6장 데이터프레임의 다양한 응용
1. 데이터프레임 병합
* 데이터프레임 병합

# 부수적인 요소
# %%
# 데이터프레임 병합
# Ipyhton 디스플레이 설정 변경
import pandas as pd
pd.set_option("display.max_columns",10) # 출력할 최대 열의 개수
pd.set_option("display.max_colwidth",20) # 출력할 열의 너비
pd.set_option("display.unicode.east_asian_width",True) # 유니코드 사용 너비 조정
##데이터프레임 병합
# SQL JOIN 유사 = 좌우 병합 = merge()
# 공통된 열, 인덱스 = 키
# 라이브러리 불러오기
import pandas as pd
# 데이터 불러오기
df1 = pd.read_excel("/content/drive/MyDrive/BDA/part6/stock price.xlsx",engine="openpyxl")
df2 = pd.read_excel("/content/drive/MyDrive/BDA/part6/stock valuation.xlsx",engine="openpyxl")
print(df1)
print("\n")
print(df2)
print("\n")
* iner join, full outer join

# inner join, 공통된 열은 id
# pd.merge(df1,df2, how = "inner", on = "id")
merge_inner = pd.merge(df1,df2) # 기본값은 how = "inner", on = None
print(merge_inner)
# full outer join
merge_outer = pd.merge(df1,df2, how = "outer", on = "id")
print(merge_outer)
* left join, right join, 원하는 조건 만족하는 불 인덱스와 merge


# left join
merge_left = pd.merge(df1,df2, how = "left",
left_on = "stock_name", right_on = "name")
print(merge_left)
# right join
merge_right = pd.merge(df1,df2, how = "right",
left_on = "stock_name", right_on = "name")
print(merge_right)
# 원하는 조건을 만족하는 불 인덱스와 merge
df_price = df1[df1["price"] < 100000]
data = pd.merge(df_price, df2)
print(data)
* 데이터 프레임 merge 사용하여 합치기 - 교집합, 합집합, 왼쪽 기준으로 합친 후 키 값 분리


# %%
# 데이터프레임 합치기(merge) - 교집합
merge_inner = pd.merge(df1,df2)
print(merge_inner)
# 데이터프레임 합치기(merge) - 합집합
merge_outer = pd.merge(df1,df2,how="outer",on="id")
print(merge_outer)
# 데이터프레임 합치기(merge) - 왼쪽 데이터프레임 기준, 키 값 분리
merge_left = pd.merge(df1,df2,how="left",left_on="stock_name",right_on="name")
print(merge_left)
* 데이터프레임 합치기, 불린 인덱싱과 결합하여 원하는 데이터 찾기

# %%
# 데이터프레임 합치기(merge) - 오른쪽 데이터프레임 기준, 키 값 분리
merge_right = pd.merge(df1,df2,how="right",left_on="stock_name",right_on="name")
print(merge_right)
# 불린 인덱싱과 결합하여 원하는 데이터 찾기
price = df1[df1["price"]<50000]
print(price.head())
print("\n")
value=pd.merge(price,df2)
print(value)
2. 데이터프레임 병합(결합)


# %%
# 데이터프레임 합치기(join)
pd.set_option("display.max_columns",10) # 출력할 최대 열의 개수
pd.set_option("display.max_colwidth",20) # 출력할 열의 너비
pd.set_option("display.unicode.east_asian_width",True) # 유니코드 사용 너비 조정
# 주식 데이터를 가져와서 데이터프레임 만들기
# merge 와 유사하지만 공통된 행 인덱스 기준으로 결합
# 옵션을 지정하면 열 기준으로
df1=pd.read_excel("/content/drive/MyDrive/BDA/part6/stock price.xlsx",index_col="id",engine="openpyxl")
df2=pd.read_excel("/content/drive/MyDrive/BDA/part6/stock valuation.xlsx",index_col="id",engine="openpyxl")
# 데이터 프레임 결합(join)
df3 = df1.join(df2)
print(df3)
# 데이터 프레임 결합(join) - 교집합
df4 = df1.join(df2,how="inner")
print(df4)
3. 그룹 연산
1) 그룹 객체 만들기
* 그룹 연산 분할


# %%
# 데이터프레임 객체.groupby(그룹화에 사용할 열) => 그룹 객체
# 그룹 연산 - 분할
import seaborn as sns
titanic = sns.load_dataset("titanic")
df = titanic.loc[:, ["age","sex","class","fare","survived"]]
print("승객 수:", len(df))
print(df.head())
# class 열을 기준으로 분할
grouped = df.groupby(["class"])
print(grouped)
# 그룹 객체를 iteration으로 출력: head() 메소드로 첫 5행만을 출력
for key, group in grouped:
print("* key :",key)
print("* number :", len(group))
print(group.head())
print("\n")
* 그룹 연산 분할 - 평균치

# %%
# 그룹 연산 - 분할
# 연산 메소드 적용
average = grouped.mean()
print(average)
# 개별 그룹 선택하기
group3 = grouped.get_group("Third")
print(group3.head())
* 여러 열을 기준으로 그룹화

# %%
# 여러 열을 기준으로 그룹화
# class 열, sex 열을 기준으로 분할
grouped_two = df.groupby(["class","sex"])
# grouped_two 그룹 객체를 iteration으로 출력
for key, group in grouped:
print("* key :",key)
print("* number :", len(group))
print(group.head())
print("\n")
* grouped_two 그룹 객체 연산 메소드 적용

# %%
# grouped_two 그룹 객체에 연산 메소드 적용
average_two = grouped_two.mean()
print(average_two)
print(type(average_two))
# grouped_two 그룹 객체에서 개별 그룹 선택하기
group3f = grouped_two.get_group(("Third","female"))
print(group3f.head())
* 그룹 연산 메소드(적용-결합 단계)

# %%
# 그룹 연산 메소드(적용-결합 단계)
# 데이터 집계
titanic = sns.load_dataset("titanic")
df = titanic.loc[:, ["age","sex","class","fare","survived"]]
# class 열을 기준으로 분할
grouped = df.groupby(["class"])
# 각 그룹에 대한 모든 열의 표준편차를 집계하여 데이터프레임으로 반환
std_all = grouped.std()
print(std_all)
print("\n")
print(type(std_all))
print("\n")
# 각 그룹에 대한 fare 열의 표준편차를 집계하여 시리즈로 반환
std_fare = grouped.fare.std()
print(std_fare)
print("\n")
print(type(std_fare))
print("\n")
* 집계 - 그룹 객체 agg() 메소드 적용

# %%
# 그룹 객체에 agg() 메소드 적용 - 사용자 정의 함수를 인자로 전달
def min_max(x): # 최대값 - 최소값
return x.max() - x.min()
# 각 그룹의 최대값과 최소값의 차이를 계산하여 그룹별로 집계
agg_minmax = grouped.agg(min_max)
print(agg_minmax.head())
# 여러 함수를 각 열에 동일하게 적용하여 집계
agg_all = group.agg(["min","max"])
print(agg_all.head())
print("\n")
# 각 열마다 다른 함수를 적용하여 집계
agg_sep = grouped.agg({"fare":["min","max"], "age":"mean"})
print(agg_sep.head())
2) 그룹연산 메소드
* 그룹 객체 함수 적용 // 여러 개의 함수를 적용

# 그룹 객체 함수 적용
# 내장 함수
grouped = df.groupby("class")
grouped_sd = grouped.std()
print(grouped_sd)
print(type(grouped_sd))
age_sd = grouped.age.std()
print(age_sd)
print(type(age_sd))
# 사용자 정의 함수 생성
def range_xy(x):
return x.max() - x.min()
grouped.agg(range_xy)
# 여러 개의 함수를 동시에 적용
grouped.agg(["max", "min"])
# 여러 개의 함수 & 내가 원하는 열에
grouped.agg({"age": ["max", "min"], "fare": "mean"})
* 그룹 연산 데이터 변환 // 그룹 객체의 age 열을 iteration으로 z-score를 계산하여 출력

# %%
# 그룹 연산 데이터 변환
# 그룹별 age 열의 평균 집계 연산
age_mean = grouped.age.mean()
print(age_mean)
print("\n")
# 그룹별 age 열의 표준편차 집계 연산
age_std = grouped.age.std()
print(age_std)
print("\n")
# 그룹 객체의 age 열을 iteration으로 z-score를 계산하여 출력
for key, group in grouped.age:
group_zscore = (group - age_mean.loc[key])/age_std.loc[key]
print("* origin :",key)
print(group_zscore.head(3)) # 각 그룹의 첫 3개의 행 출력
print("\n")
* 그룹 연산 데이터 변환 // transform 메소드 반환 값

# %%
# 그룹 연산 데이터 변환
# z-score를 계산하는 사용자 함수 정의
def z_score(x):
return (x-x.mean()/x.std())
age_zscore = grouped.age.apply(z_score)
print(age_zscore.loc[[1,9,0]]) # 1,2,3 그룹의 첫 데이터 확인(변환 결과)
print("n")
print(len(age_zscore)) # transform 메소드 반환 값의 길이
print("n")
print(age_zscore.loc[0:9]) # transform 메소드 반환 값 출력(첫 10개)
print("n")
print(type(age_zscore)) # transform 메소드 반환 객체의 자료형
* 그룹 객체 필터링

# %%
# 그룹 객체 필터링
# 데이터 개수가 200개 이상인 그룹만을 필터링하여 데이터프레임으로 변환
grouped_filter = grouped.filter(lambda x: len(x) > 200)
print(grouped_filter.head())
print("\n")
print(type(grouped_filter))
# age 열의 평균이 30보다 작은 그룹만을 필터링하여 데이터프레임으로 반환
age_filter = grouped.filter(lambda x: x.age.mean() < 30)
print(age_filter.tail())
print("\n")
print(age_filter)
* 그룹 객체에 함수 매핑

# %%
# 그룹 객체에 함수 매핑
# 집계: 각 그룹별 요약 통계 정보 집계
age_grouped = grouped.apply(lambda x: x.describe())
print(age_grouped)
# z_score를 계산하는 사용자 함수 정의
def z_score(x):
return (x-x.mean())/x.std()
age_zscore = grouped.age.apply(z_score)
print(age_zscore.head()) # 1,2,3 그룹의 첫 데이터 확인(변환 결과)
* 필터링 2

# %%
# 필터링 : age 열의 데이터 평균이 30보다 작은 그룹만을 필터링하여 출력
age_filter = grouped.apply(lambda x: x.age.mean() < 30)
print(age_filter)
print("\n")
for x in age_filter.index:
if age_filter[x]==True:
age_filter_df=grouped.get_group(x)
print(age_filter_df.head())
print("\n")
4. 멀티 인덱스
* 분할, 그룹 객체에 연산 메소드 적용 // 특정 행 선택하여 출력

# %%
# 6장 멀티 인덱스
# claas 열, sex열을 기준으로 분할
grouped=df.groupby(["class","sex"])
# 그룹 객체에 연산 메소드 적용
gdf=grouped.mean()
print(gdf)
print("\n")
print(type(gdf))
# %%
# class 값이 First인 행을 선택하여 출력
print(gdf.loc["First"])
# class 값이 First이고, sex 값이 female인 행을 선택하여 출력
print(gdf.loc["First","female"])
# sex 값이 male인 행을 선택하여 출력
print(gdf.xs("male",level="sex"))
* # 그룹 연산 메소드(적용-결합 단계) // 데이터 집계 // 데이터프레임 반환, 시리즈 반환

# %%
# 그룹 연산 메소드(적용-결합 단계)
# 데이터 집계
titanic = sns.load_dataset("titanic")
df = titanic.loc[:, ["age","sex","class","fare","survived"]]
# class 열을 기준으로 분할
grouped = df.groupby(["class"])
# 각 그룹에 대한 모든 열의 표준편차를 집계하여 데이터프레임으로 반환
std_all = grouped.std()
print(std_all)
print("\n")
print(type(std_all))
print("\n")
# 각 그룹에 대한 fare 열의 표준편차를 집계하여 시리즈로 반환
std_fare = grouped.fare.std()
print(std_fare)
print("\n")
print(type(std_fare))
print("\n")
* 그룹 연산 데이터 변환

# %%
# 그룹 연산 데이터 변환
# z-score를 계산하는 사용자 함수 정의
def z_score(x):
return (x-x.mean()/x.std())
age_zscore = grouped.age.apply(z_score)
print(age_zscore.loc[[1,9,0]]) # 1,2,3 그룹의 첫 데이터 확인(변환 결과)
print("n")
print(len(age_zscore)) # transform 메소드 반환 값의 길이
print("n")
print(age_zscore.loc[0:9]) # transform 메소드 반환 값 출력(첫 10개)
print("n")
print(type(age_zscore)) # transform 메소드 반환 객체의 자료형
5. 피벗
* 피벗테이블 생성, 구조 확인


# %%
# 피벗
# 피벗테이블
# Ipyhton 디스플레이 설정 변경
pd.set_option("display.max_columns", 10) # 출력할 최대 열의 개수
pd.set_option("display.max_colwidth", 20) # 출력할 열의 너비
# titanic 데이터셋에서 age, sex 등 5개 열을 선택하여 데이터프레임 만들기
titanic = sns.load_dataset("titanic")
df = titanic.loc[:, ["age","sex","class","fare","survived"]]
print(df.head())
print("\n")
# 행, 열, 값 집계에 사용할 열을 1개씩 지정 - 평균 집계
pdf1=pd.pivot_table(df,
index="class", # 행 위치에 들어갈 열
columns="sex", # 열 위치에 들어갈 열
values="age", # 데이터로 사용할 열
aggfunc="mean") # 데이터 집계 함수
# 피벗테이블
# 값에 적용하는 집계 함수 2개 이상 지정 가능 - 생존율, 생존자 수 집계
pdf2=pd.pivot_table(df,
index="class", # 행 위치에 들어갈 열
columns="sex", # 열 위치에 들어갈 열
values="survived", # 데이터로 사용할 열
aggfunc=["mean","sum"]) # 데이터 집계 함수
print(pdf2.head())
# 행, 열, 값에 사용할 열을 2개 이상 지정 가능 - 평균 나이, 최대 요금 집계
pdf3=pd.pivot_table(df, # 피벗할 데이터프레임
index=["class","sex"], # 행 위치에 들어갈 열
columns="survived", # 열 위치에 들어갈 열
values=["age","fare"], # 데이터로 사용할 열
aggfunc=["mean","max"]) # 데이터 집계 함수
# Ipython console 디스플레이 옵션 설정
pd.set_option("display.max_columns", 10) # 출력할 열의 최대 개수
print(pdf3.head())
print("\n")
# 행, 열 구조 살펴보기
print(pdf3.index)
print(pdf3.columns)
* xs 인덱서 사용 - 행 선택

# %%
# xs 인덱서 사용 - 행 선택(default: axis=0)
print(pdf3.xs("First"))
print(pdf3.xs(("First","female"))) # 행 인덱스가 ("First","female)인 행을 선택
* 인덱스 행 선택
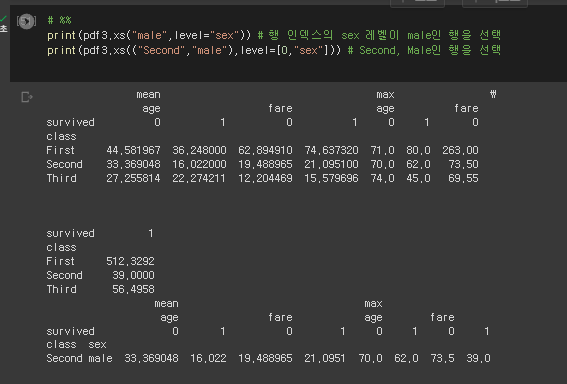
# %%
print(pdf3.xs("male",level="sex")) # 행 인덱스의 sex 레벨이 male인 행을 선택
print(pdf3.xs(("Second","male"),level=[0,"sex"])) # Second, Male인 행을 선택
* xs 인덱서 사용해서 열 선택
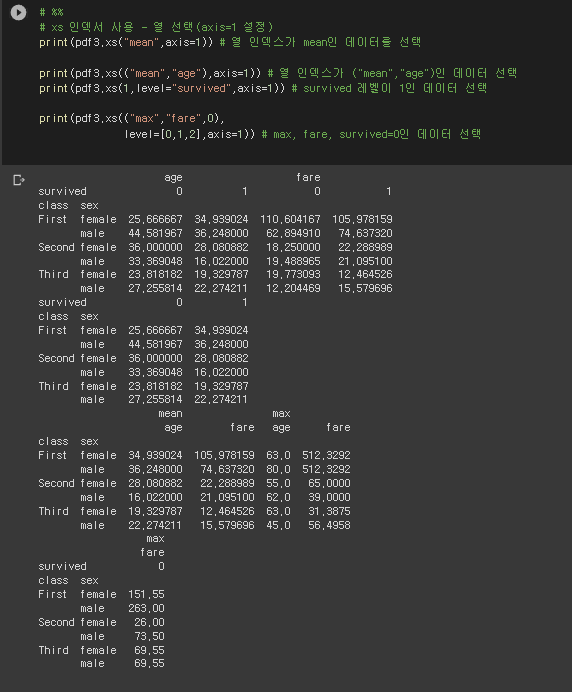
# %%
# xs 인덱서 사용 - 열 선택(axis=1 설정)
print(pdf3.xs("mean",axis=1)) # 열 인덱스가 mean인 데이터를 선택
print(pdf3.xs(("mean","age"),axis=1)) # 열 인덱스가 ("mean","age")인 데이터 선택
print(pdf3.xs(1,level="survived",axis=1)) # survived 레벨이 1인 데이터 선택
print(pdf3.xs(("max","fare",0),
level=[0,1,2],axis=1)) # max, fare, survived=0인 데이터 선택7장 머신러닝
0. 머신러닝에 대해
1) 머신러닝에 대해
기계 : Computer (알고리즘)
학습 : 데이터 속 의미 (관계)
* 머신러닝의 목적
- 예측 (회귀(어떤 숫자인지), 분류) => 정답이 있음 => 지도학습
- 군집(cluster) => 정답x => 비지도 학습
* 머신러닝 데이터 분석 과정
(1) 데이터 준비, 정리 => 속성 (피처,변수,열)
(2) 데이터 분할 => 훈련 / 테스트 데이터로 나뉨 (자주 사용 되는 비율 8:2)
(3) 문제 해결 => 알고리즘 준비
(4) 모형 학습 훈련
(5) 모형 평가
(6) 모형 활용 (실무 새로운 데이터) => 문제 해결
* 회귀 모델의 종류 (공통점으로는 y변수가 전부 1개임)
단순 회귀 모델 : x - 1개
다항 회귀 모델 : x - x제곱
다중 회귀 모델 : x - 2개 이상
- y에는 연속형 변수가 옴.
1. 지도학습
1-1. 단순회귀
* 데이터 준비

# 7장 머신러닝
# 데이터 준비
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# CSV 파일을 데이터프레임으로 변환
df = pd.read_csv(r"/content/drive/MyDrive/BDA/part3/auto-mpg.csv", header=None)
df.columns=["mpg","cylinders","displacement","horsepower","weight",
"acceleration","model year","origin","name"]
print(df.head())
print("\n")
# Ipython 디스플레이 설정 - 출력할 열의 개수 한도 늘리기
pd.set_option("display.max_columns", 10) # 출력할 열의 최대 개수
print(df.head())
* 데이터 탐색

# %%
# 데이터 탐색
# 데이터 자료형 확인
print(df.info())
print("\n")
# 데이터 통계 요약 정보 확인
print(df.describe())
* 단순회귀분석 시작 (전처리)

# %%
# 단순회귀분석
# horsepower 열의 자료형 변경(문자열 -> 숫자)
print(df["horsepower"].unique()) #horse power열의 고유값 확인
print("\n")
df["horsepower"].replace("?",np.nan,inplace=True) # ?을 np.nan으로 변경
df.dropna(subset=["horsepower"],axis=0,inplace=True) #누락 데이터 행 삭제
df["horsepower"]= df["horsepower"].astype("float") # 문자열을 실수형으로 변환
print(df.describe())
* 속성 선택

# %%
# 속성 선택
# 속성 (feature 또는 variable) 선택
# 분석에 활용할 열(속성) 선택(연비, 실린더, 출력, 중량)
ndf=df[["mpg","cylinders","horsepower","weight"]]
print(ndf.head())
# 종속 변수 Y인 "연비(mpg)"와 다른 변수 간의 선형관계를 그래프(산점도)로 확인
# Matplotlib으로 산점도 그리기
ndf.plot(kind="scatter", x="weight", y="mpg", c="coral", s=10, figsize=(10,5))
plt.show()
plt.close()
* 산점도 그리기

# %%
# seaborn으로 산점도 그리기
fig = plt.figure(figsize=(10,5))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
sns.regplot(x="weight",y="mpg", data=ndf, ax=ax1) # 회귀선 표시
sns.regplot(x="weight",y="mpg",data=ndf, ax=ax2,fit_reg=False,color="coral") #회귀선 미표시
plt.show()
plt.close()
* seaborn 조인트 그래프 - 산점도, 히스토그램


# %%
# seaborn 조인트 그래프 - 산점도, 히스토그램
sns.jointplot(x="weight", y="mpg", data=ndf) # 회귀선 없음
sns.jointplot(x="weight", y="mpg", data=ndf, kind="reg") # 회귀선 표시
plt.show()
plt.close()
* 두 변수 간의 모든 경우의 수 그래프 생성

# %%
# seaborn pariplot으로 두 변수 간의 모든 경우의 수 그리기
grid_ndf = sns.pairplot(ndf)
plt.show()
plt.close()
* train data, test data 개수 체크 // 모형 학습

# %%
# 속성(변수) 선택
X=ndf[["weight"]] # 독립 변수 X
y=ndf["mpg"] # 종속 변수 Y
# train data와 test data로 구분(7:3 비율)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, # 독립 변수
Y, # 종속 변수
test_size=0.3, # 검증 30%
random_state=10) # 랜덤 추출 값
print("train data 개수: ", len(X_train))
print("test data 개수: ", len(X_test))
# %%
# 단순회귀분석 모형 만들기 - sklearn 사용
# sklearn 라이브러리에서 선형회귀분석 모듈 가져오기
from sklearn.linear_model import LinearRegression
# 단순회귀분석 모형 객체 생성
lr = LinearRegression()
# train data를 가지고 모형 학습
lr.fit(X_train, y_train)
# 학습을 마친 모형에 test data를 적용하여 결정계수(R-제곱) 계산
r_square= lr.score(X_test,y_test)
print(r_square)
* 회귀식의 기울기, y절편 구하기

# %%
# 회귀식의 기울기
print("기울기 a: ", lr.coef_)
# 회귀식의 y절편
print("y절편 b", lr.intercept_)
* 실제 y 값, 예측한 y 값 비교


# %%
# # 모형에 전체 X 데이터를 입력하여 예측한 값 y_hat을 실제 값 y와 비교
# y_hat = lr.predict(X)
# plt.figure(figsize=(10,5))
# ax1=sns.kdeplot(y,label="y")
# ax2=sns.kdeplot(y_hat, label="y_hat",ax=ax1)
# plt.legend()
# plt.show()
# # 모형에 전체 X 데이터를 입력하여 예측한 값 y_hat을 실제 값 y와 비교
y_hat = lr.predict(X)
plt.figure(figsize = (10, 5))
ax1 = sns.distplot(y, hist = False, label = "y")
# # 실제 y값
ax2 = sns.distplot(y_hat, hist = False, label ="y_hat", ax = ax1)
# 예측한 y값
plt.legend()
plt.show()
1-2. 다항회귀분석
* 준비부터 훈련 데이터, 검증 데이터 확인까지

# %%
# 다항회귀분석
# 기본 라이브러리 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# %%
# 다항 회귀분석
# CSV 파일을 데이터프레임으로 변환
df = pd.read_csv(r"/content/drive/MyDrive/BDA/part3/auto-mpg.csv", header=None)
# 열 이름 지정
df.columns=["mpg","cylinders","displacement","horsepower","weight",
"acceleration","model year","origin","name"]
# horsepower 열의 자료형 변경(문자열 -> 숫자)
df["horsepower"].replace("?",np.nan,inplace=True) #?을 np.nan으로 변경
df.dropna(subset=["horsepower"],axis=0,inplace=True) #누락 데이터 행 삭제
df["horsepower"]= df["horsepower"].astype("float") # 문자열을 실수형으로 변환
# 분석에 활용할 열(속성) 선택(연비, 실린더, 출력, 중량)
ndf = df[["mpg","cylinders","horsepower","weight"]]
# ndf 데이터를 train data와 test data로 구분(7:3 비율)
X=ndf[["weight"]] # 독립 변수 X
y=ndf["mpg"] # 종속 변수 y
# train data와 test data로 구분(7:3 비율)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3,random_state=10)
print("훈련 데이터: ", X_train.shape)
print("검증 데이터: ", X_test.shape)
* 다항 회귀 분석 시작 (원 데이터, 2차항 변환 데이터 확인) // 모형 학습까지

# %%
# 다항 회귀 분석
# 비선형회귀분석 모형 - sklearn 사용
from sklearn.linear_model import LinearRegression # 선형회귀분석
from sklearn.preprocessing import PolynomialFeatures # 다항식 변환
# 다항식 변환
poly = PolynomialFeatures(degree=2) # 2차항 적용
X_train_poly=poly.fit_transform(X_train) # X_train 데이터를 2차항으로 변형
print("원 데이터: ", X_train.shape)
print("2차항 변환 데이터: ", X_train_poly.shape)
# %%
# train data를 가지고 모형 학습
pr = LinearRegression()
pr.fit(X_train_poly, y_train)
# 학습을 마친 모형에 test data를 적용하여 결정계수(R-제곱) 계산
x_test_poly=poly.fit_transform(X_test) # X_test 데이터를 2차항으로 변형
r_square = pr.score(x_test_poly, y_test)
print(r_square)
* train data의 산점도와 test data로 예측한 회귀선을 그래프로 출력

# %%
# train data의 산점도와 test data로 예측한 회귀선을 그래프로 출력
y_hat_test = pr.predict(x_test_poly)
fig = plt.figure(figsize=(10,5))
ax = fig.add_subplot(1,1,1)
ax.plot(X_train,y_train,'o',label="Train data") # 데이터 분포
ax.plot(X_test,y_hat_test,'r+',label="Predicted Value") # 모형이 학습한 회귀선
ax.legend(loc="best")
plt.xlabel("weight")
plt.ylabel("mpg")
plt.show()
plt.close()
* 실제 값과 예측 값 비교

# %%
# 모형에 전체 X 데이터를 입력하여 예측한 값 y_hat을 실제 값 y와 비교
X_ploy = poly.fit_transform(X)
y_hat = pr.predict(X_ploy)
plt.figure(figsize=(10,5))
ax1 = sns.kdeplot(y,label="y")
ax2 = sns.kdeplot(y_hat, label="y_hat",ax=ax1)
# ax1 = sns.distplot(y, hist = False, label = "y")
# ax2 = sns.distplot(y_hat, hist = False, label ="y_hat", ax = ax1)
plt.legend()
plt.show()
* 핵심
- 데이터프레임 병합&결합(join,merge), 그룹 연산 분할, 그룹연산 메소드, 필터링, 매핑,
멀티 인덱스, 피벗 테이블 사용법 이해하기
- 머신러닝 이해하기 : 지도학습과 비지도학습의 차이점, 모형 학습의 의미와 실제값과 예측값의 비교 분석
* 링크 (생성한 계정만 이용 가능)
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
* 학습 링크 (0429 py) ** 원래는 0501인데 제목 잘못 됨.
guromd1
guromd1.blogspot.com
'배운 책들 정리 > 파이썬 머신러닝 판다스 데이터분석' 카테고리의 다른 글
| 파이썬 머신러닝 판다스 데이터 분석 7-3 - 머신러닝 데이터 분석 - 시그모이드 함수의 식, 로지스틱 회귀, 교차검증 (0) | 2023.05.03 |
|---|---|
| 파이썬 머신러닝 판다스 데이터 분석 7-3 질문 - 머신러닝 데이터 분석, 로지스틱 회귀, 교차검증 (0) | 2023.05.03 |
| 파이썬 머신러닝 판다스 데이터 분석 5,6 - 데이터 사전 처리, 데이터프레임의 다양한 응용 (0) | 2023.04.28 |
| 파이썬 머신러닝 판다스 데이터 분석 4_3, 5 - 시각화, 데이터 사전 처리 (0) | 2023.04.27 |
| 파이썬 머신러닝 판다스 데이터 분석 4_2 - 시각화 (0) | 2023.04.26 |



