ifelse(welfare$income == 0, NA, welfare$income)
table(is.na(welfare$income))
# 현재 결측치 12044개 = 14개 추가된 것을 확인 가능
# 성별에 따른 월급 평균값 데이터가 필요함
sex_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(sex) %>%
summarise(income_mean = mean(income))
sex_income
# 평균 값을 가진 막대그래프 그리기
ggplot(data = sex_income, aes(x = sex, y = income_mean))+
geom_col()
# 독립표본 t검정, 등분산 가정
sex_income_t <- welfare %>%
filter(!is.na(income))
sex_income_t
t.test(welfare$income ~ welfare$sex, var.equal = T)
#




4) 데이터 분석 절차 - 두번째 주제 (나이에 따른 월급의 차이)
# 두번째 주제 : 나이에 따른 월급의 차이
# 1. 나이에 따른 월급 차이가 있는가?
# 2. 나이, 월급 변수 검토
# 3. 나이와 월급의 관계 분석
# 나이 = 2015 - 출생연도 + 1
head(welfare)
welfare$age <- 2015 - welfare$birth_year + 1
summary(welfare$birth_year)
summary(welfare$age)
# 이상치 없음
table(is.na(welfare$age))
table(is.na(welfare$birth_year))
# 결측치 없음

4) 데이터 분석 절차 - 세번째 주제 가기 전 (나이에 따른 월급 평균값)
# 나이에 따른 월급 평균값 데이터가 필요함
age_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(age) %>%
summarise(income_mean = mean(income))
age_income
# 나이에 따른 월급 평균값의 변화를 보여주는 선그래프 그리기
ggplot(data = age_income, aes(x=age, y= income_mean))+
geom_line() # 안되는 이유!!!! (income_mean이라고 안씀)

5) 데이터 분석 절차 - 세번째 주제 (연령대와 월급의 관계 분석)
# 세번째
# 2. 연령대, 월급 변수 검토
# 3. 연령대와 월급의 관계 분석
# 연령대 변수 검토
# 나이 변수를 연령대 변수로 변환
# < 30: young, <60 : middle, >= 60 : old
welfare$age_group <- ifelse(welfare$age < 30, "young",
ifelse(welfare$age < 60, "middle","old"))
table(welfare$age_group)
# age 변수 검토할 때, 이상치와 결측치가 없었기 때문에 문제 없음
# 연령대에 따른 월급 평균값 데이터가 필요
age_group_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(age_group) %>%
summarise(income_mean = mean(income))
age_group_income
# 연령대에 따른 월급 평균값을 보여주는 막대 그래프 그리기
ggplot(data = age_group_income, aes(x=age_group, y= income_mean))+
geom_col()
# 연령대 순서 변경
ggplot(data = age_group_income, aes(x =age_group, y= income_mean))+
geom_col()+
scale_x_discrete(limits = c("young","middle","old"))



5) 데이터 분석 절차 - 네번째 주제 (연령대와 성별에 따른 월급의 차이)
# 네번째 주제: 연령대와 성별에 따른 월급의 차이
# 1. 연령대와 성별에 따른 월급 차이가 있는가?
# 2. 연령대와 성별, 월급 변수 검토
# 3. 연령대와 성별, 월급의 관계 분석
# 변수 검토는 앞선 분석에서 모두 완료하였음
# 연령대와 성별에 따른 월급 평균값 데이터가 필요
age_group_sex_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(age_group, sex) %>%
summarise(income_mean = mean(income))
age_group_sex_income
# 연령대와 성별에 따른 월급 평균값을 보여주는 막대그래프 만들기
# 누적 막대 그래프
ggplot(data = age_group_sex_income, aes(x = age_group, y = income_mean, fill = sex))+
geom_col()+
scale_x_discrete(limits = c("young", "middle", "old"))
# 막대를 나란히 세워서 표현하기
ggplot(data = age_group_sex_income, aes(x = age_group, y = income_mean, fill = sex))+
geom_col(position = "dodge")+
scale_x_discrete(limits = c("young", "middle", "old"))
#

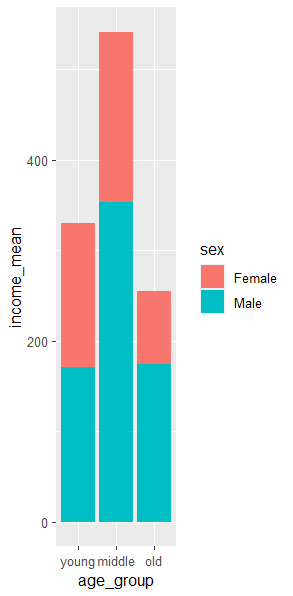

* 핵심 (함수 정리)
- ggplot(data=a, aes(x=,y=)) + geom_~~ : 그래프 생성 함수
- geom_point : 산점도
- ylim(n1,n2) : n1부터 n2까지의 y축 범위 표현
- aes(x=,y=) : x,y축 데이터 지정
- options(scipen = 99) : 자릿수 지정 표현법 (기본적인)
- cor() : 상관계수
- cor.test() : 상관분석
- geom_col() : 막대 그래프 (이미 요약된 데이터를 통해 요약 통계 값을 나타낼 때)
ggplot(data=drv_hwy, aes(x=drv, y=hwy_mean))+
geom_col()- geom_bar() : 빈도 막대 그래프 (원시 형식의 데이터를 요약할 때 주로 사용)
ggplot(data = mpg, aes(x = drv))+
geom_bar()- xlab(" ") : x축 제목 설정
- geom_histogram(bins =10) : 구간수 10으로 설정하여 히스토그램 그래프 확인
- reorder(a,b) : b를 기준으로 a를 나타냄 (-b사용시 내림차순으로 정렬)
- geom_boxplot : 상자수염 그래프
- boxplot(mpg$hwy)$stats : 이상치 확인
- read.spss(경로, to.data.frame = T) : spss 형식의 데이터 불러오기
- rename(a=b) : 기존에 있는 b의 이름을 a로 변경
- geom_line() : 선형 그래프
- ifelse(조건, 부여, 조건2, 부여) : 조건식 부여
예시) ifelse(welfare$age < 30, "young",
ifelse(welfare$age < 60, "middle","old"))- scale_x_discrete(limits = c("a","b","c")) : x축의 이름 순서를 a,b,c로 조정
'배운 책들 정리 > 만만한 통계 : R 활용' 카테고리의 다른 글
| 0303 만만한 통계 R 외부 챕터 11~14 - 지도 시각화, 인터랙티브 그래프, 통계분석 가설 검정, R markdown (1) | 2023.03.03 |
|---|---|
| 0302 만만한 통계 R 외부 챕터 9~10 - 데이터 분석 프로젝트 2, 텍스트 마이닝 (0) | 2023.03.02 |
| 0227 만만한 통계 R 외부 챕터 6~8 - 데이터 추출, 데이터 합치기, 데이터 정제, 그래프 (0) | 2023.02.27 |
| 0224 만만한 통계 R 외부 챕터 4~6 - 데이터 프레임, 데이터 분석, 데이터 가공 (1) | 2023.02.24 |
| 0223 만만한 통계 R 외부 챕터 15 - 내장 함수, 변수 타입과 데이터 구조 // 기초 문제 연습 (0) | 2023.02.23 |



