3장 데이터 살펴보기
1. 데이터프레임
1) 데이터 내용 미리보기


#데이터 살펴보기
##데이터 프레임의 구조
###데이터 내용 미리보기
#1
# 라이브러리 불러오기
import pandas as pd
# 데이터 불러오기
df = pd.read_csv(r"/content/drive/MyDrive/BDA/part3/auto-mpg.csv", header=None)
print(df)
# 열 이름 지정
df.columns = ["mpg", "cylinders", "displacement","horsepower", "weight",
"accleration","model year","origin","name"]
# 기본값이 행 5개
# 데이터 앞부분
print(df.head())
# 데이터 뒷부분
print('\n')
# 원하는 출력 행의 개수 설정
print(df.tail())
2) 데이터 요약 정보 확인
숫자 -> 연속형변수(수치) -> 요약통계(summary)
문자 -> 범주형변수(그룹) -> 빈도 (table)
df.describe() // include = all

# 데이터 프레임의 크기 = 행, 열 개수
# 1
print(df.shape)
# 1-2
# 데이터프레임의 기본정보
print(df.info())
* 자료형 확인 // 기술통계 정보 요약


# 1-3
# 자료형 확인
print(df.dtypes)
print(df.horsepower.dtypes)
# 1-4
# 기술통계 정보 요약
print(df.describe())
print(df.describe(include="all"))
* 자료형 확인 // 기술통계 정보 요약 // 열의 데이터 개수

# 1-5
# 열의 데이터 개수
print(df.count) # 같은 결과
print(type(df.count))
print(df["origin"].value_counts()) # 같은 결과
# 1-6
# 평균
print(df.mean())
* 평균값, 중앙값 구하기
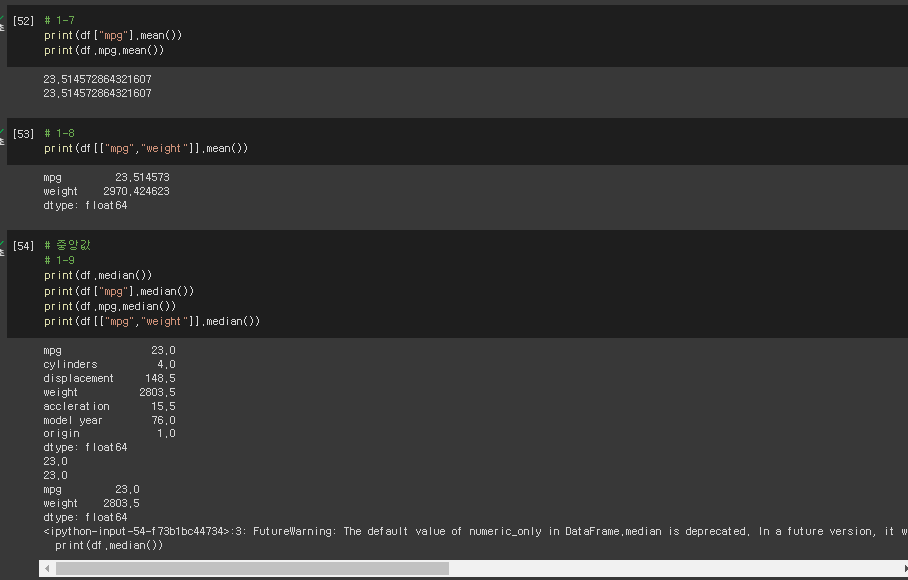
# 1-7
print(df["mpg"].mean())
print(df.mpg.mean())
# 1-8
print(df[["mpg","weight"]].mean())
# 중앙값
# 1-9
print(df.median())
print(df["mpg"].median())
print(df.mpg.median())
print(df[["mpg","weight"]].median())
* 최대값, 최솟값

# 최대값
# 1-9
print(df.max())
print(df["mpg"].max())
print(df.mpg.max())
print(df[["mpg","weight"]].max())
# 최솟값
# 1-10
print(df.min())
print(df["mpg"].min())
print(df.mpg.min())
print(df[["mpg","weight"]].min())
* 표준편차, 분산

# 표준편차
# 1-11
print(df.std())
print(df["mpg"].std())
print(df.mpg.std())
print(df[["mpg","weight"]].std())
# 분산 = 표준편차 제곱
# 1-12
print(df.var())
print(df["mpg"].var())
print(df.mpg.var())
print(df[["mpg","weight"]].var())
* 상관계수 구하기
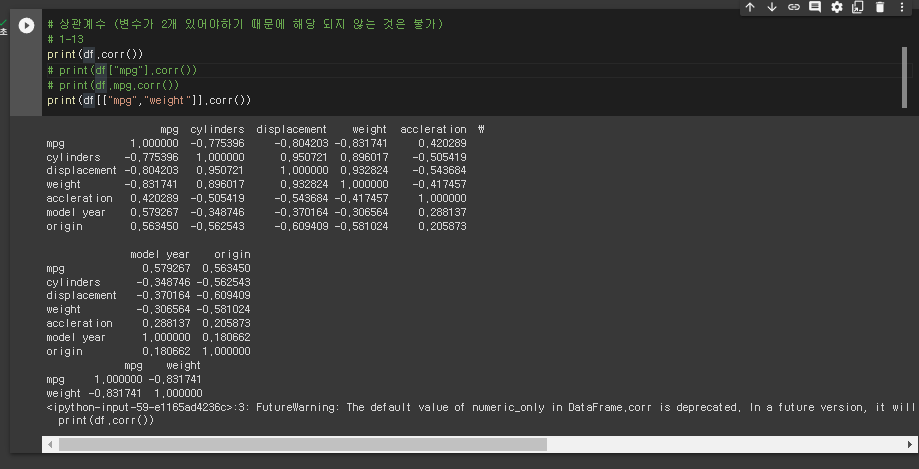
# 상관계수 (변수가 2개 있어야하기 때문에 해당 되지 않는 것은 불가)
# 1-13
print(df.corr())
# print(df["mpg"].corr())
# print(df.mpg.corr())
print(df[["mpg","weight"]].corr())
3) 판다스 내장 그래프 도구
* 선 그래프 출력


# 2
### 판다스 내장 그래프 도구
# 선 그래프
import pandas as pd
# 데이터 불러오기
df = pd.read_excel(r"/content/drive/MyDrive/BDA/part2/남북한발전전력량.xlsx")
# 필요한 행, 열 추출
df_new = df.iloc[[0,5],3:]
df_new.index = ["South","North"]
df_new.plot()
# 행과 열 전치
df_new_t = df_new.T
df_new_t.plot()
# = df_new_t.plot(kind = "line")
* 막대그래프
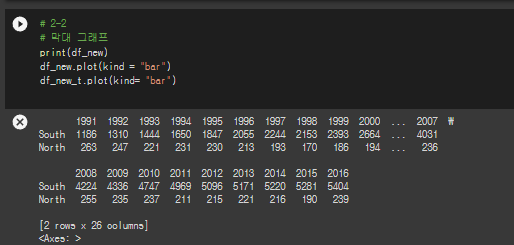

# 2-2
# 막대 그래프
print(df_new)
df_new.plot(kind = "bar")
df_new_t.plot(kind= "bar")
* 수평 막대 그래프
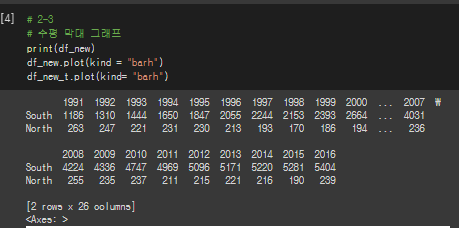

# 2-3
# 수평 막대 그래프
print(df_new)
df_new.plot(kind = "barh")
df_new_t.plot(kind= "barh")
* 히스토그램

# 2-4
# 히스토그램
# 수평 막대 그래프
# x축이 남한,북한이어서 안됨
print(df_new)
print(df_new_t.dtypes)
df_new_t =df_new_t.astype(int)
# df_new.plot(kind = "hist") # x축
df_new_t.plot(kind= "hist") # y축
* 산점도 분석


# 2-5
# 산점도
import pandas as pd
df = pd.read_csv(r"/content/drive/MyDrive/BDA/part3/auto-mpg.csv")
df.columns = ["mpg", "cylinders", "displacement","horsepower", "weight",
"accleration","model year","origin","name"]
print(df)
df.plot(x="mpg",y="weight",kind = "scatter")
* 상자 수염


4장 시각화 도구
1) 시각화 도구
* 한글 폰트 설치

# 4장 시각화 도구
# 4-1
# 한글 폰트 설치
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
# 설치 후 런타임 다시 시작
* 데이터 불러오기

# 4-2
import pandas as pd
# 데이터 불러오기
df = pd.read_excel(r"/content/drive/MyDrive/BDA/part4/시도별 전출입 인구수.xlsx",
header = 0, engine = "openpyxl")
print(df.head())
* Nan 값 채우기 // 원하는 부분만 빼기

# 4-3
# NaN 값을 채우기
df = df.fillna(method="ffill")
# 서울시에서 다른 지역으로 이동한 데이터
# 전출지별 == 서울시 & 전입지별 != 서울시
(df["전출지별"] == "서울특별시") & (df["전입지별"] != "서울특별시")
# 4-4
# 전출지별 == 서울시 & 전입지별 != 서울시
b_ind = (df["전출지별"] == "서울특별시") & (df["전입지별"] != "서울특별시")
# 불리언 인덱스로 데이터 추출 = 조건을 만족하는 행
df_seoul = df[b_ind]
df_seoul = df_seoul.drop("전출지별", axis = 1)
* 열 이름 변경

# 4-5
# 열 이름 변경
df_seoul.rename({"전입지별":"전입지"}, axis=1, inplace = True)
print(df_seoul)
* 행 인덱스 변경

# 4-6
# 행 인덱스 변경 # ???
df_seoul.set_index("전입지", inplace=True)
print(df_seoul)
* 서울에서 경기도로 이동한 인구 데이터 선택

# 4-7
# 서울특별시에 경기도로 이동한 인구 데이터 선택
import matplotlib.pyplot as plt
sr_1 = df_seoul.loc["경기도"]
# 선 그래프 그리기
plt.plot(sr_1.index, sr_1.values)
# 4-8
plt.plot(sr_1)
* 차트 디자인
# 4-9
# 차트 제목, 축 이름 추가
import matplotlib.pyplot as plt
# 한글 폰트 지정
plt.rc("font",family="NanumGothic")
# 선 그래프
plt.plot(sr_1.index,sr_1.values)
# 차트 제목 추가
plt.title("서울에서 경기도로 이동하는 인구수")
# 축 제목 추가
plt.xlabel("기간(연도)")
plt.ylabel("이동 인구 수")
* 그래프 꾸미기 2

# 4-10
# 그래프 꾸미기
# 그림 사이즈 지정(가로,세로)
plt.figure(figsize=(15, 5))
# x축 눈금 라벨 = 연도 회전시키기
plt.xticks(rotation="vertical")
# 선 그래프
plt.plot(sr_1.index,sr_1.values)
# 차트 제목 추가
plt.title("서울에서 경기도로 이동하는 인구수")
# 축 제목 추가
plt.xlabel("기간(연도)")
plt.ylabel("이동 인구 수")
# 범례 추가
plt.legend(labels =["서울시=>경기도"], loc="best")
* 그래프 꾸미기 3

# 4-11
# 그래프 꾸미기
# 스타일 서식
plt.style.use("ggplot")
# 그림 사이즈 지정(가로,세로)
plt.figure(figsize=(15, 5))
# x축 눈금 라벨 = 연도 회전시키기
plt.xticks(rotation="vertical")
# 선 그래프
plt.plot(sr_1.index,sr_1.values)
# 차트 제목 추가
plt.title("서울에서 경기도로 이동하는 인구수")
# 축 제목 추가
plt.xlabel("기간(연도)")
plt.ylabel("이동 인구 수")
# 범례 추가
plt.legend(labels =["서울시=>경기도"], loc="best",fontsize = 20)
* 스타일 서식 확인하기

# 4-12
# 스타일 서식 확인하는 방법
print(plt.style.available)
* 마지막 그래프 꾸미기 (인구 이동 증가 // 인구 이동 감소)


# 4-13
# 그래프 꾸미기
# 스타일 서식
plt.style.use("ggplot")
# 그림 사이즈 지정(가로,세로)
plt.figure(figsize=(15, 5))
# x축 눈금 라벨 = 연도 회전시키기
plt.xticks(rotation="vertical")
# 선 그래프
plt.plot(sr_1.index,sr_1.values)
# 차트 제목 추가
plt.title("서울에서 경기도로 이동하는 인구수")
# 축 제목 추가
plt.xlabel("기간(연도)")
plt.ylabel("이동 인구 수")
# 범례 추가
plt.legend(labels =["서울시=>경기도"], loc="best",fontsize = 20)
# ===============================시작==========================
# 그래프 주석
plt.ylim(50000,900000)
# 주석 추가
plt.annotate('',
xy=(20,620000), # 화살표 꼬리
xytext=(2,290000), # 화살표 머리
xycoords='data',
arrowprops=dict(arrowstyle='->', color='skyblue',lw=5), # 화살표 서식
)
plt.annotate('',
xy=(47,400000), # 화살표 꼬리
xytext=(30,580000), # 화살표 머리-
xycoords='data',
arrowprops=dict(arrowstyle='->', color='olive',lw=5), # 화살표 서식
)
# 주석 표시 - 텍스트
plt.annotate('인구 이동 증가(1970-1995)',
xy=(10,400000), # 텍스트 시작 위치
rotation=20, # 회전
va='baseline', # 위아래 정렬
ha='center', # 좌우 정렬
fontsize=15,)
plt.annotate('인구 이동 감소(1995-2017)',
xy=(40,500000), # 텍스트 시작 위치
rotation=-11, # 회전
va='baseline', # 위아래 정렬
ha='center', # 좌우 정렬
fontsize=15,)
* 링크 (구글 코랩 작성한 계정으로 로그인하기)
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
728x90
반응형
LIST
'배운 책들 정리 > 파이썬 머신러닝 판다스 데이터분석' 카테고리의 다른 글
| 파이썬 머신러닝 판다스 데이터 분석 5,6 - 데이터 사전 처리, 데이터프레임의 다양한 응용 (0) | 2023.04.28 |
|---|---|
| 파이썬 머신러닝 판다스 데이터 분석 4_3, 5 - 시각화, 데이터 사전 처리 (0) | 2023.04.27 |
| 파이썬 머신러닝 판다스 데이터 분석 4_2 - 시각화 (0) | 2023.04.26 |
| 파이썬 머신러닝 판다스 데이터 분석 1,2 - 판다스 입문, 데이터 입출력 (0) | 2023.04.24 |
| 파이썬 머신러닝 판다스 데이터 분석 1 - 판다스 자료 구조 (0) | 2023.04.21 |



