1장 판다스 입문
1. 산술연산
1) 산술연산
* 객체 산술연산

# 판다스 객체 산술연산
# 시리즈 & 숫자
import pandas as pd
# 딕셔너리 => 시리즈
student1 = pd.Series({"국어":80,
"영어":90,
"수학":70})
print(student1)
student1_modify = student1+10
print(student1_modify)
print(type(student1_modify))
* 카테고리 위치가 바뀔 경우
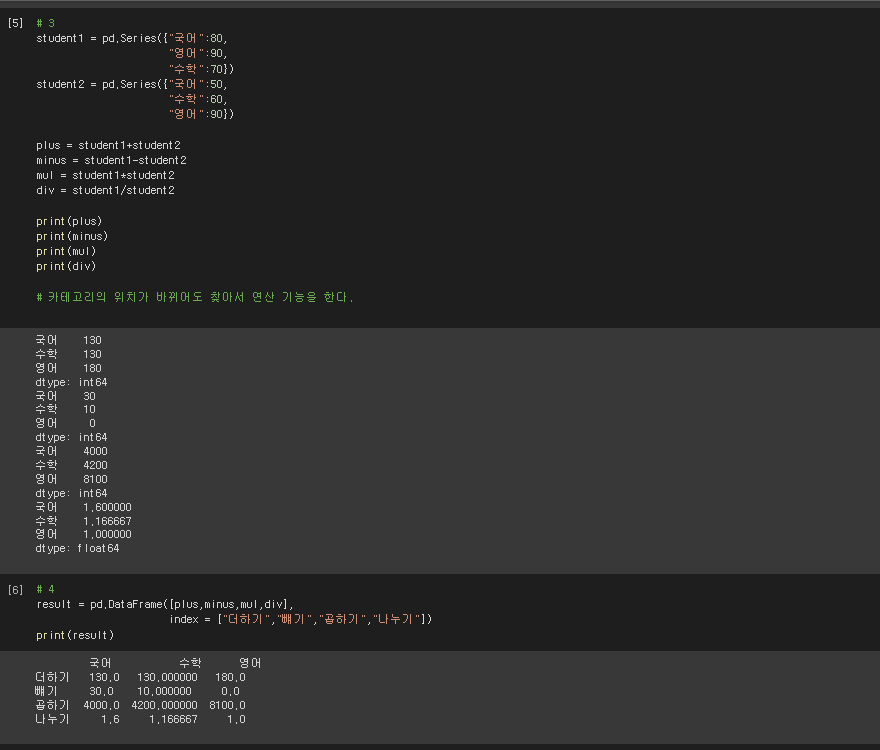
# 3
student1 = pd.Series({"국어":80,
"영어":90,
"수학":70})
student2 = pd.Series({"국어":50,
"수학":60,
"영어":90})
plus = student1+student2
minus = student1-student2
mul = student1*student2
div = student1/student2
print(plus)
print(minus)
print(mul)
print(div)
# 카테고리의 위치가 바뀌어도 찾아서 연산 기능을 한다.
# 4
result = pd.DataFrame([plus,minus,mul,div],
index = ["더하기","뺴기","곱하기","나누기"])
print(result)
* numpy를 사용할 경우 (NAN값의 처리)
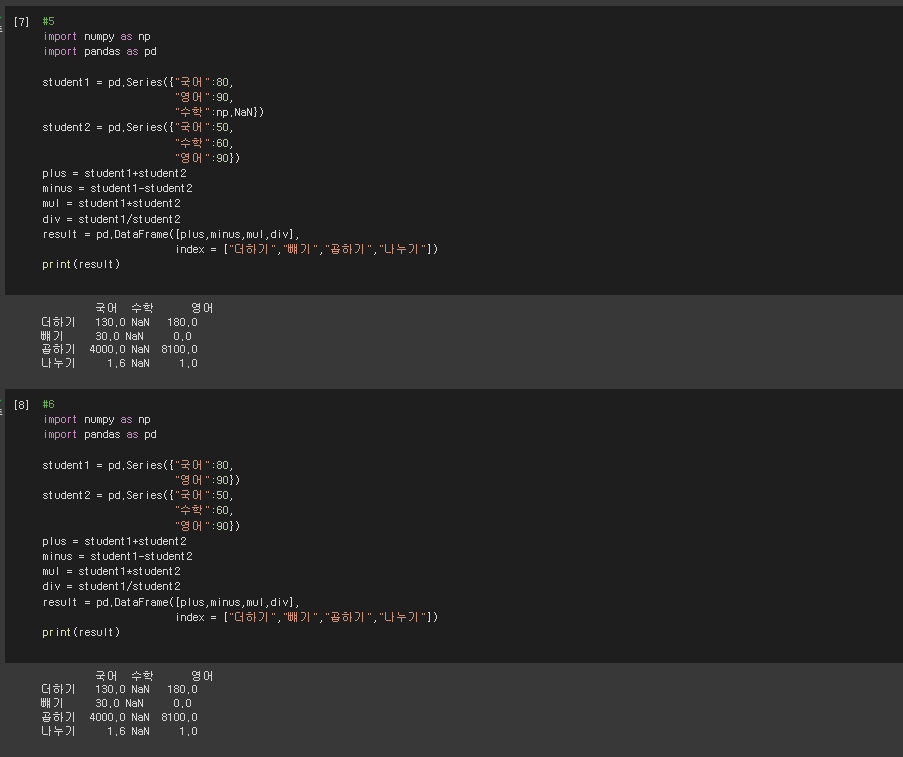
#5
import numpy as np
import pandas as pd
student1 = pd.Series({"국어":80,
"영어":90,
"수학":np.NaN})
student2 = pd.Series({"국어":50,
"수학":60,
"영어":90})
plus = student1+student2
minus = student1-student2
mul = student1*student2
div = student1/student2
result = pd.DataFrame([plus,minus,mul,div],
index = ["더하기","뺴기","곱하기","나누기"])
print(result)
#6
import numpy as np
import pandas as pd
student1 = pd.Series({"국어":80,
"영어":90})
student2 = pd.Series({"국어":50,
"수학":60,
"영어":90})
plus = student1+student2
minus = student1-student2
mul = student1*student2
div = student1/student2
result = pd.DataFrame([plus,minus,mul,div],
index = ["더하기","뺴기","곱하기","나누기"])
print(result)
* 함수를 사용할 경우
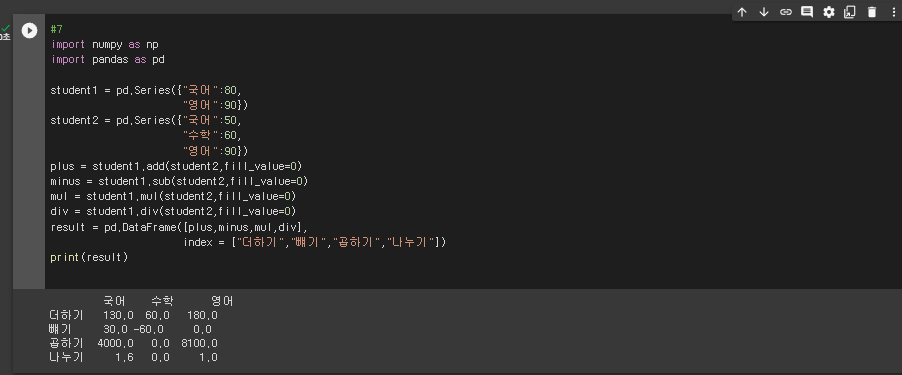
#7
import numpy as np
import pandas as pd
student1 = pd.Series({"국어":80,
"영어":90})
student2 = pd.Series({"국어":50,
"수학":60,
"영어":90})
plus = student1.add(student2,fill_value=0)
minus = student1.sub(student2,fill_value=0)
mul = student1.mul(student2,fill_value=0)
div = student1.div(student2,fill_value=0)
result = pd.DataFrame([plus,minus,mul,div],
index = ["더하기","뺴기","곱하기","나누기"])
print(result)
* 무한대가 되는 경우 // 타이타닉 데이터 불러오기
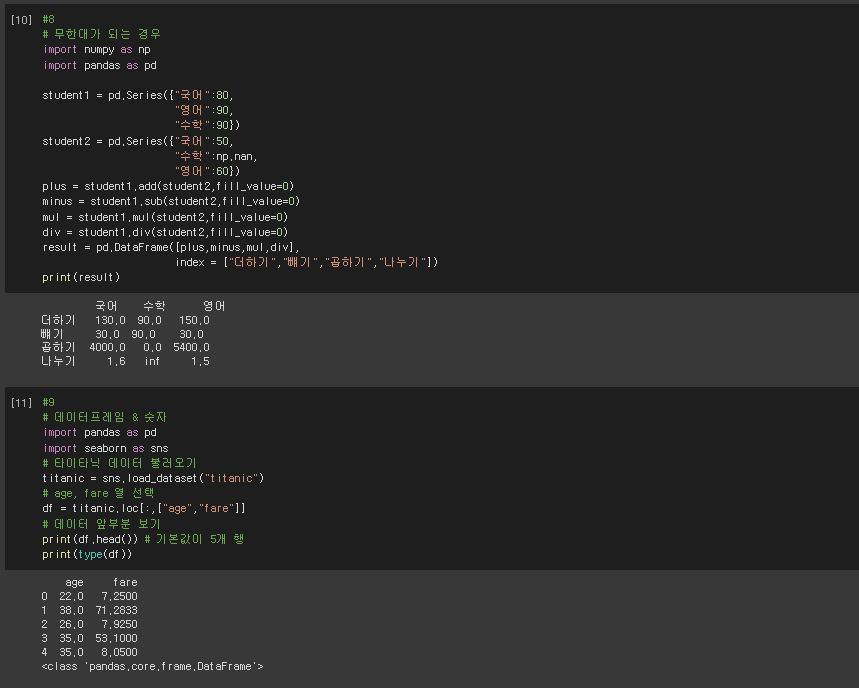
#8
# 무한대가 되는 경우
import numpy as np
import pandas as pd
student1 = pd.Series({"국어":80,
"영어":90,
"수학":90})
student2 = pd.Series({"국어":50,
"수학":np.nan,
"영어":60})
plus = student1.add(student2,fill_value=0)
minus = student1.sub(student2,fill_value=0)
mul = student1.mul(student2,fill_value=0)
div = student1.div(student2,fill_value=0)
result = pd.DataFrame([plus,minus,mul,div],
index = ["더하기","뺴기","곱하기","나누기"])
print(result)
#9
# 데이터프레임 & 숫자
import pandas as pd
import seaborn as sns
# 타이타닉 데이터 불러오기
titanic = sns.load_dataset("titanic")
# age, fare 열 선택
df = titanic.loc[:,["age","fare"]]
# 데이터 앞부분 보기
print(df.head()) # 기본값이 5개 행
print(type(df))
* 타이타닉 데이터 조작하기 (데이터 프레임)
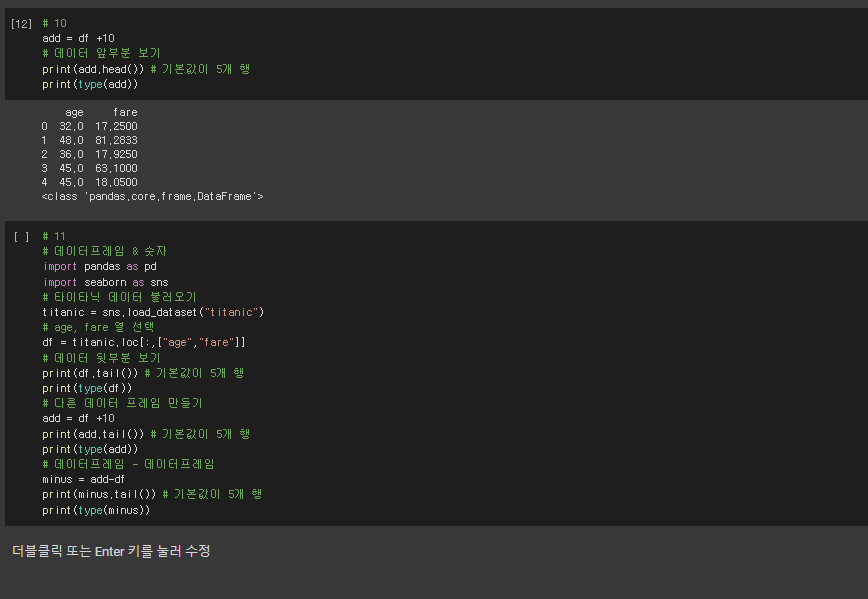
# 10
add = df +10
# 데이터 앞부분 보기
print(add.head()) # 기본값이 5개 행
print(type(add))
# 11
# 데이터프레임 & 숫자
import pandas as pd
import seaborn as sns
# 타이타닉 데이터 불러오기
titanic = sns.load_dataset("titanic")
# age, fare 열 선택
df = titanic.loc[:,["age","fare"]]
# 데이터 뒷부분 보기
print(df.tail()) # 기본값이 5개 행
print(type(df))
# 다른 데이터 프레임 만들기
add = df +10
print(add.tail()) # 기본값이 5개 행
print(type(add))
# 데이터프레임 - 데이터프레임
minus = add-df
print(minus.tail()) # 기본값이 5개 행
print(type(minus))
2장 데이터 입출력
1. 데이터 입출력
1) 데이터 불러오기
* CSV 파일 불러오기
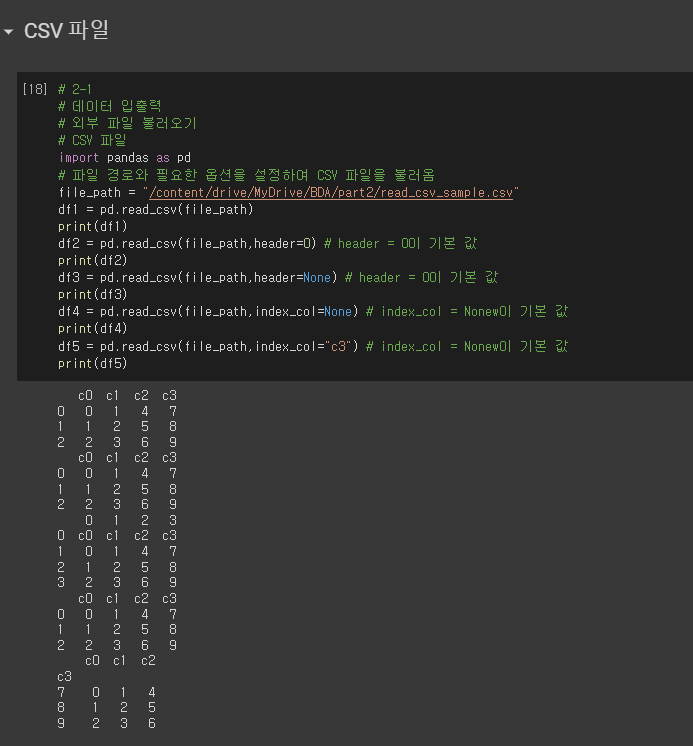
# 2-1
# 데이터 입출력
# 외부 파일 불러오기
# CSV 파일
import pandas as pd
# 파일 경로와 필요한 옵션을 설정하여 CSV 파일을 불러옴
file_path = "/content/drive/MyDrive/BDA/part2/read_csv_sample.csv"
df1 = pd.read_csv(file_path)
print(df1)
df2 = pd.read_csv(file_path,header=0) # header = 0이 기본 값
print(df2)
df3 = pd.read_csv(file_path,header=None) # header = 0이 기본 값
print(df3)
df4 = pd.read_csv(file_path,index_col=None) # index_col = Nonew이 기본 값
print(df4)
df5 = pd.read_csv(file_path,index_col="c3") # index_col = Nonew이 기본 값
print(df5)
* xlsx 형태로 불러와서 다양하게 입력값 넣기.
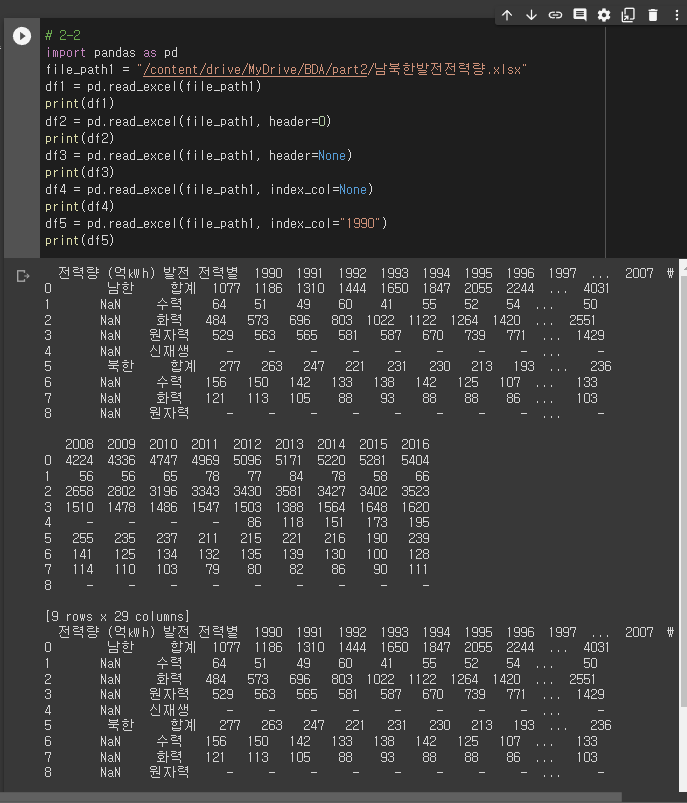
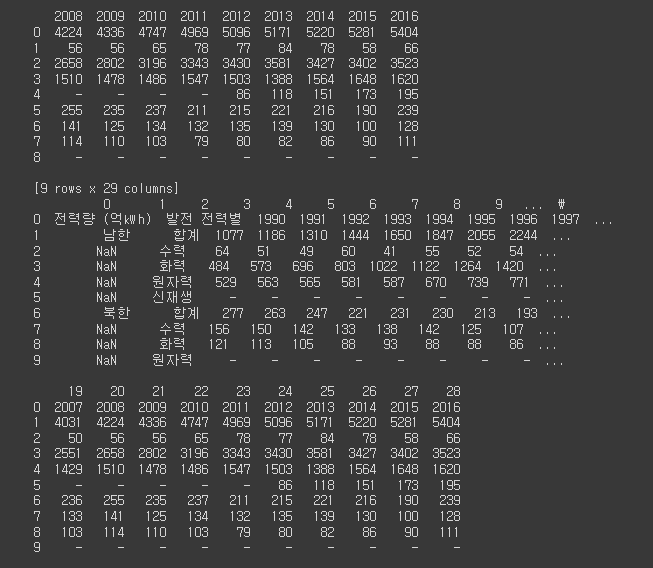
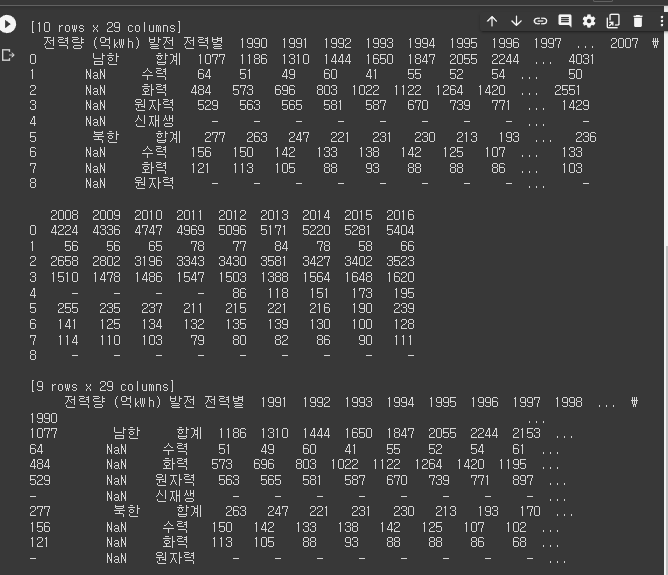
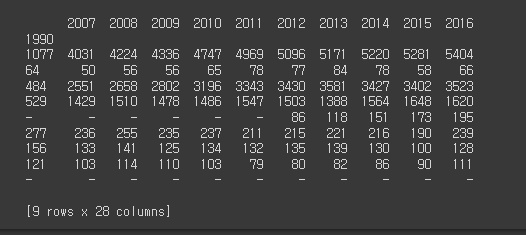
# 2-2
import pandas as pd
file_path1 = "/content/drive/MyDrive/BDA/part2/남북한발전전력량.xlsx"
df1 = pd.read_excel(file_path1)
print(df1)
df2 = pd.read_excel(file_path1, header=0)
print(df2)
df3 = pd.read_excel(file_path1, header=None)
print(df3)
df4 = pd.read_excel(file_path1, index_col=None)
print(df4)
df5 = pd.read_excel(file_path1, index_col="1990")
print(df5)
* engine = None 기본 값을 넣을 경우
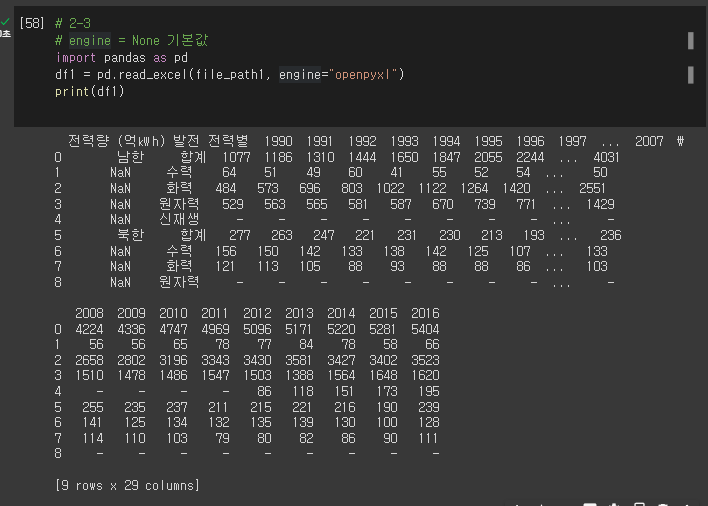
# 2-3
# engine = None 기본값
import pandas as pd
df1 = pd.read_excel(file_path1, engine="openpyxl")
print(df1)
* JSON 파일 불러오기
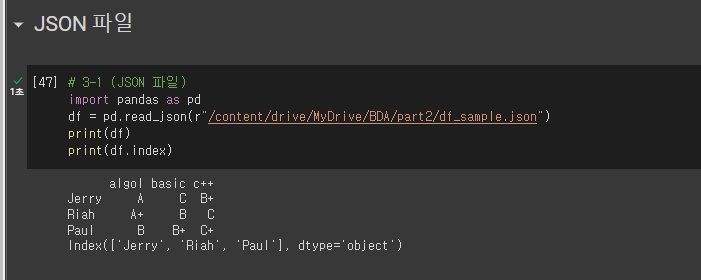
# 3-1 (JSON 파일)
import pandas as pd
df = pd.read_json(r"/content/drive/MyDrive/BDA/part2/df_sample.json")
print(df)
print(df.index)
2) 데이터 저장하기
* CSV 파일 저장하기
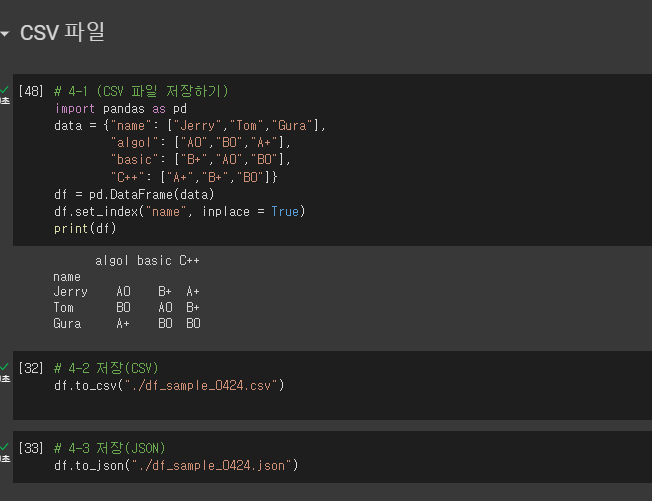
# 4-1 (CSV 파일 저장하기)
import pandas as pd
data = {"name": ["Jerry","Tom","Gura"],
"algol": ["A0","B0","A+"],
"basic": ["B+","A0","B0"],
"C++": ["A+","B+","B0"]}
df = pd.DataFrame(data)
df.set_index("name", inplace = True)
print(df)
# 4-2 저장(CSV)
df.to_csv("./df_sample_0424.csv")
# 4-3 저장(JSON)
df.to_json("./df_sample_0424.json")
* 여러 개의 데이터 프레임을 하나의 엑셀 파일로 저장
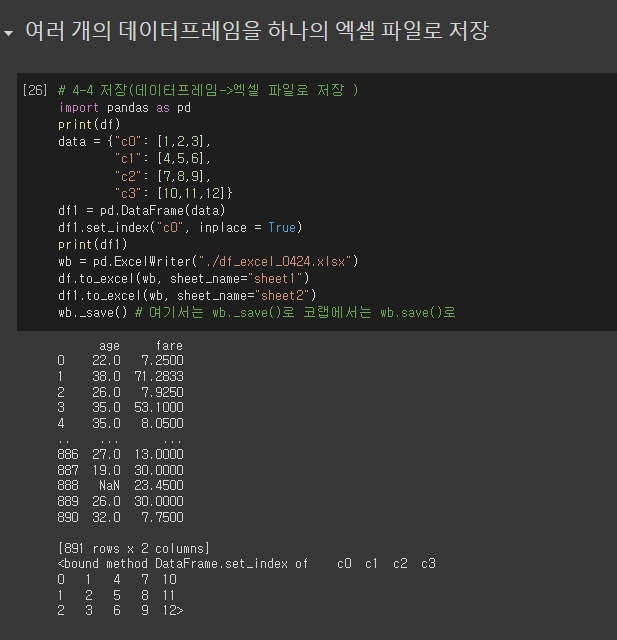
# 4-4 저장(데이터프레임->엑셀 파일로 저장 )
import pandas as pd
print(df)
data = {"c0": [1,2,3],
"c1": [4,5,6],
"c2": [7,8,9],
"c3": [10,11,12]}
df1 = pd.DataFrame(data)
df1.set_index("c0", inplace = True)
print(df1)
wb = pd.ExcelWriter("./df_excel_0424.xlsx")
df.to_excel(wb, sheet_name="sheet1")
df1.to_excel(wb, sheet_name="sheet2")
wb._save() # 여기서는 wb._save()로 코랩에서는 wb.save()로
* HTML 표 가져오기
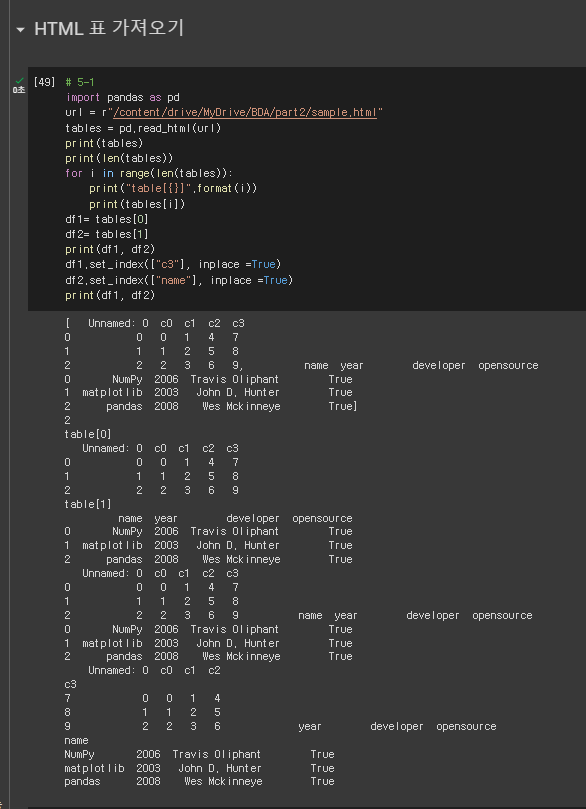
# 5-1
import pandas as pd
url = r"/content/drive/MyDrive/BDA/part2/sample.html"
tables = pd.read_html(url)
print(tables)
print(len(tables))
for i in range(len(tables)):
print("table[{}]".format(i))
print(tables[i])
df1= tables[0]
df2= tables[1]
print(df1, df2)
df1.set_index(["c3"], inplace =True)
df2.set_index(["name"], inplace =True)
print(df1, df2)
3) 지오 코딩하기 (구글 MAP API를 통해)
* 위키피디아 ETF 리스트 가져오기 (웹 스크래핑)
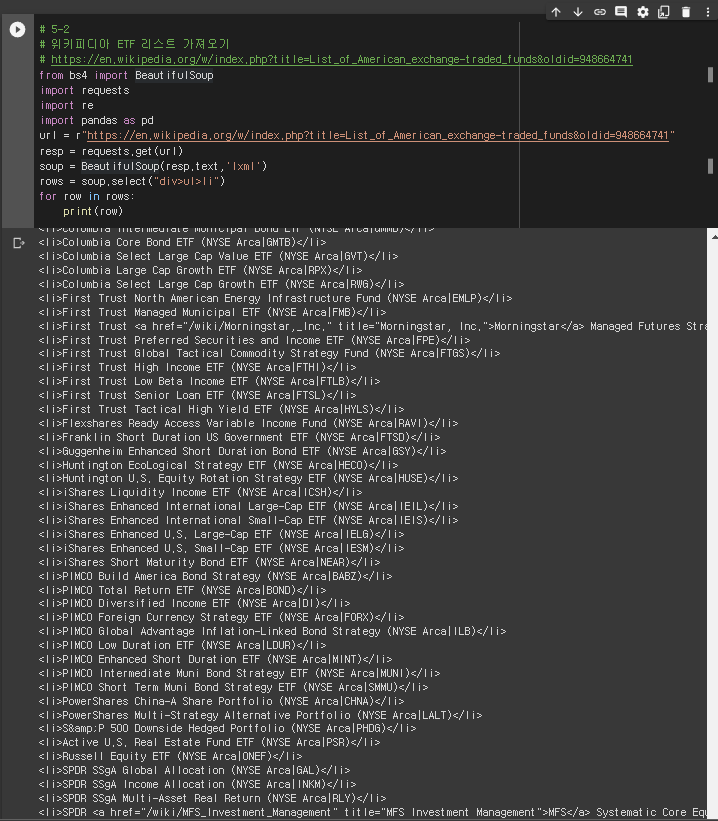
# 5-2
# 위키피디아 ETF 리스트 가져오기
# https://en.wikipedia.org/w/index.php?title=List_of_American_exchange-traded_funds&oldid=948664741
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
url = r"https://en.wikipedia.org/w/index.php?title=List_of_American_exchange-traded_funds&oldid=948664741"
resp = requests.get(url)
soup = BeautifulSoup(resp.text,'lxml')
rows = soup.select("div>ul>li")
for row in rows:
print(row)
* 위키피디아 ETF 리스트 가져와서 원하는 형태로 출력
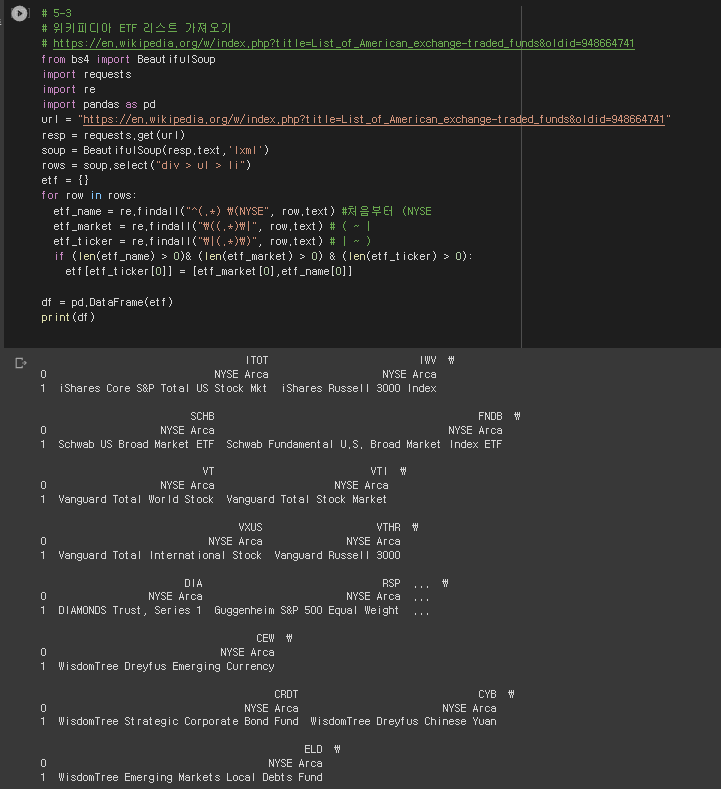
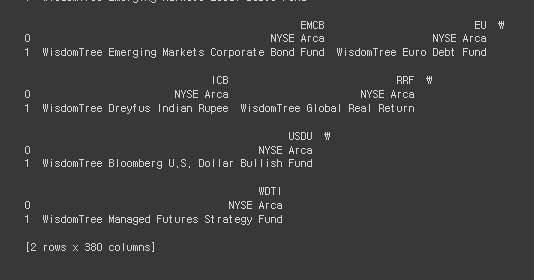
# 5-3
# 위키피디아 ETF 리스트 가져오기
# https://en.wikipedia.org/w/index.php?title=List_of_American_exchange-traded_funds&oldid=948664741
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
url = "https://en.wikipedia.org/w/index.php?title=List_of_American_exchange-traded_funds&oldid=948664741"
resp = requests.get(url)
soup = BeautifulSoup(resp.text,'lxml')
rows = soup.select("div > ul > li")
etf = {}
for row in rows:
etf_name = re.findall("^(.*) \(NYSE", row.text) #처음부터 (NYSE
etf_market = re.findall("\((.*)\|", row.text) # ( ~ |
etf_ticker = re.findall("\|(.*)\)", row.text) # | ~ )
if (len(etf_name) > 0)& (len(etf_market) > 0) & (len(etf_ticker) > 0):
etf[etf_ticker[0]] = [etf_market[0],etf_name[0]]
df = pd.DataFrame(etf)
print(df)
3) 지오 코딩하기2 (API 이용하여 지오코딩)
* 구글맵스 객체 생성부터 get 이용까지
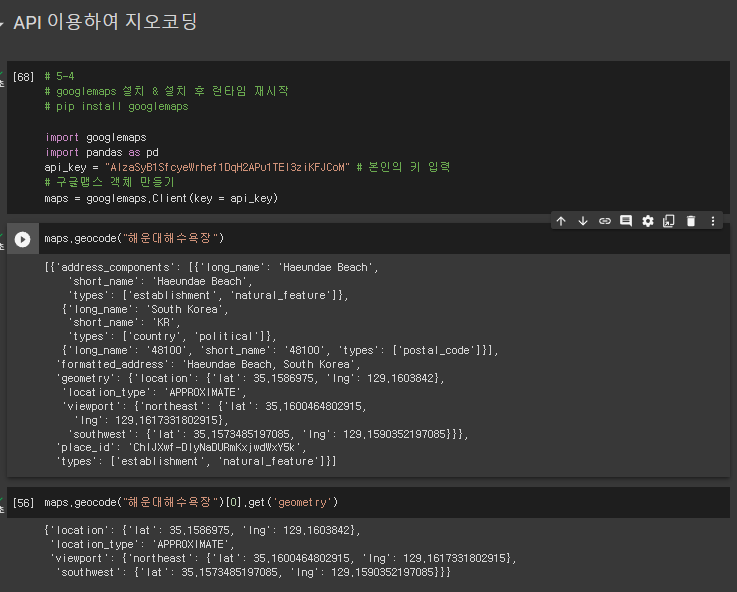
# 5-4
# googlemaps 설치 & 설치 후 런타임 재시작
# pip install googlemaps
import googlemaps
import pandas as pd
api_key = "AIzaSyB1SfcyeWrhef1DqH2APu1TEl3ziKFJCoM" # 본인의 키 입력
# 구글맵스 객체 만들기
maps = googlemaps.Client(key = api_key)
maps.geocode("해운대해수욕장")
maps.geocode("해운대해수욕장")[0].get('geometry')
* 뽑아야 할 정보를 확인 (여기서는 geometry를 주목)
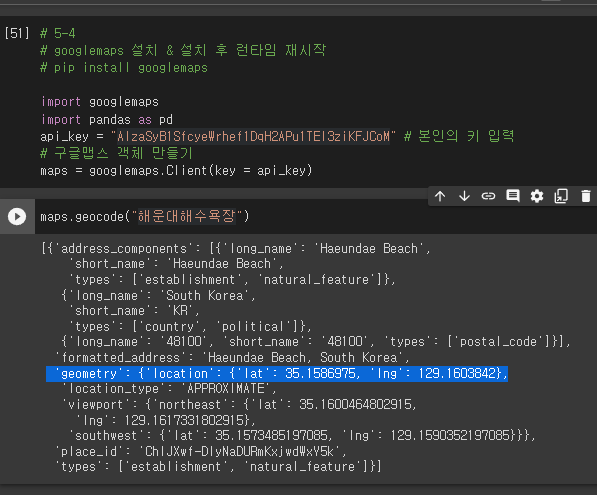
* 경도, 위도 출력
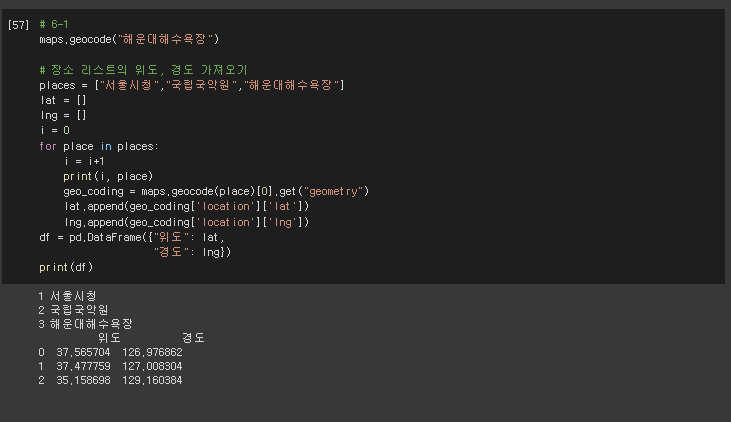
# 6-1
maps.geocode("해운대해수욕장")
# 장소 리스트의 위도, 경도 가져오기
places = ["서울시청","국립국악원","해운대해수욕장"]
lat = []
lng = []
i = 0
for place in places:
i = i+1
print(i, place)
geo_coding = maps.geocode(place)[0].get("geometry")
lat.append(geo_coding['location']['lat'])
lng.append(geo_coding['location']['lng'])
df = pd.DataFrame({"위도": lat,
"경도": lng})
print(df)
* 링크 (구글 api 따서 사용하는 법)
구글지도 api 사용하기
Google Maps API Google Maps Platform은 개발자가 모바일 앱 및 웹페이지에 Google 지도를 삽입하거나 Google 지도에서 데이터를 가져오기 위해 사용할 수 있는 API 및 SDK의 모음입니다. Google Maps Platform에는 여
hoilog.tistory.com
* 링크 (구글 코랩 작성한 계정으로 로그인하기)
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
* 핵심
- 데이터 입출력(불러오기, 저장)
- 경로 설정
- api 활용하기
'배운 책들 정리 > 파이썬 머신러닝 판다스 데이터분석' 카테고리의 다른 글
| 파이썬 머신러닝 판다스 데이터 분석 5,6 - 데이터 사전 처리, 데이터프레임의 다양한 응용 (0) | 2023.04.28 |
|---|---|
| 파이썬 머신러닝 판다스 데이터 분석 4_3, 5 - 시각화, 데이터 사전 처리 (0) | 2023.04.27 |
| 파이썬 머신러닝 판다스 데이터 분석 4_2 - 시각화 (0) | 2023.04.26 |
| 파이썬 머신러닝 판다스 데이터 분석 3,4 - 데이터 살펴보기, 시각화 (1) | 2023.04.25 |
| 파이썬 머신러닝 판다스 데이터 분석 1 - 판다스 자료 구조 (0) | 2023.04.21 |



