1장 판다스 입문
1) 판다스 자료 구조
* 대표적인 판다스 자료 구조
시리즈 : 1차원 배열 // = 하나의 열 // R 벡터와 같은
데이터프레임 : 2차원배열 (실무에서 가장 많이 사용) // 여러개의 시리즈 (열) // R 데이터 프레임 & Sql db 테이블과 같은
// a = c(1,2,3,4)
2) 판다스 자료 구조
* 시리즈 만들기
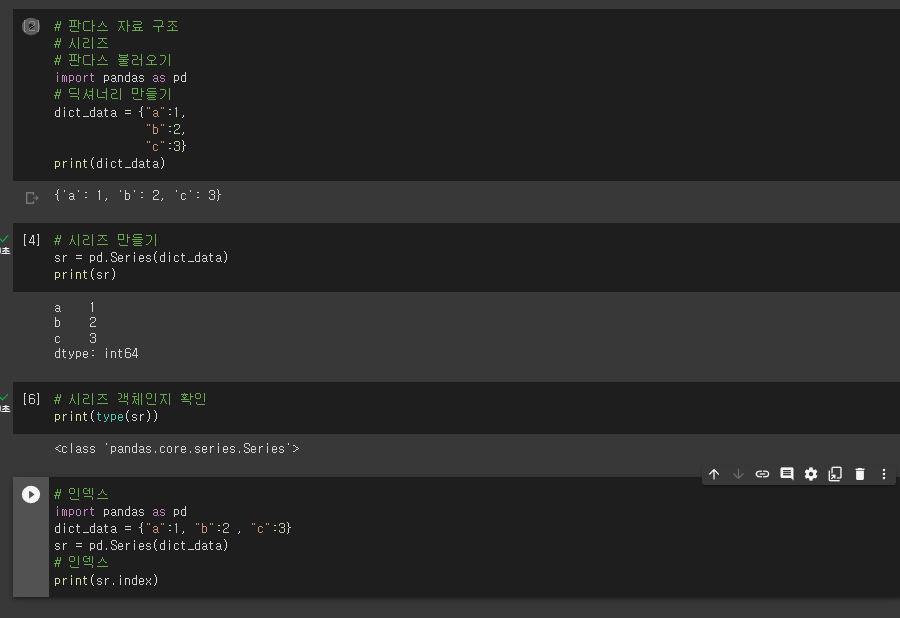
# 판다스 자료 구조
# 시리즈
# 판다스 불러오기
import pandas as pd
# 딕셔너리 만들기
dict_data = {"a":1,
"b":2,
"c":3}
print(dict_data)
# 시리즈 만들기
sr = pd.Series(dict_data)
print(sr)
# 시리즈 객체인지 확인
print(type(sr))
# 인덱스
import pandas as pd
dict_data = {"a":1, "b":2 , "c":3}
sr = pd.Series(dict_data)
# 인덱스
print(sr.index)
* 인덱스 활용

# 정수형 위치 인덱스
import pandas as pd
# 리스트 만들기
list_a = ['2023-04-21',3.14,'Hello',10,True]
print(list_a)
# 시리즈 만들기
sr=pd.Series(list_a)
print(sr)
# 인덱스를 이용한 원소 선택
import pandas as pd
# 튜플 만들기
tuple_data = ("정대만","2023-04-01","남",True)
print(tuple_data)
# 시리즈 만들기
sr=pd.Series(tuple_data, index=["이름","날짜","성별","상남자여부"])
print(sr)
# 인덱스 이용
# 하나의 원소 선택
print(sr[3])
print(sr[0])
print(sr["상남자여부"])
print(sr["이름"])
* 여러 개의 원소 선택
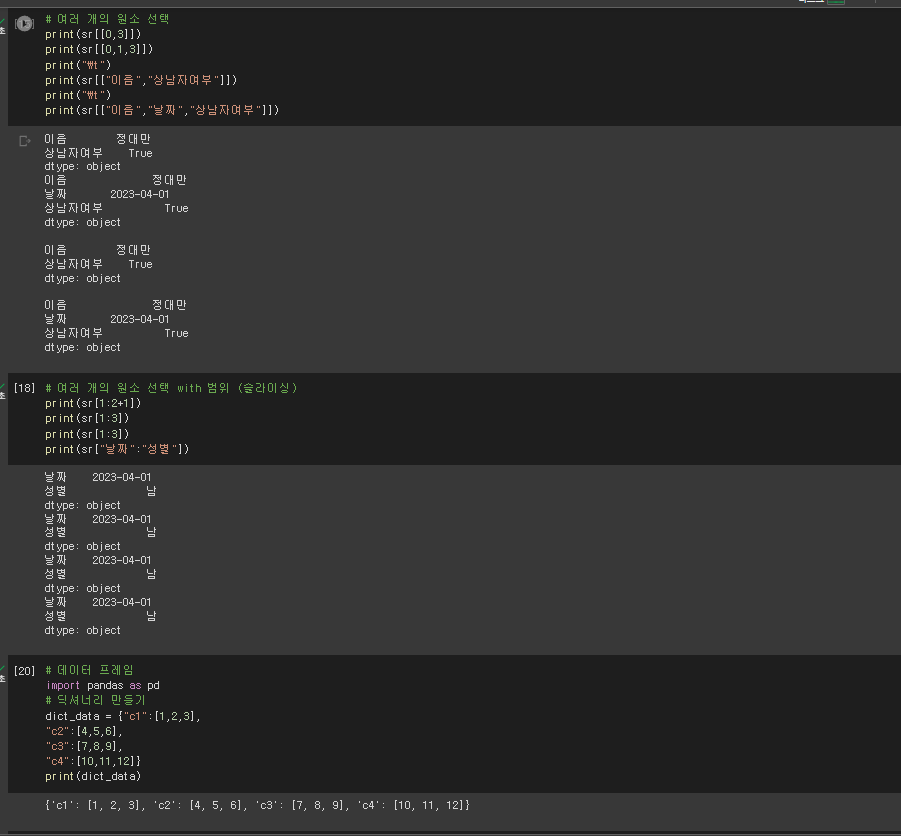
# 여러 개의 원소 선택
print(sr[[0,3]])
print(sr[[0,1,3]])
print("\t")
print(sr[["이름","상남자여부"]])
print("\t")
print(sr[["이름","날짜","상남자여부"]])
# 여러 개의 원소 선택 with 범위 (슬라이싱)
print(sr[1:2+1])
print(sr[1:3])
print(sr[1:3])
print(sr["날짜":"성별"])
# 데이터 프레임
import pandas as pd
# 딕셔너리 만들기
dict_data = {"c1":[1,2,3],
"c2":[4,5,6],
"c3":[7,8,9],
"c4":[10,11,12]}
print(dict_data)
* 행, 열 인덱스

# 데이터프레임 만들기
df = pd.DataFrame(dict_data)
print(df)
# 행 인덱스 / 열 이름 설치
import pandas as pd
# 데이터 프레임 만들기
df = pd.DataFrame([["정대만","남",19],["서태웅","남",17]],
index = ["선수1","선수2"],
columns = ["이름","성별","나이"])
print(df)
# 행 인덱스, 열 이름 확인
df.index=["학생1","학생2"]
df.columns=["성명","남여","연령"]
print(df.index)
print(df.columns)
# rename
print(df)
# 열 이름
df.rename(columns={"성명":"이름","남여":"성별"}, inplace= True)
# 행 인덱스 변경
df.rename(index={"학생1":"선수1","학생2":"선수2"}, inplace= True)
# 원본 확인
print(df)
* 행, 열 삭제

# 행/열 삭제
import pandas as pd
# 데이터프레임 만들기
# 딕셔너리 => 데이터프레임
exam_data = {'국어':[100,50,80],
'영어':[80,90,40],
'수학':[60,40,50],
'과학':[80,60,70]}
print(exam_data)
df = pd.DataFrame(exam_data,index=["서준","서진","서영"])
print(df)
# 복사본
df1 = df[:]
# 행 삭제
df1.drop('서진',inplace = True)
# df1.drop('서진',axis=0)
print(df1)
# 열 삭제
df2 = df[:]
df2.drop('과학',axis=1,inplace = True)
print(df2)
* 여러개 행 삭제

df3 = df[:]
# 여러 개의 행 삭제
df3.drop(["서진","서진"],axis=0,inplace=True)
# 여러 개의 열 삭제
df3.drop(["국어","수학"],axis=1,inplace=True)
print(df3)
# 같은 결과값 (복사본 만드는 방법2)
df3 = df.copy()
# 여러 개의 행 삭제
df3.drop(["서진","서진"],axis=0,inplace=True)
# 여러 개의 열 삭제
df3.drop(["국어","수학"],axis=1,inplace=True)
print(df3)
* loc,iloc 범위 지정

exam_data = {'국어':[100,50,80],
'영어':[80,90,40],
'수학':[60,40,50],
'과학':[80,60,70]}
df=pd.DataFrame(exam_data,index=["서준","서진","서영"])
print(df)
# 행 하나를 선택
# loc => 인덱스 이름
name1 = df.loc['서영']
print(name1)
# iloc => 인덱스 숫자
no1 = df.iloc[2]
print(no1)
# 2개 이상의 행 선택
name2 = df.loc[["서준","서진"]]
print(name2)
no2 = df.iloc[[0,1]]
print(no2)
# 행 인덱스 범위 지정하여 선택
name3 = df.loc[["서진","서영"]]
no3 = df.iloc[1:3]
* 원소 1개 선택

# 원소 선택
print(df)
# 원소 1개 선택 = 행1 열1
# loc 이름
# 서영의 국어 점수
print(df.loc["서영",["국어","수학"]])
# iloc 번호
print(df.iloc[2,[0,2]])
* 원소 2개 선택

# 원소 2개 선택 = 행1 열2 with 범위 지정
# 서영이의 수학, 과학 점수
# loc 이름
print(df.loc["서영", "수학":"과학"])
# iloc 번호
print(df.iloc[2,2:4])
print(df.iloc[2,2:])
# 원소 여러 개 선택 = 행2 열2
# 서준, 서영이의 영어, 과학 점수
print(df.loc[["서준","서영"],["영어","과학"]])
print(df.iloc[[0,2],[1,3]])
# 범위 지정 : 서진, 서영이의 수학, 과학
print(df.loc["서진":"서영","수학":"과학"])
print(df.iloc[1:3,2:4])
* 열, 행 추가

# 열 추가
print(df)
# 사회 과목 추가
df["사회"]=90
print(df)
# 체육 과목 추가
df["체육"] = [60,50,70]
print(df)
# 행 추가
print(df)
# 같은 값을 가지고 있는 행 추가
df.loc["진우"] = 0
print(df)
# 여러 개의 값을 가지고 있는 행 추가
df.loc["민종"] = [90,90,90,100,80,90]
* 점수 변경하기

# 원소 변경
print(df)
# 진우의 체육 점수를 변경
df.loc["진우","체육"] = 70
print(df)
# 진우의 사회 점수를 변경
df.iloc[3,4] = 80
print(df)
# 진우의 수학, 과학 점수를 변경
df.loc["진우",["수학","과학"]] = 80
print(df)
# 진우의 국어, 영어 점수를 변경
df.iloc[3,[0,1]] = 60, 70
print(df)
* 행과 열 바꾸기
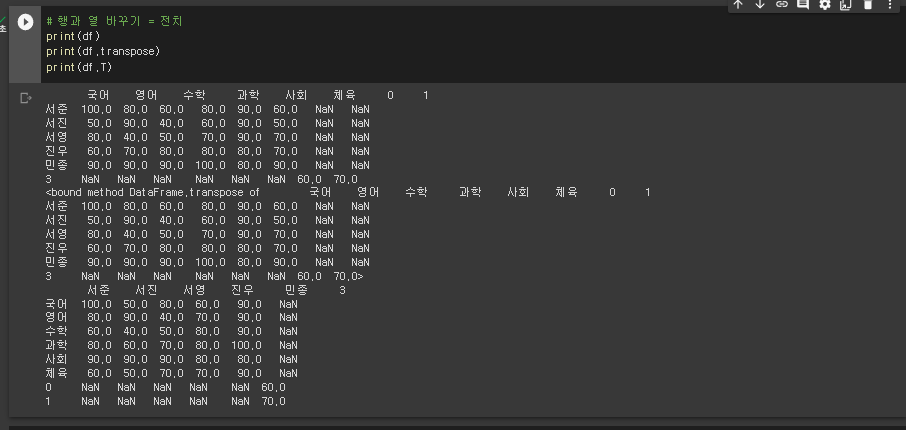
# 행과 열 바꾸기 = 전치
print(df)
print(df.transpose)
print(df.T)
* 인덱스 활용 (행 인덱스)

# 인덱스 활용
# 특정 열을 행 인덱스로 설정
import pandas as pd
slamdunk = {"이름":["정대만","강백호","채치수"],
"키":[183,189,193],
"나이":[19,17,19],
"평균득점":[25,5,15]}
df = pd.DataFrame(slamdunk)
print(df)
# 이름을 행 인덱스로 설정
df1=df.set_index(["이름"])
print(df1)
* 키 행 인덱스

# 키 행 인덱스로 설정
# 기존의 인덱스가 사라짐
df2=df.set_index(["키"])
print(df2)
# 키 행 인덱스로 설정
# 기존의 인덱스가 사라짐
print(df.set_index(["키"]))
df2 = df.set_index(["나이","평균득점"])
print(df2)
* 인덱스 재배열 & 초기화

# 행 인덱스 재배열
import pandas as pd
dict_data = {"c0":[1,2,3],
"c1":[4,5,6],
"c2":[7,8,9],
"c3":[10,11,12],
"c4":[13,14,15]}
df=pd.DataFrame(dict_data, index = ["r0","r1","r2"])
print(df)
# 행 인덱스 재배열
df1=df.reindex(["r0","r1","r2","r3","r4"])
print(df1)
df2=df.reindex(["r0","r1","r2","r3","r4"],fill_value = 0)
print(df2)
# 행 인덱스 초기화
# 기존의 인덱스가 새로운 열로 추가
print(df)
df3 = df.reset_index()
print(df3)

# 행 인덱스 정렬
print(df)
df4=df.sort_index(ascending=False) # 내림차순
print(df4)
# 열 기준 정렬 = 열이 가지고 있는 값으로 정렬
print(df)
df5 = df.sort_values(by = "c1", ascending= False)
print(df5)
* 핵심
loc : 실무에서 가장 많이 사용. .loc은 라벨(문자)을 사용하여 데이터를 선택하고 loc은 라벨 기반의 인덱싱을 수행하며,
loc은 주로 문자열 라벨이 있는 경우에 사용됩니다.
iloc : 실무에서 가장 많이 사용. 숫자로 표현. iloc은 인덱스(숫자)를 사용하여 데이터를 선택하는 것이 일반적인 관례입니다. iloc은 위치 기반의 인덱싱을 수행합니다. 따라서, iloc은 정수 인덱스를 사용하는 경우에 많이 사용됩니다.
* 코랩 링크 (작성한 계정으로 로그인!)
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
* 추가 링크
오늘 코드는 빠진 부분이 있을 수 있으니 해당 링크 참조
0421 Python
# 판다스 자료 구조 # 시리즈 # 판다스 불러오기 import pandas as pd # 딕셔너리 만들기 dict_data = {"a": 1, "b":2, "c":3} print(dict_data) ...
guromd1.blogspot.com
'배운 책들 정리 > 파이썬 머신러닝 판다스 데이터분석' 카테고리의 다른 글
| 파이썬 머신러닝 판다스 데이터 분석 5,6 - 데이터 사전 처리, 데이터프레임의 다양한 응용 (0) | 2023.04.28 |
|---|---|
| 파이썬 머신러닝 판다스 데이터 분석 4_3, 5 - 시각화, 데이터 사전 처리 (0) | 2023.04.27 |
| 파이썬 머신러닝 판다스 데이터 분석 4_2 - 시각화 (0) | 2023.04.26 |
| 파이썬 머신러닝 판다스 데이터 분석 3,4 - 데이터 살펴보기, 시각화 (1) | 2023.04.25 |
| 파이썬 머신러닝 판다스 데이터 분석 1,2 - 판다스 입문, 데이터 입출력 (0) | 2023.04.24 |



