1. Spyder (파이썬)
1) 용어 및 기능 설명
- var : 변할 수 있는 값.
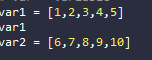

- 스파이더에서는 벡터를 합치면 연산하는 기능이 아닌 숫자의 배열이 추가되는 것을 보여준다.
- 함수를 드래그하고 ctrl + i를 쓰면 함수의 기능을 알 수 있다.
- 파이썬에서는 제곱을 표시할 때 ^ 연산자가 적용이 안된다. (파이썬에서는 **로 표시해야 한다.)
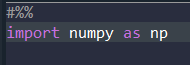
- as ~~를 하게 되면 특정 함수를 약자로 바꿀 수 있다. (numpy를 np로 사용할 수 있음)
- scipy : 통계 분석을 할 때 자주 사용함
2) 외부 데이터 가져오기
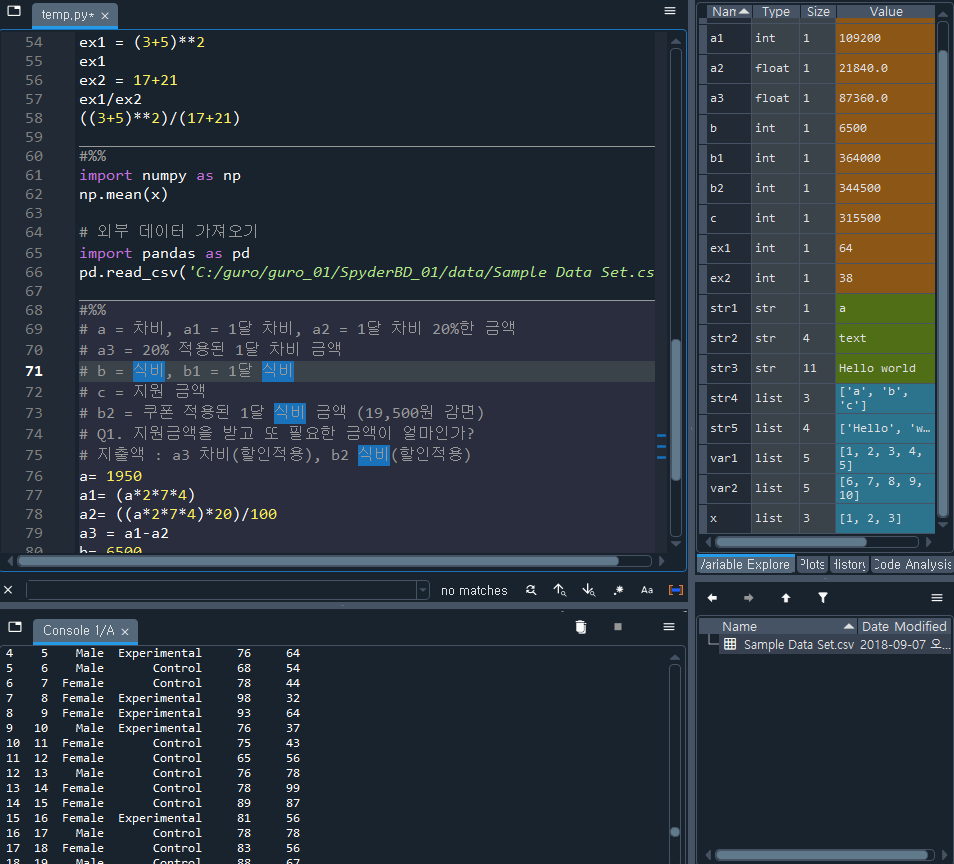
오른쪽 하단에 files를 클릭하면 excel 파일을 복사해서 바로 넣을 수 있다.
- ctrl + f 하고 ctrl + r을 실행하면 리플레쉬가 가능함
3) 변수 가져오기
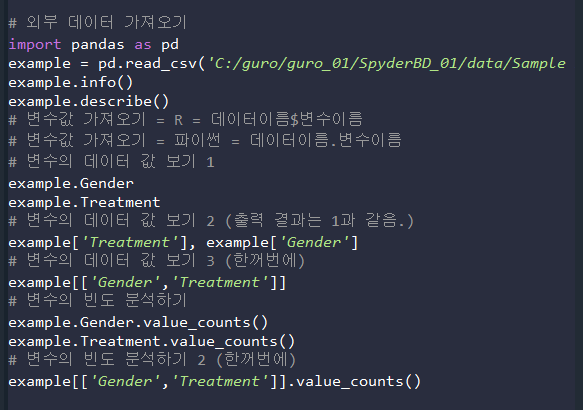
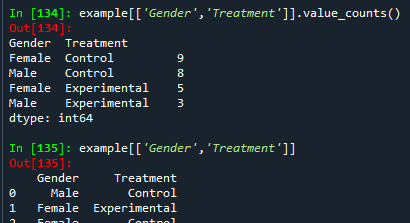
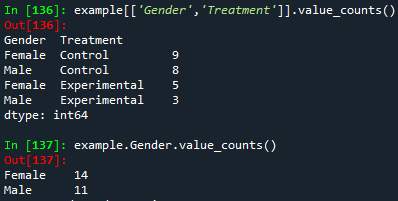
- 이런 느낌으로 변수 하나에 대한 값만 출력 됨.
- value_counts를 입력할 경우 빈도 값이 같이 출력 됨.
4) 상관계수 ( ex - 0.12141414)
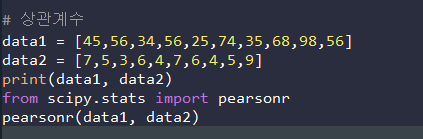

- 0.05보다 높으면 좋은 것임. (꼭 기억)
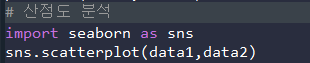
5) 산점도 분석
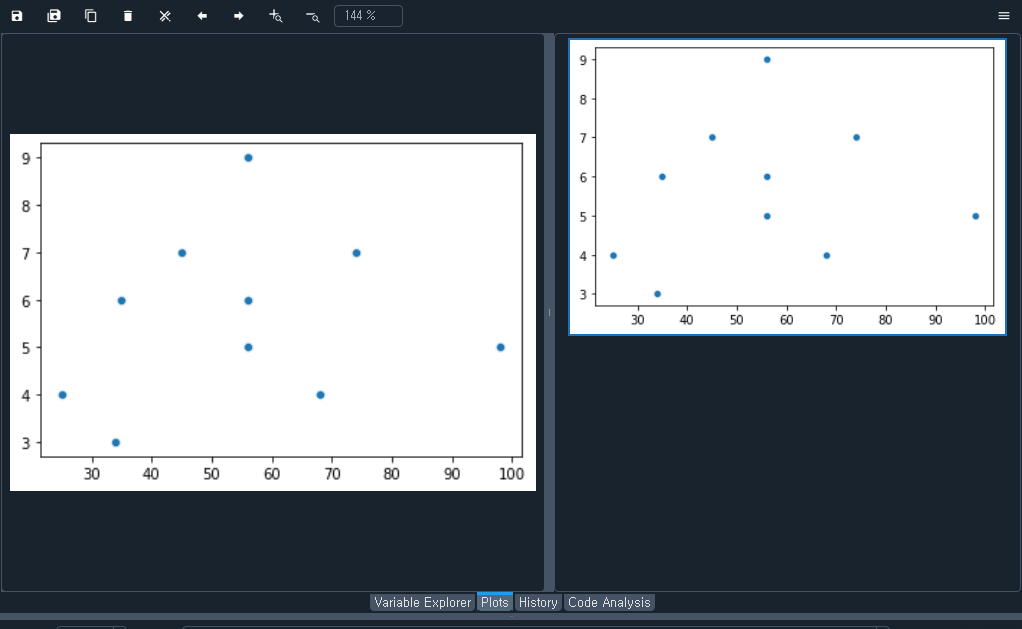
2. R과 파이썬
1) R과 파이썬의 차이

1) 숫자 - R
- 정수 : integer
- 실수 : numeric
2) 숫자 - 파이썬
- 정수 : int(eger)
- 실수 : float
3) 문자 - R
- character
4) 문자 - 파이썬
- str (ing)

- R은 숫자변수와 문자변수를 같이 보여준다.
- 파이썬은 숫자변수만 보여준다.
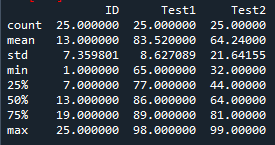
- 데이터 개수 (count)
- 평균 (mean)
- 표준 편차 (std/standard deviation)
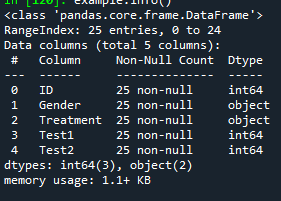
- object는 string으로 봐도 된다.
- 데이터 처리할 때 결치값 (missing value)이 있는지 확인해야 한다. (null값이 있는지)
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
# =============================================================================
# 레이아웃 변경
#
# View - Window layouts - Rstudio layout
#
# 주석 = ctrl + 1
#
# ctrl + 1 : 주석
# ctrl + 4 : 블록 주석
# ctrl + 5 : 블록 주석 해제
#
#
# =============================================================================
a=1
b=1
2+2
sum()
# 함수 사용법 = ctrl + i (함수 블록을 드래그해서 사용해준다.)
# 셀 구분 = #%%
#%%
# 여러 개의 값을 가진 변수
# var = variable
var1 = [1,2,3,4,5]
var1
var2 = [6,7,8,9,10]
var1+var2
# 문자 데이터
# str = string 문자열
str1 = "a"
str1
str2 = "text"
str2
str3 = "Hello world"
str3
str4 = ["a","b","c"]
str4
str5 = ["Hello","world","is","good!"]
str5
str2 + " " + str3
x = [1,2,3]
sum(x)
min(x)
max(x)
ex1 = (3+5)**2
ex1
ex2 = 17+21
ex1/ex2
((3+5)**2)/(17+21)
#%%
import numpy as np
np.mean(x)
# 외부 데이터 가져오기
import pandas as pd
example = pd.read_csv('C:/guro/guro_01/SpyderBD_01/data/Sample Data Set.csv')
example.info()
example.describe()
# 변수값 가져오기 = R = 데이터이름$변수이름
# 변수값 가져오기 = 파이썬 = 데이터이름.변수이름
# 변수의 데이터 값 보기 1
example.Gender
example.Treatment
# 변수의 데이터 값 보기 2 (출력 결과는 1과 같음.)
example['Treatment'], example['Gender']
# 변수의 데이터 값 보기 3 (한꺼번에)
example[['Gender','Treatment']]
# 변수의 빈도 분석하기
example.Gender.value_counts()
example.Treatment.value_counts()
# 변수의 빈도 분석하기 2 (한꺼번에)
example[['Gender','Treatment']].value_counts()
# R에서의 요약통계량 = R summary()
# 파이썬에서의 요약통계량 = describe()
# 데이터 개수 = 행의 개수 = 표본의 크기
# 평균
# 표준편차 = std = standard deviation
# 최소값 = 0 분위수
# 25분위수 = 1분위수
# 50분위수 = 2분위수 = 중앙값(median)
# 75분위수 = 3분위수
# 최대값 = 100분위수 = 4분위수
# -> example.describe
# 상관계수
data1 = [45,56,34,56,25,74,35,68,98,56]
data2 = [7,5,3,6,4,7,6,4,5,9]
print(data1, data2)
from scipy.stats import pearsonr
pearsonr(data1, data2)
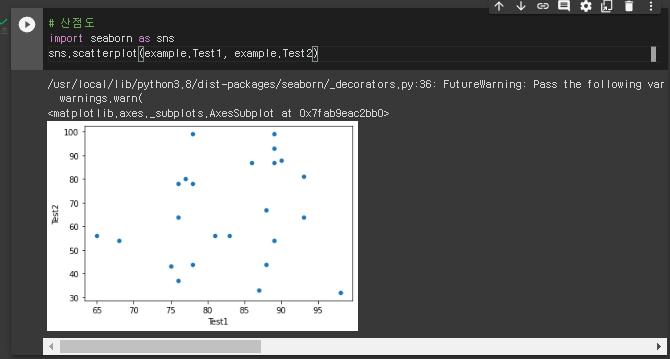
# 산점도 분석
import seaborn as sns
sns.scatterplot(data1,data2)
#%%
# a = 차비, a1 = 1달 차비, a2 = 1달 차비 20%한 금액
# a3 = 20% 적용된 1달 차비 금액
# b = 식비, b1 = 1달 식비
# c = 지원 금액
# b2 = 쿠폰 적용된 1달 식비 금액 (19,500원 감면)
# Q1. 지원금액을 받고 또 필요한 금액이 얼마인가?
# 지출액 : a3 차비(할인적용), b2 식비(할인적용)
a= 1950
a1= (a*2*7*4)
a2= ((a*2*7*4)*20)/100
a3 = a1-a2
b= 6500
b1 = b*2*7*4
b2 = b1-(b*3)
c = 315500
c-(a3+b2)
c-a3
3. Google Colab (코드 편집기)
- 구글 온라인 텍스트 에디터 서비스
- 머신러닝, 딥러닝에서 자주 사용.
- 구글 드라이브에서 코랩 설치 후 실행하기
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
1) 단축키
- Ctrl + enter = 해당 셀 실행 후 커서 그대로
- Alt + enter = 해당 셀 실행 후 자동 셀 생성하여 커서 이동
- Shift + enter = 해당 셀 실행 후 다음 셀로 커서 이동 (다음 셀이 없으면 새로 만듦)
* 주석
- Ctrl + / (?)
2) 연산
* 그룹 기능
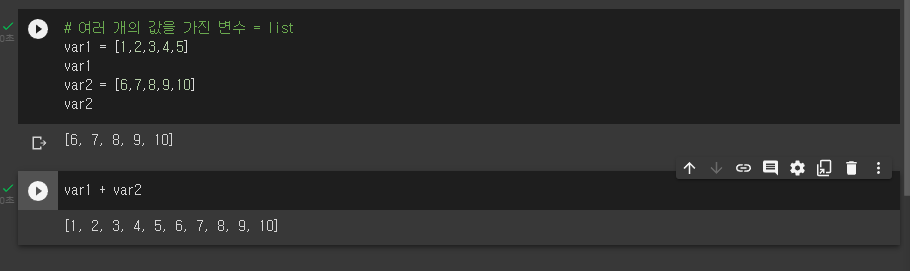
- 더하기 기능을 사용하면 리스트와 리스트끼리 연결해줌.
* 제곱 기능
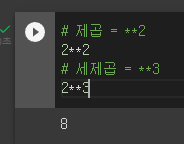
* 코랩에서 외부 데이터 가져오기
명령어 :
import pandas as pd
example = pd.read_csv("/content/drive/MyDrive/BDA/data/Sample Data Set.csv")
example
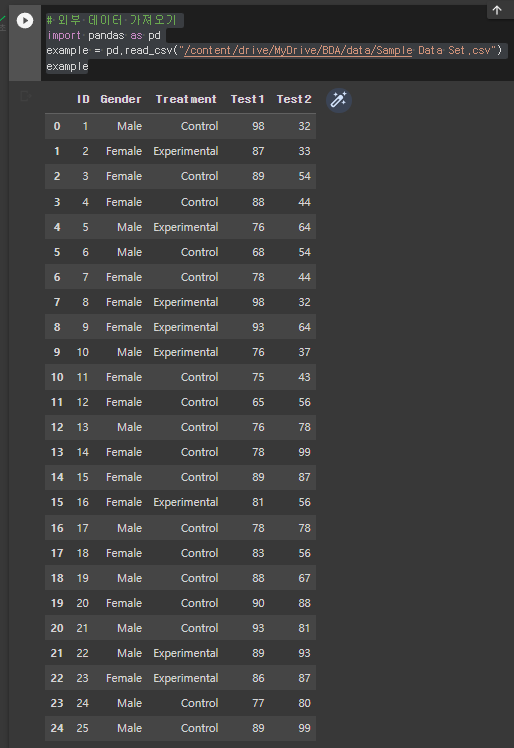
* example 데이터를 통해 분석하기
명령어 : example.describe() / 데이터 요약 그래프
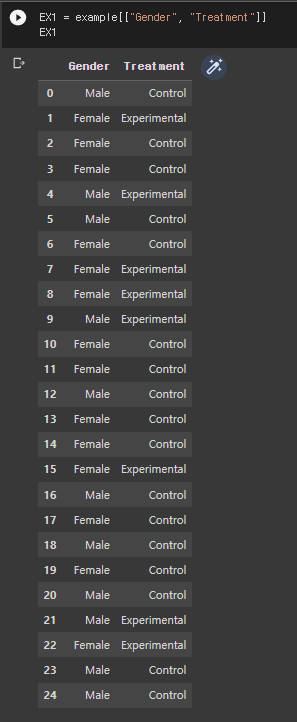
* example 데이터를 통해 분석하기 - 성별, 치료 비교군 통계 데이터 뽑기
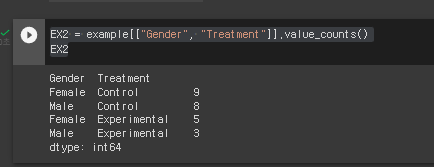
명령어 : EX1 = example[["Gender", "Treatment"]]
* example 데이터를 통해 분석하기 - 성별, 치료 비교군의 수치를 뽑기.
명령어 : EX2 = example[["Gender", "Treatment"]].value_counts()
* 특징
- 구글 코랩은 마지막 줄에 대한 실행 값만 보여준다.
(한줄 한줄을 따로 결과값을 볼 수 없음. 셀 타입의 코딩 기반이기 때문에)
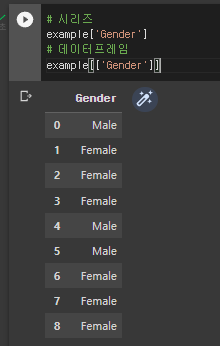
- 대괄호를 한번 더 묶으면 데이터 프레임 형태, 그대로 하면 시리즈 형태만 나옴
시리즈 : 열의 구조를 갖음
데이터 프레임 : 행과 열의 구조를 갖음.
4. 유의성을 이해하는 방법
- p.value가 적어야 좋음. (0.05 아래)
- 1점 오류를 기준으로 하는데 기준으로 하는 이유는 타격이 큰 쪽
- 1점 오류 : 효과가 없는데 있다고 사기치는 사람
- 2점 오류 : 효과가 있는데 없다고 사기치는 사람 (없으니깐 그냥 본인 실수임)
- 0.1을 기준으로 연구하는 사람 : 유의성을 널널하게 잡는 사람 (크게 잡을 수록 자세하게 하지 않는 것)
- 0.01을 기준으로 연구하는 사람 : 유의성을 빡빡하게 잡는 사람 (작아질 수록 자세하게 하는 것)
5. 산점도분석
6. 타이타닉 데이터를 통해 막대 그래프를 그리기 - 빈도분석(범주형 변수)
1) 성별수
df = sns.load_dataset('titanic')
df
sns.countplot(data = df, x = 'sex')
df.sex.value_counts()
df['class'].value_counts()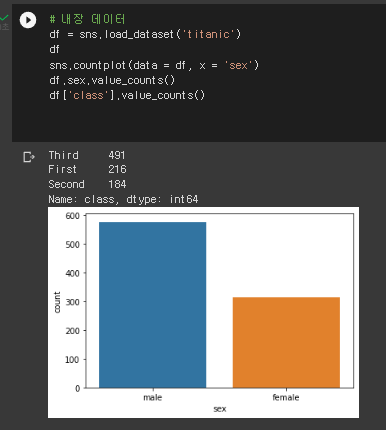
2) 좌석 등급의 빈도
sns.countplot(data=df, x = 'class')
df['class'].value_counts()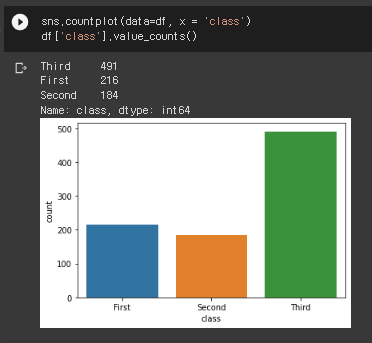
3) 좌석 등급에 따른 생존 빈도
sns.countplot(data=df, x = 'class', hue = 'alive')
df['class'].value_counts()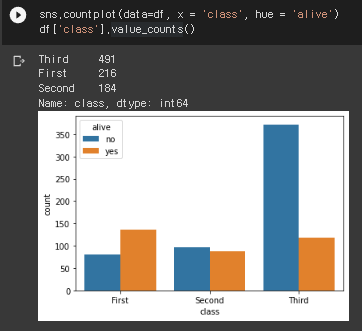
4) 함수에 대한 도움말 기능 및 패키지 설치법
# help 기능 (함수 뒤에 ?를 표시)
# 스파이더에서는 블록 지정 후 ctrl+i
sns.countplot?
# 패키지 설치
# 대신 매번 킬 때마다 설치 해야 함.
!pip install pydataset
5) 자동차 빅 데이터 출력
# py데이타셋에서 자동차 빅데이터 출력
import pydataset
pydataset.data()
df = pydataset.data('mtcars')
df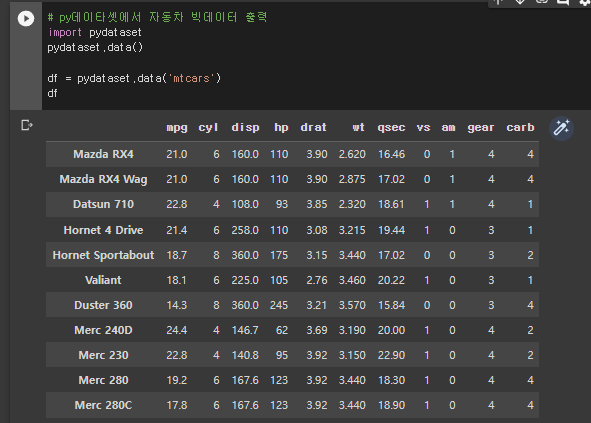
7. toad (토드) 복습
-- 주석 = CTRL + B
DESC EMP;
--SQL 기본 문법
-- SELECT ~ FROM ~
-- SELECT 열 이름(=컬럼 = 변수 = 필드) FROM 테이블 이름(데이터)
SELECT * FROM EMP;
--문자(숫자로 코딩되어 있으나 숫자 의미가 없음) = 범주형 변수 = 빈도(비율)
--숫자 = 연속형 변수 = 평균
SELECT ENAME, JOB FROM EMP;
-- 사원 정보
DESC EMP;
-- 부서 정보
DESC DEPT;
--SELECT (열이름) FROM (테이블 이름) // 데이터
SELECT * FROM EMP;
SELECT ENAME, JOB FROM EMP;
-- 사원 정보
DESC EMP;
-- 부서 정보
DESC DEPT;
SELECT * FROM DEPT;
--급여 등급 정보
DESC SALGRADE;
SELECT * FROM SALGRADE;
--EMP 테이블 조회
SELECT * FROM EMP;
SELECT EMPNO FROM EMP;
SELECT ENAME, HIREDATE, EMPNO FROM EMP;
--중복 제거
SELECT DEPTNO FROM EMP;
SELECT DISTINCT DEPTNO FROM EMP;
SELECT DISTINCT JOB, DEPTNO FROM EMP;
SELECT DISTINCT * FROM EMP;
--별칭 설정
SELECT ENAME, SAL, (SAL*12)+COMM FROM EMP;
SELECT ENAME, SAL, (SAL*12)+COMM AS ANNSAL FROM EMP;- EMP 테이블, 중복제거, 별칭설정
수업 정리
1. 오전
* 스파이더
- 백터 기능, 변수 가져오기, 외부 데이터 가져오기 실습
- 상관계수, 산점도 분석 설명.
* R과 파이썬
- R과 파이썬의 차이 설명.
* 구글 코랩
- 구글 드라이브가서 폴더 생성후 colab 설치해서 실행
2. 오후
* 구글 코랩
- 연산 기능 실행
- 드라이브 설치 실행
- 제목 설정 기능
- 외부 데이터 가져오기
- 유의성을 이해하는 방법
- 산점도분석
* 토드 (SQL)
- EMP 테이블 조회
- 중복 제거
- 별칭 설정
* 썰들
- 파이썬의 아이콘은 뱀이다. (개발자가 좋아하는 개그 프로그램에 뱀이 들어갔다고 함)
- 파이썬은 시작 번호가 0이라서 indexing을 할 때 var2[0:3]와 같은 방법으로 표시해야 한다.
'수업내용 정리' 카테고리의 다른 글
| 0202 수업 내용 정리 (0) | 2023.02.02 |
|---|---|
| 0201 수업 내용 정리 - 오라클 목차 01 (0) | 2023.02.01 |
| 0130 수업 내용 정리 (1) | 2023.01.30 |
| 2023-01-27 배운 것과 관련해서 설명 및 질문 (0) | 2023.01.27 |
| 2023 01 27 수업 내용 정리 (0) | 2023.01.27 |

