0. 지난 시간 복습
1) 핵심
통계를 하는 이유는 유의성 검정을 위해 (제대로 된 분석인지)
1. 나이 및 성별 월급 차이 분석하기
1) 다섯번째 주제 : 나이와 성별에 따른 월급의 차이
# 3월2일
# 다섯번째 주제 : 나이와 성별에 따른 월급의 차이
# 1. 나이와 성별에 따른 월급 차이가 있는가?
# 2. 나이와 성별, 월급 변수 검토
# 3. 나이와 성별, 월급의 관계 분석
# 변수 검토는 앞선 분석에서 모두 완료하였음
# 나이와 성별에 따른 평균 월급 데이터가 필요함
age_sex_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(age,sex) %>%
summarise(income_mean = mean(income))
age_sex_income
# 나이와 성별에 따른 평균 월급 선 그래프 그리기
# x 연속형 범주가 나와야 함 (문자)
ggplot(data = age_sex_income, aes(x=age , y=income_mean, col=sex)) + geom_line()
사실 남성에 의해 패턴이 많이 묻혔음. (특정 기점까지는 비슷하지만 이후부터 벌어진 것이기에)
2) 여섯번째 주제 : 직업에 따른 월급의 차이
# 여섯번째 주제 : 직업에 따른 월급의 차이
# 1. 직업에 따른 월급 차이가 있는가?
# 2. 직업, 월급 변수 검토
# 3. 직업과 월급의 관계 분석
# 직업 변수 검토 = 범주형 변수 = 빈도표
str(welfare)
table(welfare$job_code)
# 직종코드와 직종 이름 데이터 합치기
# 직종 이름 데이터 불러오기
library(readxl)
job_name <- read_excel("./SpyderBD_01/data/guro_01/SpyderBD_01/data/Koweps_Codebook.xlsx", sheet=2)
head(job_name)
# welfare 데이터의 job_code와 job_name 데이터의 code_job으로 합치기
# 여기서 by.x는 조인을 해주는 역할
welfare <- merge(welfare, job_name, by.x = "job_code", by.y = "code_job", all.x= T )
head(welfare)
# 직종 이름 변수 = 범주형 변수 = 빈도표
table(welfare$job)
# 이상치 없음
table(is.na(welfare$job))
table(is.na(welfare$job_code))
# 결측치 9135개 = 분석시 제외
# 직업에 따른 평균 월급 데이터가 필요함
job_income <- welfare %>%
filter(!is.na(job) & !is.na(income)) %>%
group_by(job) %>%
summarise(income_mean = mean(income))
job_income
# 상위 10개 직업
top_10<- job_income %>%
arrange(desc(income_mean)) %>%
head(10)
# 막대그래프 그리기
ggplot(data=top_10, aes(x=job, y=income_mean)) +
geom_col()
# x축의 직업 이름이 겹쳐서 축 전환해야 함
ggplot(data=top_10, aes(x=job, y=income_mean)) +
geom_col() +
coord_flip()
# 직업 이름 막대 순서를 내림차순으로 변경 // 사용
# 축이 전환되면 기능도 바뀜
ggplot(data=top_10, aes(x=reorder(job, income_mean), y=income_mean)) +
geom_col() +
coord_flip()
# 직업 이름 막대 순서를 오름차순으로 변경 // 참고용
ggplot(data=top_10, aes(x=reorder(job, -income_mean), y=income_mean)) +
geom_col() +
coord_flip()
# 하위 10개 직업
bottom_10<- job_income %>%
arrange((income_mean)) %>%
head(10)
# 막대그래프 그리기
ggplot(data=bottom_10, aes(x=job, y=income_mean)) +
geom_col()
# x축의 직업 이름이 겹쳐서 축 전환해야 함
ggplot(data=bottom_10, aes(x=job, y=income_mean)) +
geom_col() +
coord_flip()
# 직업 이름 막대 순서를 내림차순으로 변경 // 사용
# 축이 전환되면 기능도 바뀜
ggplot(data=top_10, aes(x=reorder(job, -income_mean), y=income_mean)) +
geom_col() +
coord_flip()엑셀 불러오기
조인
이상치 확인

상위 10개 직업
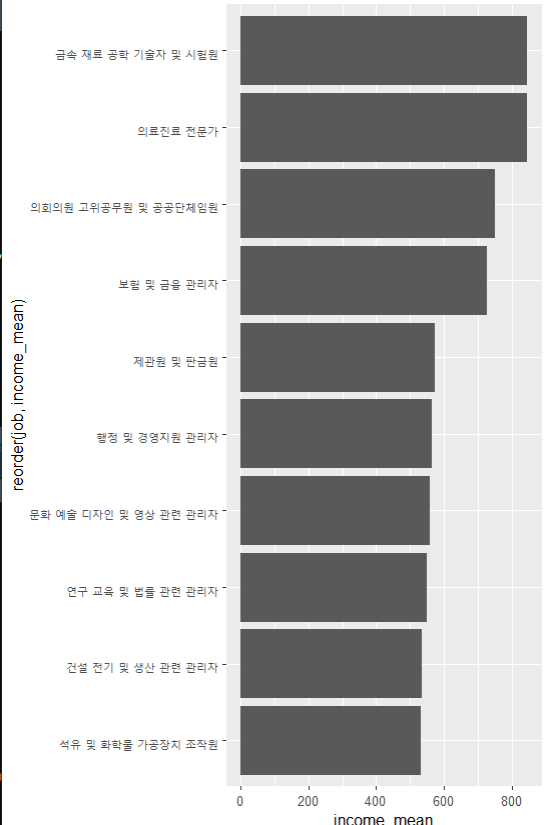
내림차순으로 축 전환 해서 그래프 만들기
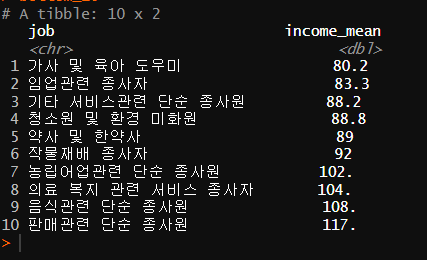
하위 10개 직업
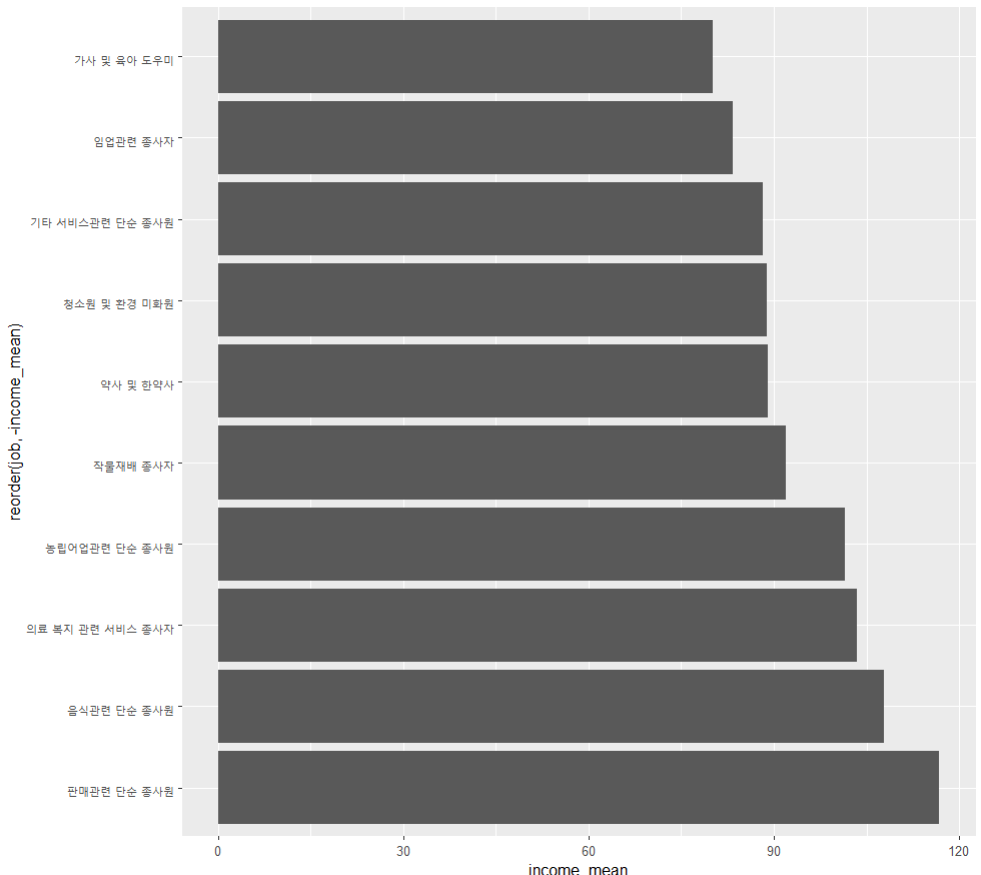
하위 10개 직업 내림차순 막대 그래프
3) 7번째 주제 : 성별과 직업에 따른 빈도의 차이
# 일곱번째 주제 : 성별과 직업에 따른 빈도의 차이
# 1. 성별과 직업에 따른 빈도 차이가 있는가?
# 2. 성별, 직업 변수 검토
# 3. 성별과 직업의 관계 분석
# 변수 검토는 앞선 분석에서 모두 완료하였음
# 성별과 직업에 따른 빈도 데이터가 필요
# 성별 빈도 확인
table(welfare$sex)
# 남자 데이터
male_job <-
welfare %>%
filter(sex == "Male" & !is.na(job)) %>%
group_by(job) %>%
summarise(freq = n()) %>%
arrange(desc(freq)) %>%
head(10)
# 남자 상위 10개 직업 빈도에 대한 막대 그래프 만들기
ggplot(data = male_job, aes(x=job, y=freq)) +
geom_col()
# x축의 직업 이름이 겹쳐서 축 전환하기
ggplot(data = male_job, aes(x=job, y=freq)) +
geom_col() +
coord_flip()
# 직업 이름 막대 순서를 내림차순으로 변경 (축이 전환되어서 내림차순임)
ggplot(data = male_job, aes(reorder(x=job, freq), y=freq)) + geom_col() +
coord_flip()
# 테스트용도
# is.na(welfare$sex == "Female")
# welfare %>% filter(!is.na(sex == "Female"))
# 여자 데이터
# 전부 false 뱉으니깐 Female 값을 얻을 수 없는 것.
female_job <-
welfare %>%
filter(sex == "Female"& !is.na(job)) %>%
group_by(job) %>%
summarise(freq = n()) %>%
arrange(desc(freq)) %>%
head(10)
female_job
# 여자 상위 10개 직업 빈도에 대한 막대 그래프 만들기
ggplot(data = female_job, aes(x=job, y=freq)) +
geom_col()
# x축의 직업 이름이 겹쳐서 축 전환하기
ggplot(data = female_job, aes(x=job, y=freq)) +
geom_col() +
coord_flip()
# 내림차순으로 정렬
ggplot(data = female_job, aes(reorder(x=job, freq), y=freq)) + geom_col() +
coord_flip()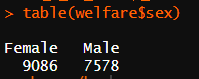
성별 빈도
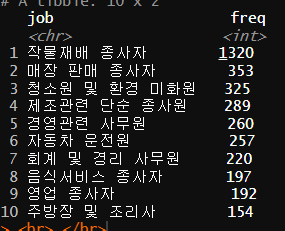
남자 상위 직업 10개
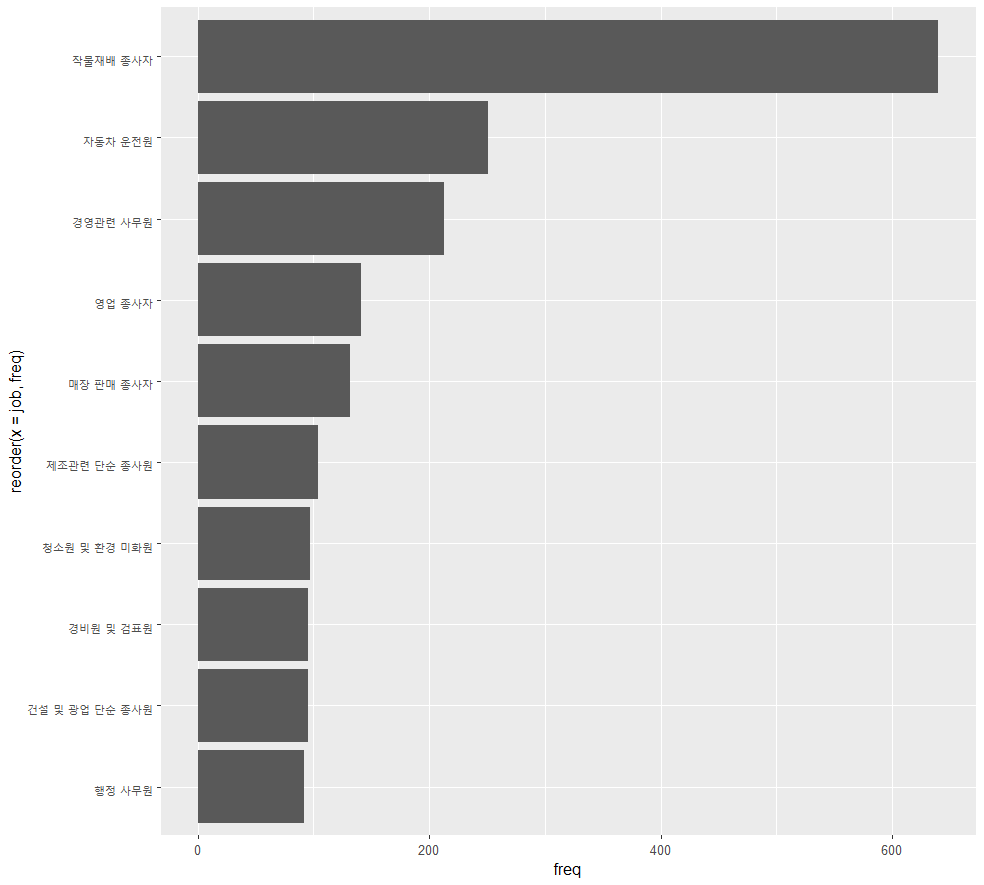
직업 이름 막대 순서를 내림차순으로 변경 (축이 전환되어서 내림차순임)
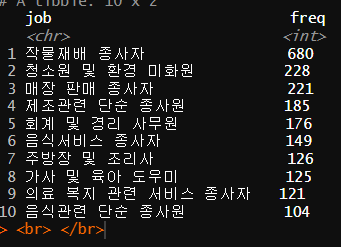
여자 상위 직업 10% 데이터
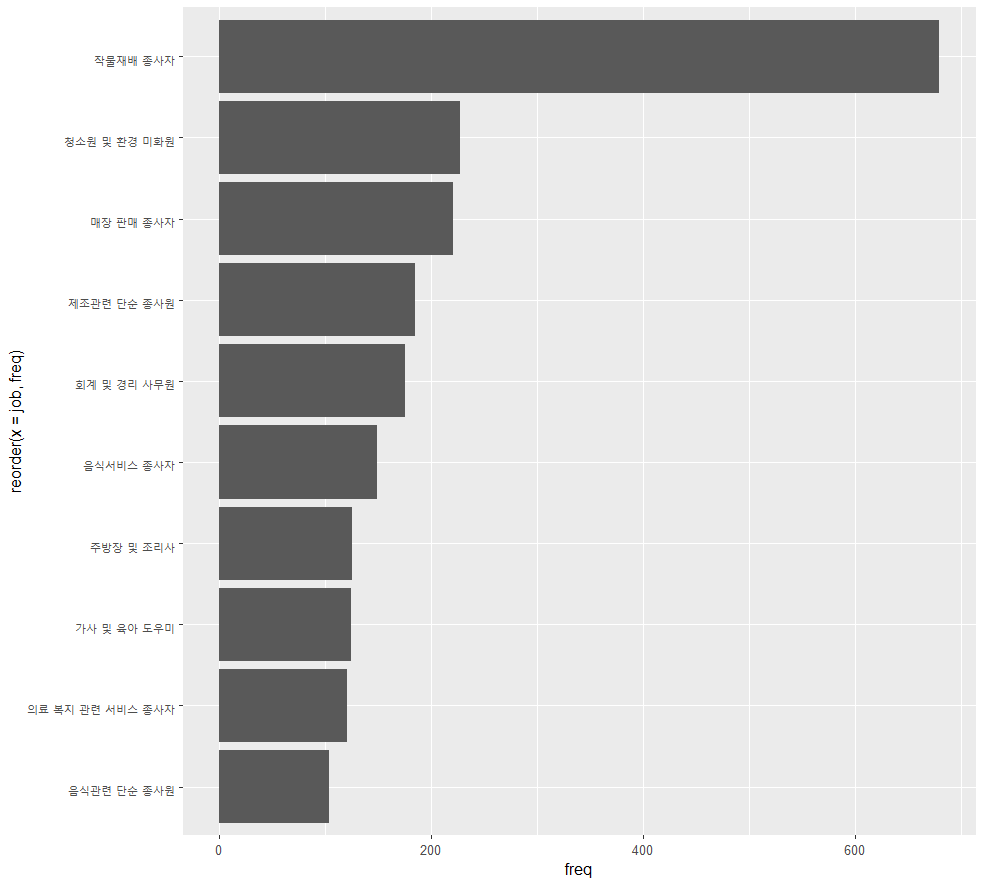
직업 이름 막대 순서를 내림차순으로 변경 (축이 전환되어서 내림차순임)
4) 여덟번째 주제 : 종교 유무에 따른 이혼율의 차이
# 여덟번째 주제 : 종교 유무에 따른 이혼율의 차이
# 1. 종교 유무에 따른 이혼율의 차이가 있는가?
# 2. 종교, 이혼율 변수 검토
# 3. 종교와 이혼율의 관계 분석
# 종교 변수 검토 = 범주형 변수 = 빈도표
table(welfare$religion)
# 이상치 없음
table(is.na(welfare$religion))
# 결측치 없음
# 종교 변수를 범주형으로 변환
welfare$religion <- ifelse(welfare$religion == 1, "yes", "no")
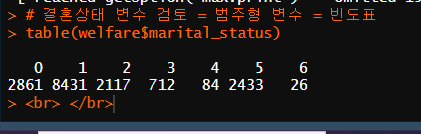
# 결혼상태 변수 검토 = 범주형 변수 = 빈도표
table(welfare$marital_status)
# "0.비해당(18세 미만)
# 1.유배우 2.사별 3.이혼 4.별거
# 5.미혼(18세이상, 미혼모 포함) 6.기타(사망 등)"
# 변수의 조작적 정의
# 이혼율 = 이혼 / (유배우+이혼)
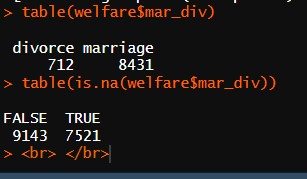
welfare$mar_div <- ifelse(welfare$marital_status == 1, "marriage",
ifelse(welfare$marital_status == 3, "divorce",NA))
table(welfare$mar_div)
table(is.na(welfare$mar_div))
# 종교 유무에 따른 이혼율 데이터 필요함
# 종교 유무에 따른 이혼율의 차이
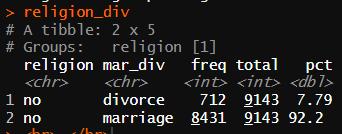
religion_div <- welfare %>%
filter(!is.na(mar_div)) %>%
group_by(religion,mar_div) %>%
summarise(freq = n()) %>%
mutate(total = sum(freq),
pct=freq/total*100)
religion_div
# 우리에게 필요한 데이터만 추출 = 종교 유무, 이혼율
religion_div<- religion_div %>%
filter(mar_div == "divorce") %>%
select(religion, pct)
# 종교 유무에 따른 이혼율 막대 그래프 그리기
ggplot(data = religion_div, aes(x=religion, y=pct))+
geom_col()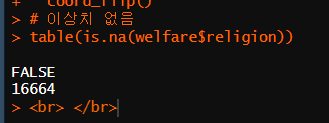
이상치 없음 확인
결혼상태 변수 검토
(앞서 welfare$religion <- ifelse(welfare$religion == 1, "yes", "no")를 통해 종교 변수를 범주형으로 변환함)
이혼율을 구하기 위해 아래의 코드를 통해 이혼율 구하기.
felse(welfare$marital_status == 1, "marriage",
ifelse(welfare$marital_status == 3, "divorce",NA))그 후 테이블을 통해 이상치 확인.
종교 유무에 따른 이혼율 차이 구하는 것.
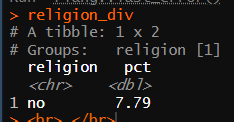
종교 유무와 이혼율(divorce)만 추출
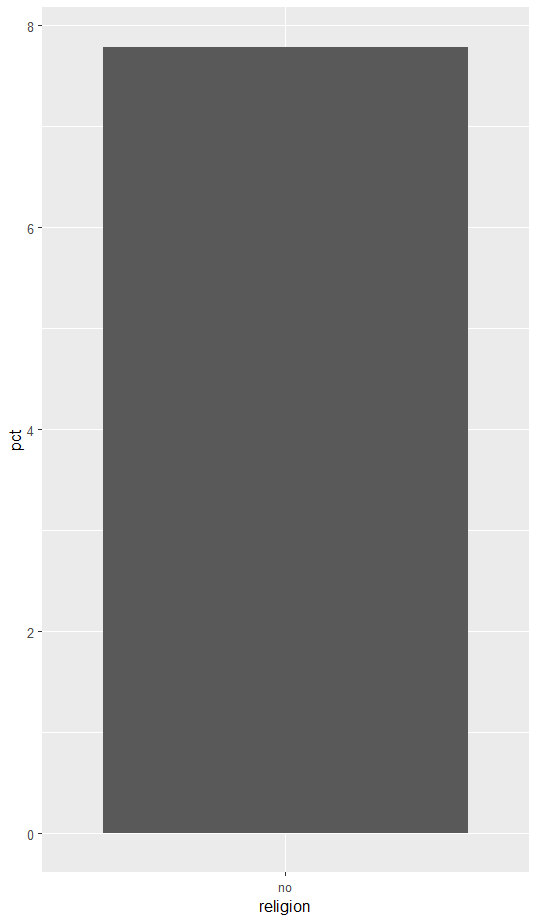
막대 그래프 추출
5) 아홉번째 주제 : 연령대에 따른 이혼율의 차이
# 아홉번째 주제 : 연령대에 따른 이혼율의 차이
# 1. 연령대 유무에 따른 이혼율의 차이가 있는가?
# 2. 연령대, 이혼율 변수 검토
# 3. 연령대와 이혼율의 관계 분석
# 연령대 변수 검토 = 범주형 변수 = 빈도표
age_group_div <- welfare %>%
filter(!is.na(mar_div)) %>%
group_by(age_group, mar_div) %>%
summarise(freq=n()) %>%
mutate(total = sum(freq),
pct = freq/total*100)
age_group_div
# young 연령대의 샘플이 불충분하여 제외
# 우리에게 필요한 데이터만 추출 = 연령대, 이혼율
# 연령대에 따른 이혼율
age_group_div <- age_group_div %>%
filter(mar_div != "young" & mar_div == "divorce") %>%
select(freq, pct)
age_group_div
# 연령대에 따른 이혼율 막대 그래프 그리기
ggplot(data = age_group_div, aes(x=age_group, y=pct))+
geom_col()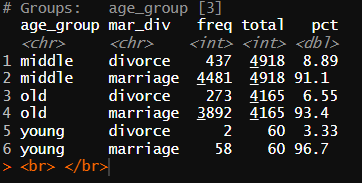
연령대, 이혼율 변수 추출
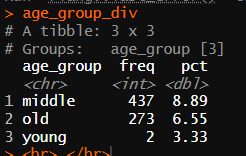
연령대에 따른 이혼율 추출
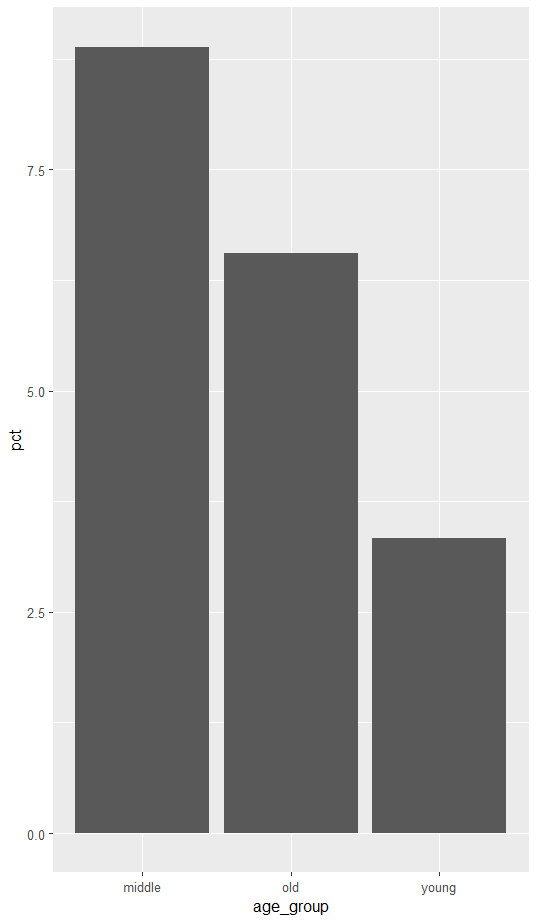
연령대에 따른 이혼율 막대 그래프 그리기
6) 열번째 주제 : 종교 유무에 따른 이혼율의 차이
# 열번째 주제 : 종교 유무에 따른 이혼율의 차이
# 1. 종교 유무, 연령대에 따른 이혼율의 차이가 있는가?
# 2. 종교, 연령대, 이혼율 변수 검토
# 3. 종교 유무, 연령대와 이혼율의 관계 분석
# 변수 검토는 앞선 분석에서 모두 완료하였음
# 종교 유무, 연령대에 따른 이혼율 데이터가 필요함
age_group_religion_div <- welfare %>%
filter(!is.na(mar_div)) %>%
group_by(age_group,religion,mar_div) %>%
summarise(freq=n()) %>%
mutate(total = sum(freq),
pct = freq/total*100)
age_group_religion_div
# young 연령대의 샘플이 불충분하여 제외
# 우리에게 필요한 데이터만 추출 = 연령대, 종교유무, 이혼율
age_group_religion_div <- age_group_religion_div %>%
filter(age_group != "young" & mar_div == "divorce") %>%
select(age_group, religion, pct)
age_group_religion_div
# 연령대, 종교 유무에 따른 이혼율 막대 그래프 그리기
# 막대를 나란히 세우기
ggplot(data=age_group_religion_div, aes(x=age_group, y=,pct, fill=religion)) +geom_col(position = "dodge")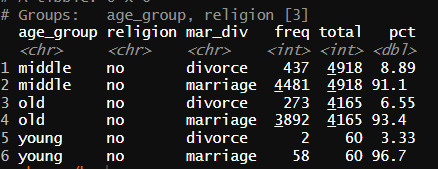
연령대, 종교유무, 결혼유무, 이혼율 변수 추출
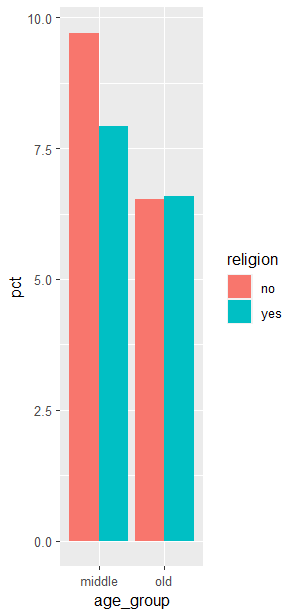
연령대, 종교 유무에 따른 이혼율 막대 그래프 그리기 + 막대를 나란히 세우기
7) 열한번째 주제 : 지역에 따른 연령대 비율의 차이
# 열한번째 주제 : 지역에 따른 연령대 비율의 차이
# 1. 지역에 따른 연령대 비율의 차이가 있는가?
# 2. 지역, 연령대 변수 검토
# 3. 지역, 연령대의 관계 분석
# 지역 변수 검토 = 범주형 변수 = 빈도표
table(welfare$region)
# "1. 서울 2. 수도권(인천/경기) 3. 부산/경남/울산 4.대구/경북 5. 대전/충남 6. 강원/충북 7.광주/전남/전북/제주도"
# 지역 이름으로 변경
region_name <- data.frame(region = c(1:7),
region_name = c("서울","수도권(인천/경기)","부산/경남/울산","대구/경북","대전/충남","강원/충북","광주/전남/전북/제주도"))
# welfare 데이터와 region_name 데이터를 region 코드로 합치기
welfare <- left_join(welfare,region_name,by="region")
head(welfare)
# region_name 변수 검토
table(welfare$region_name)
#이상치 없음
table(is.na(welfare$region_name))
# 결측치 없음
# 지역에 따른 연령대 비율 데이터가 필요함
region_age_group <- welfare %>%
group_by(region_name, age_group) %>%
summarise(freq=n()) %>%
mutate(total = sum(freq),
pct = freq/total*100)
region_age_group
# 지역에 따른 연령대 비율 막대 그래프 그리기
ggplot(data = region_age_group, aes(x=region_name, y =pct, fill=age_group))+geom_col(position = "dodge")
# 축 전환
ggplot(data = region_age_group, aes(x=region_name, y =pct, fill=age_group))+geom_col(position = "dodge") +
coord_flip()
# 막대 안의 연령대 순서를 정하기 위해
class(region_age_group$age_group)
region_age_group$age_group <- factor(region_age_group$age_group,levels=c("old","middle","young"))
class(region_age_group$age_group)
levels(region_age_group$age_group)
# 축 전환
ggplot(data = region_age_group, aes(x=region_name, y=pct, fill=age_group))+
geom_col()+
coord_flip()
# 막대 순서를 노년의 비율이 높은 지역에서 낮은 지역으로 변경 (내림차순)
old <- region_age_group %>%
filter(age_group == "old") %>%
arrange(pct)
order<- old$region_name
# 순서변경
ggplot(data = region_age_group, aes(x=region_name, y=pct, fill=age_group))+
geom_col()+
coord_flip()+
scale_x_discrete(limits = order)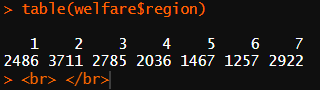
지역 변수 검토

region_name을 통한 지역 이름 변경
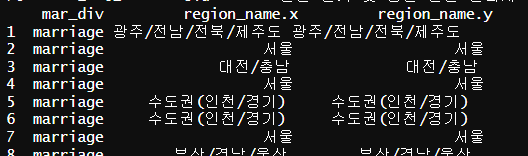
welfare 데이터와 region_name 데이터를 region 코드로 합치기
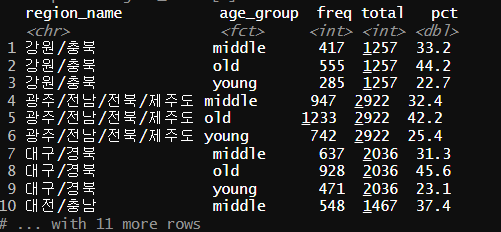
지역에 따른 연령대 비율 데이터
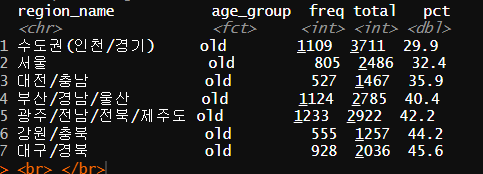
노년의 비율이 높은 지역에서 낮은 지역으로 변경(내림차순)
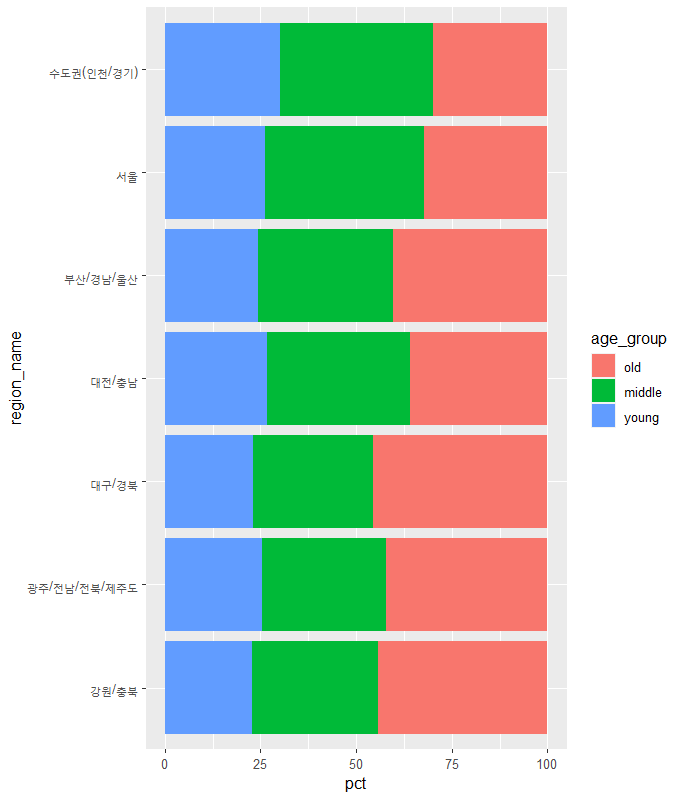
오름차순의 경우
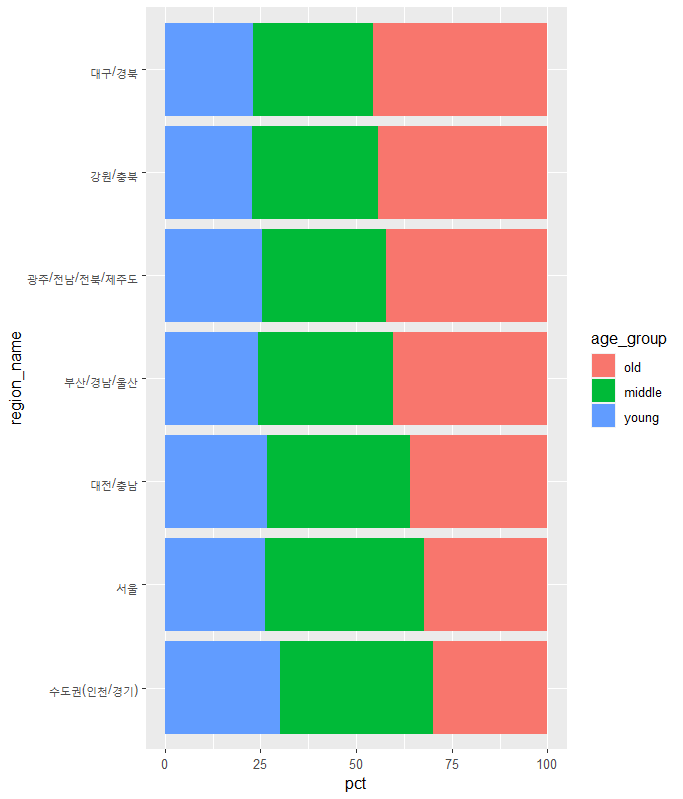
내림차순의 경우
2. 텍스트 마이닝
# 텍스트 마이닝
# Korean Natural Language processing
# KoNLP 패키지 설치
install.packages("multilinguer")
library(multilinguer)
# JDK
install_jdk()
# 관련 패키지 설치
install.packages(c("stringr","hash","tau","Sejong","RSQLite",
"devtools",type="binary"))
# KoNLP 설치
install.packages("remotes")
library(remotes)
remotes::install_github("haven-jeon/KoNLP",
upgrade = "never",
INSTALL_opts = c("--no-multiarch"))
#
library(KoNLP)
# 사전 설정
useNIADic()
# 데이터 준비
txt <- readLines("./SpyderBD_01/data/hiphop.txt")
head(txt)
txt
# 특수 문자를 blank로 변경 항상 특수문자로!
library(stringr)
txt <- str_replace_all(txt, "\\W", " ")
txt
# 명사 추출
noun <- extractNoun(txt)
noun
# 리스트 형태 풀어주기
wordcount <- table(unlist(noun))
str(wordcount)
# 데이터프라임 구조로 변경
word_df <- as.data.frame(wordcount, stringsAsFactors = F)
str(word_df)
# 변수 이름 변경
library(tidyverse)
word_df <- rename(word_df,
word = Var1,
freq = Freq )
head(word_df)
# 2글자 이상의 단어 추출
word_df <- word_df %>%
filter(nchar(word) >= 2)
# 상위 20단어 추출
top20 <- word_df %>%
arrange(desc(freq)) %>%
head(20)
top20
# 워드 클라우드
install.packages("wordcloud")
library(wordcloud)
# 색상 설정
library(RColorBrewer)
pal <- brewer.pal(8, "Dark2")
#
set.seed(1)
wordcloud(words = word_df$word,
freq = word_df$freq,
min.freq = 2,
max.words = 200,
random.order = F,
rot.per = 0.3,
scale = c(3, 0.3),
colors = pal)
데이터 준비
특수문자 제거
명사 추출
리스트 형태로 추출
데이터 프라임 구조로 변경
변수 이름 변경
2글자 이상 단어 추출

상위 20단어 추출

set.seed(1)
wordcloud(words = word_df$word,
freq = word_df$freq,
min.freq = 2,
max.words = 200,
random.order = F,
rot.per = 0.3,
scale = c(3, 0.3),
colors = pal)텍스트 마이닝 시각화
* 핵심
- 데이터 마이닝 사용방법 알아둘 것.
- 주제 제시에 따라 어떤 분석 기법을 사용할지 예상하고 그에 따른 변수값 구하는 것을
순서대로 생각하고 코딩할 것.
'배운 책들 정리 > 만만한 통계 : R 활용' 카테고리의 다른 글
| 0303 만만한 통계 R 외부 챕터 11~14 - 지도 시각화, 인터랙티브 그래프, 통계분석 가설 검정, R markdown (1) | 2023.03.03 |
|---|---|
| 0228 만만한 통계 R 외부 챕터 8~9 - 그래프 만들기, 데이터 분석 프로젝트 (0) | 2023.02.28 |
| 0227 만만한 통계 R 외부 챕터 6~8 - 데이터 추출, 데이터 합치기, 데이터 정제, 그래프 (0) | 2023.02.27 |
| 0224 만만한 통계 R 외부 챕터 4~6 - 데이터 프레임, 데이터 분석, 데이터 가공 (1) | 2023.02.24 |
| 0223 만만한 통계 R 외부 챕터 15 - 내장 함수, 변수 타입과 데이터 구조 // 기초 문제 연습 (0) | 2023.02.23 |



