4장 시각화
1. 시각화
1) seaborn 시각화

# 데이터 불러오기
import seaborn as sns
import matplotlib.pyplot as plt
titanic = sns.load_dataset("titanic")
# 스타일 테마
sns.set_style("whitegrid")
# 피벗 테이블로 범주형 변수를 행과 열 형태로 정리
table = titanic.pivot_table(index="sex",columns="class",aggfunc="size")
# 히트맵
sns.heatmap(table,
annot=True, # 데이터 값 표시 여부
fmt="d", # 숫자 표현 방식 지정 : d = 정수형
cmap="YlGnBu", # 컬러맵
linewidth=.5, # 구분선
cbar=False) # 컬러바 표시 여부
2) 범주형 데이터의 산점도


# 범주형 데이터 산점도
# 그래프 객체 생성
fig = plt.figure(figsize=(10, 10))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
# 범주형 변수 산점도.
# 1) 분산 고려하지 않는 경우
sns.stripplot(x="class",
y="age",
data=titanic,
ax=ax1)
# 2) 분산 고려하는 경우
sns.swarmplot(x="class",
y="age",
data=titanic,
ax=ax2)
# 제목 추가
ax1.set_title("strip plot")
ax2.set_title("swarm plot")
3) 빈도 그래프
* 막대 그래프
# %%
# 막대 그래프
# 그래프 객체 생성
fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(1,3,1)
ax2 = fig.add_subplot(1,3,2)
ax3 = fig.add_subplot(1,3,3)
# 막대 그래프
sns.barplot(x="sex",
y="survived",
data=titanic,
ax=ax1)
sns.barplot(x="sex",
y="survived",
hue = "class",
data=titanic,
ax=ax2)
sns.barplot(x="sex",
y="survived",
hue="class",
dodge=False,
data=titanic,
ax=ax3)
# 제목 추가
ax1.set_title("sex")
ax2.set_title("sex/class")
ax3.set_title("sex/class(checked)")
* 빈도 그래프

# %%
# 빈도 그래프
# 그래프 객체 생성
fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(1,3,1)
ax2 = fig.add_subplot(1,3,2)
ax3 = fig.add_subplot(1,3,3)
# 막대그래프
sns.countplot(x="class",
palette="Set1",
data=titanic,
ax=ax1)
sns.countplot(x="class",
hue="who",
palette="Set2",
data=titanic,
ax=ax2)
sns.countplot(x="class",
hue="who",
palette="Set3",
dodge=False,
data=titanic,
ax=ax3)
# 에러바(막대기가 의미하는 것) : 표준편차, 표준오차, 신뢰구간 등등
# 제목 추가
ax1.set_title("class")
ax2.set_title("class - who")
ax3.set_title("class - who(stacked)")
* 에러바 표시 x

# %%
# 에러바 표시 x
fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(1,3,1)
sns.barplot(x="sex",
y="survived",
data=titanic,
ax=ax1,
errorbar=None)
4) 박스 플롯/바이올린 그래프

# %%
# 박스 플롯/바이올린 그래프
fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
ax4 = fig.add_subplot(2,2,4)
# 상자그림
sns.boxplot(x="alive",y="age",data=titanic,ax=ax1)
sns.boxplot(x="alive",y="age",hue="sex",data=titanic,ax=ax2)
# 바이올린그림
sns.violinplot(x="alive",y="age",data=titanic,ax=ax3)
sns.violinplot(x="alive",y="age",hue="sex",data=titanic,ax=ax4)
5) 조인트 그래프





# %%
# 조인트 그래프
# 조인트 그림 - 산점도(기본값)
jp1 = sns.jointplot(x="fare",y="age",data=titanic)
# 조인트 그림 - 산점도 + 회귀선
jp2 = sns.jointplot(x="fare",y="age",kind="reg",data=titanic)
# 조인트 그림 - 육각 산점도
jp3 = sns.jointplot(x="fare",y="age",kind="hex",data=titanic)
# 조인트 그림 - 커널밀도함수
jp4 = sns.jointplot(x="fare",y="age",kind="kde",data=titanic)
# 제목 추가
jp1.fig.suptitle("Tf - scatter")
jp2.fig.suptitle("Tf - reg")
jp3.fig.suptitle("Tf - hex")
jp4.fig.suptitle("Tf - kde")
* 조건 적용해서 화면을 그리드로 분할하기

# %%
# 조건 적용해서 화면을 그리드로 분할하기
g=sns.FacetGrid(data=titanic,col="who",row="survived")
g=g.map(plt.hist,"age")
* 이변수 데이터의 분포

# %%
# 이변수 데이터의 분포
titanic_pair = titanic[["age","pclass","fare"]]
g=sns.pairplot(titanic_pair)
2. 지도 시각화
1) 지도 만들기
* 지도 만들기

# %%
# 지도 만들기
import folium
seoul_map = folium.Map(location=[37.55,126.98],zoom_start=12)
seoul_map.save("./seoul.html")
* 스타일 지정

# %%
# 지도 스타일 적용하기
seoul_map2 = folium.Map(location=[37.55,126.98],tiles="Stamen Terrain",
zoom_start=12)
seoul_map3 = folium.Map(location=[37.55,126.98],tiles="Stamen Toner",
zoom_start=15)
seoul_map2.save("./seoul2.html")
seoul_map3.save("./seoul3.html")
* 스타일 지정 2

# %%
# 지도에 마커 표시하기
import pandas as pd
df=pd.read_excel("/content/drive/MyDrive/BDA/part4/서울지역 대학교 위치.xlsx",engine="openpyxl")
seoul_map = folium.Map(location=[37.55,126.98],tiles="Stamen Terrain",
zoom_start=12)
for name, lat, lng in zip(df.index,df.위도,df.경도):
folium.Marker([lat,lng],popup=name).add_to(seoul_map)
seoul_map.save("./seoul_colleges.html")
* 지도 마커 표시

# %%
# 지도에 마커 표시하기
import pandas as pd
df=pd.read_excel("/content/drive/MyDrive/BDA/part4/서울지역 대학교 위치.xlsx",engine="openpyxl")
seoul_map = folium.Map(location=[37.55,126.98],tiles="Stamen Terrain",
zoom_start=12)
for name, lat, lng in zip(df.index,df.위도,df.경도):
folium.Marker([lat,lng],popup=name).add_to(seoul_map)
seoul_map.save("./seoul_colleges.html")
* 지도 원형 마커 표시

# %%
# 지도 원형 마커 표시
import pandas as pd
df=pd.read_excel("/content/drive/MyDrive/BDA/part4/서울지역 대학교 위치.xlsx",engine="openpyxl")
seoul_map = folium.Map(location=[37.55,126.98],tiles="Stamen Terrain",
zoom_start=12)
for name, lat, lng in zip(df.index,df.위도,df.경도):
folium.CircleMarker([lat,lng],
radius=10,
color="Brown",
file=True,
fill_color="coral",
fill_opacity=0.7,
popup=name).add_to(seoul_map)
seoul_map.save("./seoul_colleges2.html")
* 지도 영역 단계구분도 표시
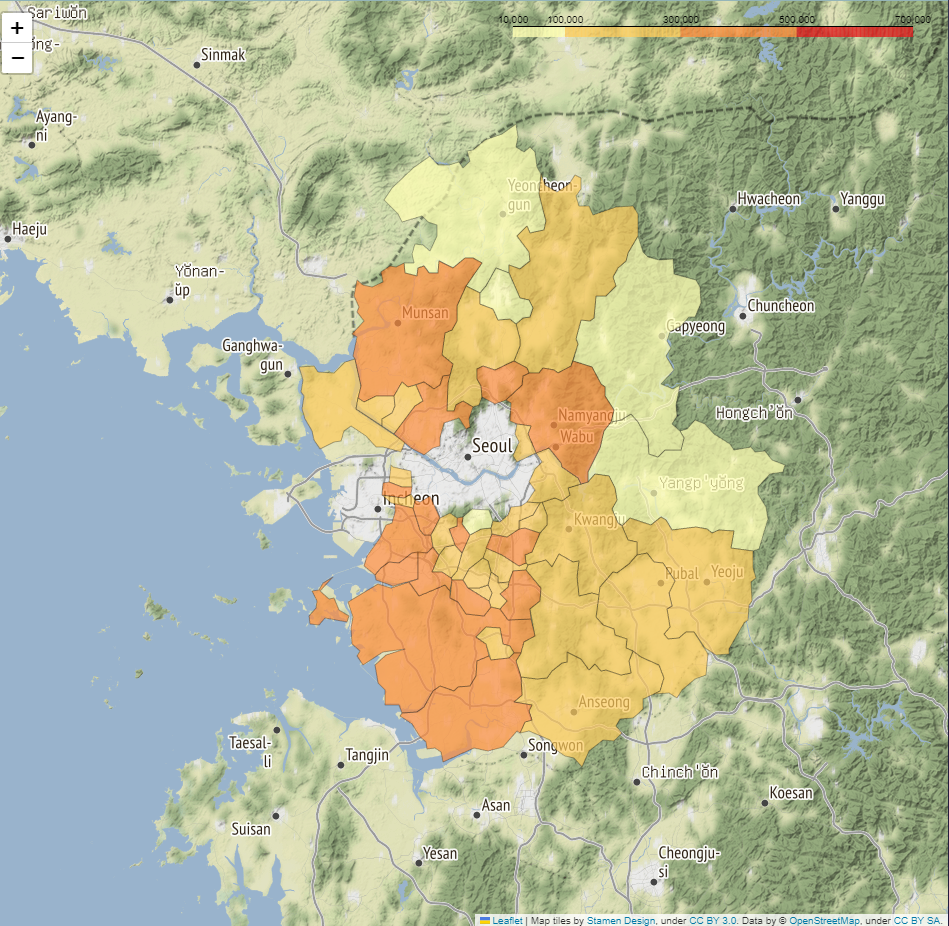
# %%
# 지도 영역 단계구분도 표시
import json
file_path= r"/content/drive/MyDrive/BDA/part4/경기도인구데이터.xlsx"
df = pd.read_excel(file_path,index_col="구분",engine="openpyxl")
df.columns=df.columns.map(str)
geo_path = r"/content/drive/MyDrive/BDA/part4/경기도행정구역경계.json"
try:
geo_data=json.load(open(geo_path,encoding="utf-8"))
except:
geo_data=json.load(open(geo_path,encoding="utf-8-sig"))
g_map=folium.Map(location=[37.5502,126.982],
tiles="Stamen Terrain",zoom_start=9)
year = "2007"
folium.Choropleth(geo_data=geo_data,
data = df[year],
columns=[df.index,df[year]],
fill_color="YlOrRd",fill_opacity=0.7,line_opacity=0.3,
threshold_scale=[10000,100000,300000,500000,700000],
key_on = "feature.properties.name",
).add_to(g_map)
g_map.save("./gyonggi_population_"+year+".html")feature.properties.name은 지도 정보 이름을 통해서 확인해 이름을 설정한 것.
3. 데이터 전처리
1) 비어 있는 값 = 누락 데이터
* 누락 데이터 처리

# %%
# 누락 데이터 처리
import seaborn as sns
df=sns.load_dataset("titanic")
df.info()
# deck 열의 Nan 개수 계산
nan_deck = df['deck'].value_counts(dropna=False)
print(nan_deck)
* 누락 데이터 확인부터 개수 구하기까지

# Null값을 직접 확인 = R isna()
# isnull () # 널값이면 True, 아니면 False
# notnull () # 널값이면 False, 아니면 True
df.head().isnull()
# isnull() 메소드로 누락 데이터 찾기
print(df.head().isnull())
# notnull() 메소드로 누락 데이터 찾기
print(df.head().notnull())
# isnull() 메소드로 누락 데이터 개수 구하기
print(df.head().isnull().sum(axis=0)) # axis=0 없어도 같은 결과임
* 반복문을 돌려서 전체 열에 대한 널값 개수 // 널값 많은 열 삭제까지


# %%
# 반복문을 돌려서 전체 열에 대한 널값 개수
for col in df.columns:
print(df[col].isnull().value_counts())
# 널값이 많은 열 삭제 - 600개 이상이 널값이 삭제
df.dropna(axis=1,thresh=600)
* 누락 데이터 제거


# %%
# 누락 데이터 제거
df=sns.load_dataset("titanic")
df.info()
missing_df=df.isnull()
for col in missing_df.columns:
missing_count = missing_df[col].value_counts()
try:
print(col,': ',missing_count[True])
except:
print(col,": ", 0)
# NaN 값이 500개 이상인 열을 모두 삭제 - deck 열(891개 중 688개의 NaN 값)
df_thresh = df.dropna(axis=1,thresh=500)
print(df_thresh.columns)
# age 열에 나이 데이터가 없는 모든 행 삭제 - age 열(891개 중 177개의 NaN 값)
df_age=df.dropna(subset="age",how="any",axis=0)
print(len(df_age))
2) Null값 대체 imputation
* 평균으로 누락 데이터 바꾸기
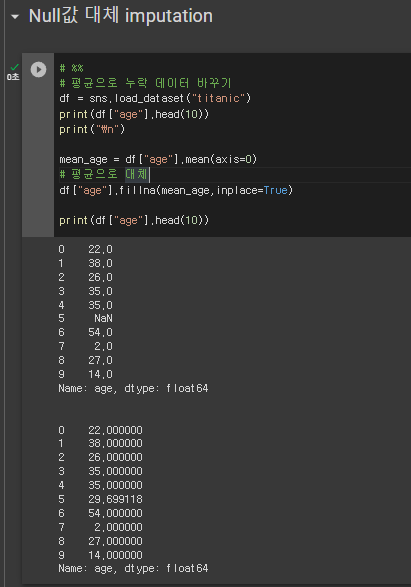
# %%
# 평균으로 누락 데이터 바꾸기
df = sns.load_dataset("titanic")
print(df["age"].head(10))
print("\n")
mean_age = df["age"].mean(axis=0)
# 평균으로 대체
df["age"].fillna(mean_age,inplace=True)
print(df["age"].head(10))
* 가장 많이 나타나는 값을 바꾸기

# %%
# 가장 많이 나타나는 값을 바꾸기
df = sns.load_dataset("titanic")
print(df["embark_town"][825:830])
print("\n")
# embark_town 열의 NaN 값을 승선도시 중에서 가장 많이 출현한 값으로 치환하기
most_freq = df["embark_town"].value_counts(dropna=True).idxmax()
print(most_freq)
print("\n")
df["embark_town"].fillna(most_freq,inplace=True)
# embark_town 열 829행의 NaN 데이터 출력(NaN 값이 most_freq값으로 대체)
print(df["embark_town"][825:830])
* 이웃하고 있는 값으로 바꾸기

# %%
# 이웃하고 있는 값으로 바꾸기
df = sns.load_dataset("titanic")
# embark_town 열 829 행의 NaN 데이터 출력
print(df["embark_town"][825:830])
print("\n")
# embark_town 열의 NaN 값을 바로 앞에 있는 828행의 값으로 변경하기
# 앞에 있는 값으로 대체 = ffill
df["embark_town"].fillna(method="ffill", inplace=True)
# 뒤에 있는 값으로 대체 = bfill
#df["embark_town"].fillna(method="bfill", inplace=True)
print(df["embark_town"][825:830])
3) 중복 데이터
* 중복 데이터 처리

# %%
## 중복 데이터 처리
import pandas as pd
df=pd.DataFrame({"c1":["a","a","b","a","b"],
"c2":[1,1,1,2,2],
"c3":[1,1,2,2,2]})
print(df)
print("\n")
# 데이터프레임 전체 행 데이터 중에서 중복값 찾기
df_dup = df.duplicated()
print(df_dup)
print("\n")
* 중복값 찾기 ~ 중복 데이터 제거, 중복 행 제거

# %%
# 중복 데이터 확인
# 데이터프레임의 특정 열 데이터에서 중복값 찾기
col_dup=df['c2'].duplicated()
print(col_dup)
# %%
# 중복 데이터 제거
df=pd.DataFrame({"c1":["a","a","b","a","b"],
"c2":[1,1,1,2,2],
"c3":[1,1,2,2,2]})
print(df)
print("\n")
# 데이터프레임에서 중복 행 제거
df2 = df.drop_duplicates()
print(df2)
print("\n")
df3 = df.drop_duplicates(subset=["c2","c3"])
print(df3)
# 185P 끝
4) 데이터 표준화 - 단위 환산

# %%
# 단위 환산
# 데이터 표준화
import pandas as pd
df=pd.read_csv(r'/content/drive/MyDrive/BDA/part4/auto-mpg.csv', header=None)
df.columns = ["mpg","cylinders","displacement","horsepower",
"weight","acceleration","model year","origin","name"]
print(df.head(3))
# 연비 mpg = mile per gallon
# kpl = kilometer per liter
# 1 mpg = 0.425 kpl
# kpl = 0.425
mpg_to_kpl = 1.60934/3.78541
df["kpl"] = df["mpg"] * mpg_to_kpl
print(df.head(3))
df["kpl"] = df["kpl"].round(2)
print(df.head(3))
4) 데이터 표준화 - 자료형 변환

# %%
# 자료형 변환
# 자료형 확인
df=pd.read_csv(r'/content/drive/MyDrive/BDA/part4/auto-mpg.csv', header=None)
df.columns = ["mpg","cylinders","displacement","horsepower",
"weight","acceleration","model year","origin","name"]
print(df.dtypes)
print("\n")
# horsepower 열의 고유값 확인
print(df["horsepower"].unique())
print("\n")
# 누락 데이터("?") 삭제
import numpy as np
df["horsepower"].replace("?",np.nan, inplace=True)
df.dropna(subset=["horsepower"], axis=0,inplace=True)
df["horsepower"]=df["horsepower"].astype("float")
print(df["horsepower"].dtypes)
* 문자열 -> 범주형 변환 // 범주형 -> 문자열 변환

# %%
# 숫자가 문자열로 저장되어 있다면 숫자로 변환 = 연속형 변수
# 자료형
df.dtypes
print(df["origin"].unique())
# %%
# 정수형 데이터를 문자열 데이터로 변환
df["origin"].replace({1:"USA",2:"EU",3:"JPN"}, inplace=True)
print(df["origin"].unique())
print(df["origin"].dtypes)# %%
# 문자열 -> 범주형 변환
df["origin"] = df["origin"].astype("category")
print(df["origin"].dtypes)
# 범주형 -> 문자열 변환
df["origin"] = df["origin"].astype("str")
print(df["origin"].dtypes)# %%
# model year 열의 정수형을 범주형으로 변환
print(df["model year"].sample(3))
df["model year"] = df["model year"].astype("category")
print(df["model year"].sample(3))
# 191p
* 핵심
- R과 파이썬의 그래프 시각화 구문 차이점 (코드 표현이 어떻게 다른지)
- R과 파이썬의 지도 시각화 구문 차이점 (코드 표현이 어떻게 다른지)
- R과 파이썬의 데이터 전처리 구문 차이점 (코드 표현이 어떻게 다른지)
* 오늘 작성한 코드 (0427 Python)
guromd1
guromd1.blogspot.com
* 링크 (작성한 계정으로 로그인)
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
'배운 책들 정리 > 파이썬 머신러닝 판다스 데이터분석' 카테고리의 다른 글
| 파이썬 머신러닝 판다스 데이터 분석 6,7 - 데이터프레임의 다양한 응용, 머신러닝 데이터 분석 (0) | 2023.05.01 |
|---|---|
| 파이썬 머신러닝 판다스 데이터 분석 5,6 - 데이터 사전 처리, 데이터프레임의 다양한 응용 (0) | 2023.04.28 |
| 파이썬 머신러닝 판다스 데이터 분석 4_2 - 시각화 (0) | 2023.04.26 |
| 파이썬 머신러닝 판다스 데이터 분석 3,4 - 데이터 살펴보기, 시각화 (1) | 2023.04.25 |
| 파이썬 머신러닝 판다스 데이터 분석 1,2 - 판다스 입문, 데이터 입출력 (0) | 2023.04.24 |



