1. 벡터에 대하여
v1 <- c(1,2,3,4,5)
v6 <- c(2,4,6)
연산하고자 하는 값 : v1 + v6
결과 : 서로의 백터값이 다를 경우 에러메시지가 나옴. (개수를 맞춰야 함)
2. 문자열에 대하여
- string은 str1 <- "A"와 같이 문자를 나타내고자 " " 표시를 해줘야 한다.
- paste은 문
3. 데이터 분석 변수에 대하여
1) 범주형 변수 (성별)
- 데이터 입력값 : 문자
- 데이터분포 : 빈도/비율
- 통계분석 : 카이제곱검정 (비율차이)
2) 연속형 변수 (연봉)
- 데이터 입력값 : 숫자 (수치형)
- 데이터분포 : 요약통계량 (평균)
- 통계분석 : T검정 (독립표본평균차이)
4. 이름 추출하기

- 함수 마지막에 ;를 넣어주면 그 다음 줄과 이어진다.
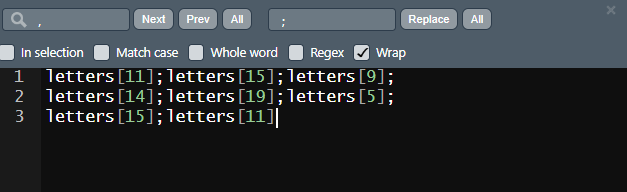
- find 기능을 이용해서 바꾸고 싶은 문자를 all을 눌러 한번에 바꿔라
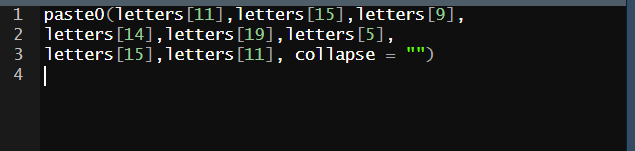
- paste 뒤에 0을 쓰면 공백이 전부 사라진다
- paste 블랭크로 연결 시켜주는 것
- paste0 블랭크 없이 연결 시켜주는 것 // 벡터 있을 때는 적용이 안된다.
- paste0(L1) = paste(L1,collapse = "")은 똑같다.
- 사칙연산은 생각보다 중요하다.
5. 연산기호에 대하여
- 제곱 연산자 = ^ or **
예시) 2**2, 2^2
- 괄호 표시는 꼭!
6. 원하는 객체 찾기 (feat, ls)

- 해당 파라미터를 보고 함수를 이해해서 쓰기.
- ls() : 만들어 둔 것을 확인할 수 있음.
- ls(pattern = "c) : c로 저장된 것을 다 확인 가능


- " "표시를 없애면 숫자열로 인식한다는 것을 이해해야 한다.
- 객체 지우기 : 그냥 빗자루 클릭
* 기타
- string이 문자열의 뜻인 이유는 문자들이 나열한게 스트링한것과 같다는 이유.
- 영역 태그 후 괄호 shift+9눌러주기
- ctrl + L : console에서 해당 기능을 실행하면 콘솔 내용이 청소가 된다.
- 꼭 기억해야 하는 단축키
주석 : ctrl + shift + c
할당연산자 : alt + -
실행 : ctrl + enter
7. 만만한 통계 r 파일 설치
(https://www.hanbit.co.kr/support/supplement_list.html)
- 여기서 자료 받아서 프로젝트 폴더에 넣기
8. 데이터 확장자
- 엑셀 xlsx
- 텍스트 txt
- csv = comma separated values (구분하는 기호를 ,로 쓴다)
- tsv = tab separated values (구분하는 방법을 TAB으로 쓴다) -> 열과 열사이의 탭을 눌러 진행하는
- rdata : R 개체(예: 변수, 데이터 프레임, 목록 등)를 저장하는 데 사용되는 R의 이진 파일 형식입니다
9. csv 경로설정
quote : 값들을 묶어주는 역할
1) 예시 :
read : 읽기 기능
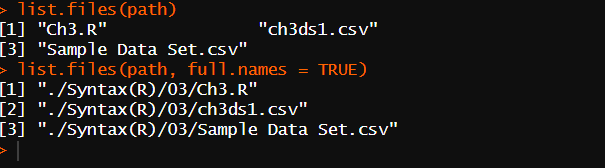
list.files(path) : path에 넣은 폴더 파일 이름 리스트 추출
list.files(path, full.names = TRUE) : 폴더명과 함께 표시
read.csv("./Syntax(R)/03/Sample Data Set.csv")
example <- read.csv("./Syntax(R)/03/Sample Data Set.csv")
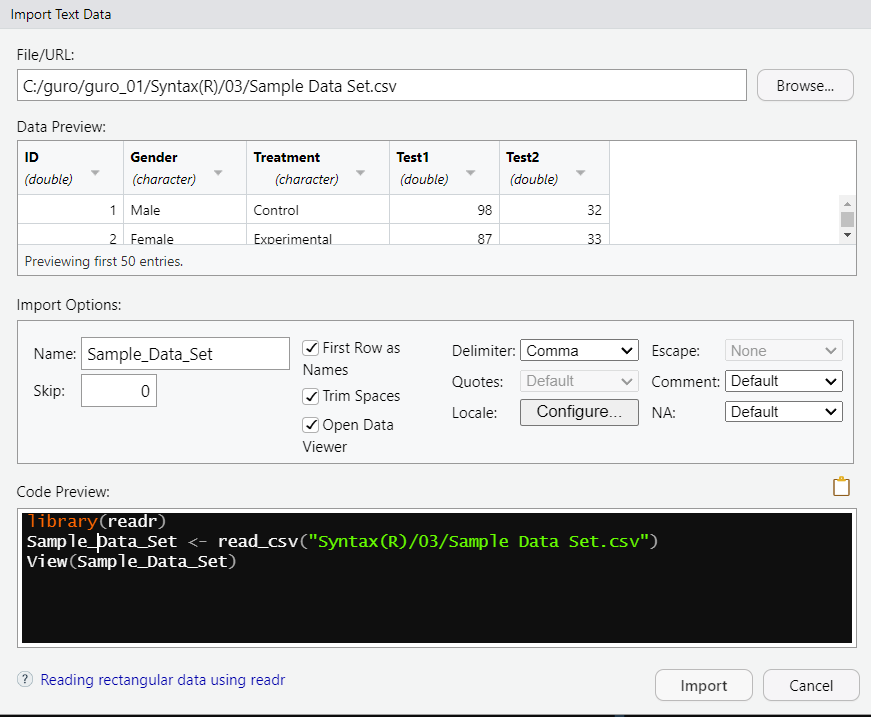
만약 불러오는 코드가 생각이 나지 않는다면 Import Text Data에 들어가면 코드를 가져올 수 있다.
10. 데이터 통계 방법
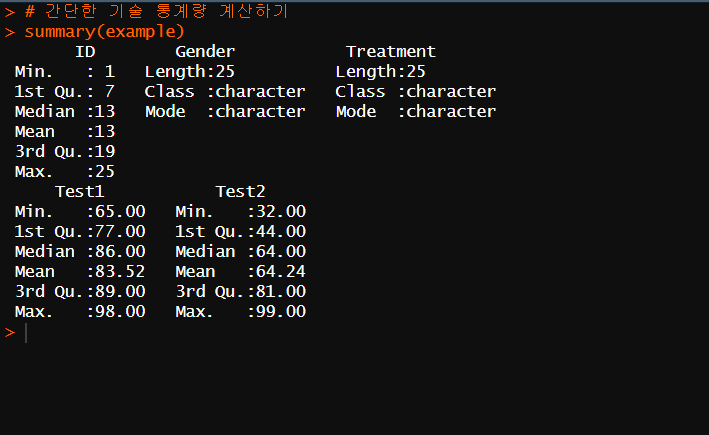
해당 데이터 분석 값의 대한 해석
- ID: 최소값은 1이고 최대값은 25입니다. 중앙값은 13입니다. 즉, 값의 50%가 13보다 크고 50%가 13보다 작다는 의미입니다. 평균도 13입니다. 가치.
- 성별: 데이터 세트의 길이는 25이고 클래스는 문자입니다. 모드는 가장 빈번한 값이며 이 경우 문자이기도 합니다.
- 처리: 데이터 세트의 길이는 25이고 클래스는 문자입니다. 모드는 가장 빈번한 값이며 이 경우 문자이기도 합니다.
- Test1: 최소값은 65이고 최대값은 98입니다. 중앙값은 86이며, 이는 값의 50%가 86 이상이고 50%가 86 미만임을 의미합니다. 평균은 값의 평균인 83.52입니다. (좁은 분포를 갖고 있다)
- Test2: 최소값은 32이고 최대값은 99입니다. 중앙값은 64이며, 이는 값의 50%가 64보다 크고 50%가 64보다 작다는 것을 의미합니다. 평균은 값의 평균인 64.24입니다. (넓은 분포를 갖고 있다.)
1Q(25)에 해당하는 값 : 7
성별과 처리는 요약통계량 값이 안나옴 (순전히 문자의 갯수만 확인 가능)
범위 : 최댓값 - 최소값
이 둘은 분산표준편차가 큰 것임.
TEST1은 좁게 퍼져 있음.
1Q = 25 (첫번째값)
2Q = 50
3Q = 75
4Q = 100

800 = 1분위수
850 = 2분위수
900 = 3분위수
1000 = 4분위수
* 데이터 통계의 장점
1. 데이터분포 확인 가능
2. 이상치 확인 가능
*
실험군 : 약물치료를 받은 그룹
대조군 : 약물치료를 받지 않은 그룹
- test1과 test2는 연속형 변수임.
- 여기서는 T-test를 사용함.
- 변수 이름 가져오기 : $ 표시를 넣으면 열을 꺼내올 수 있음. 예시) example$Gender
11. 상관계수 구하는 법
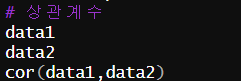
정리
1. 상관계수 : 음의 상관관계, 양의 상관관계
12. 아나콘다 설치 후 주피터 실행
https://www.anaconda.com/products/distribution
Anaconda | Anaconda Distribution
Anaconda's open-source Distribution is the easiest way to perform Python/R data science and machine learning on a single machine.
www.anaconda.com
가서 설치 후

주피터 노트북 런치 실행
해당 화면이 뜸
ctrl + enter : 해당 셀 실행
alt + enter : 다음 셀로 넘어가면서 새로운 셀 만들면서 진행
shift + enter : 다음 셀에 새로운 셀이 없으면 새로운 셀을 만들어가면서 진행
등등
* 주피터는 내가 만든 객체를 바로 볼 수 없음.
13. 스파이더 실행
스파이더 실행후
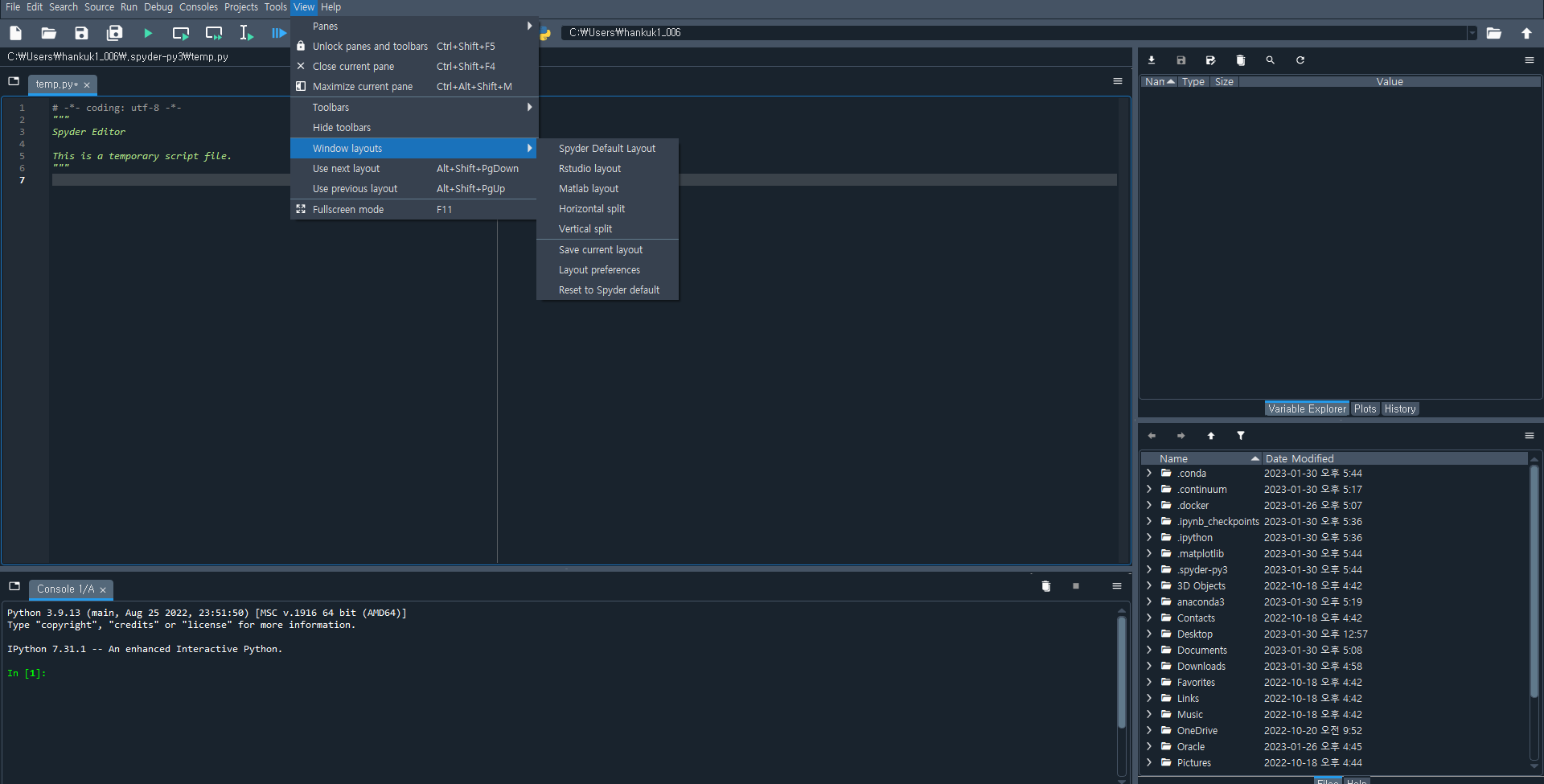
VIEW에서 R Studio 환경으로 변경하기
1) 스파이더 단축키
레이아웃 변경
View - Window layouts - Rstudio layout
주석 = ctrl + 1
ctrl + 1 : 주석
ctrl + 4 : 블록 주석
ctrl + 5 : 블록 주석 해제
중간에 있는 enter 는 return
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
# =============================================================================
# 레이아웃 변경
#
# View - Window layouts - Rstudio layout
#
# ctrl + i : 함수 사용법 (함수 블록을 드래그해서 사용해준다.)
# ctrl + 1 : 주석
# ctrl + 4 : 블록 주석
# ctrl + 5 : 블록 주석 해제
#
#
# =============================================================================
# 셀 구분 = #%%
#%%
#%%
a=1
b=2
c=3
d=4
a+b
a+b+c
d-b
5*b
4/d
| 핵심 |

1. data는 문자랑 숫자로 표현한다.
2. 범주형 변수는 성별로 표현하고 연속형 변수는 수치로 표현한다.
3. 범주형 변수는 빈도/비율을 나타내기 위해 통계를 내는 반면
연속형 변수는 요약통계량(평균)을 구할 때 사용한다.
4. 빈도형 변수 : table 변수 사용
범주형 변수 (요약 통계량) : summary 변수를 사용
5. ctrl + enter 꼭 기억하기 (가운데 return 쓰지 말고!!)
# 주석 = shift + ctrl + c
# 할당 연산자 = alt + -
# 명령어 실행 = ctrl + enter
a = 4
a <- 1
b <- 2
c <- 3
d <- 4
# 사칙연산
a+b
c-d
b*d
d/b
2*(a*b)
# 연산자를 넣으지 않으면 인식하지 못한다.
# combine 함수 : 여러 개의 값을 저장 (범용성 넓은 함수)
v <- c(1,5,7,9,2)
v1 <- c(1,2,3,4,5)
v2 <- c(1:5)
v2 <- c(1:5, 2)
v2
v6 <- c(2,4,6)
# sequence 함수 : 연속적인 값만 만들 수 있다. 또는 특정 규칙에 따라 연속적인 값을 저장
v3 <- seq(1,5)
v3
v4 <- seq(1,10,by=2)
# by는 간격을 의미 함. (by는 매개변수라 생략이 가능)
v4
# 문자
str1 <- "k"
str2 <- "text"
str3 <- c("a","b","c")
str4 <- c("hello!","world","is","good!")
str4
paste(str4,collapse ="_")
paste(str4,collapse =" ")
# 숫자 데이터 = 연속형 변수 = 평균
mean(v1)
# 문자 데이터 = 범주형 변수 = 비율
table(str3)
# 대괄호 : []
# 중괄호 : {}
# 소괄호 : ()
# 인덱스 : 데이터 위치
# 인덱싱 : 인덱스를 이용해 데이터 추출 작업
# 알파벳 추출 (index를 이용해서 뽑았기 때문에 indexing이라고 한다.)
LETTERS[1:20]
letters[c(11,15)]
LETTERS[c(16,1,18,11)]
LETTERS[c(10,9,9,14)]
L1 <- LETTERS[c(16,1,18,11)]
L2 <- LETTERS[c(10,9,9,14)]
L3 <- paste(L1,collapse = "")
L4 <- paste(L2,collapse = "")
# 파이썬에서는 가능하지만 R studio에서는 L3+L4을 적용해주는 기능이 없기에 paste로 적용한다.
paste(L3,L4, collapse = " ")
L3+L4
vv1 <- paste(v1, collapse = "")
vv1 <- paste0(v1, collapse = "")
vv1
v+v6
a1 <- 2*(3+5)
a2 <- (17+21)
a1
a2
# 제곱 = ^
2^2
2^4
(3+5)**2/17+21
(3+5)**2/(17+21)
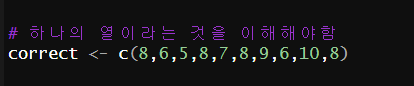
# 하나의 열이라는 것을 이해해야함
correct <- c(8,6,5,8,7,8,9,6,10,8)
ls()
ls(pattern = "c")
ls(pattern = c)
# "" 표시를 안하면 알파벳을 숫자열로 인식해서 표시한다.
# 객체 지우기
# 1) 메뉴에서 Session - clear Workspace...
# 2) 아님 옆에 있는 빗자루 클릭
data1 <- c(45,56,34,56,25,74,35,68,98,56)
data2 <- c(7,5,3,6,4,7,6,4,5,9)
data3 <- c(1,2,1,2,2,1,2,1,2,2)
# 객체 확인
ls()
# 특정 객체 삭제
rm(data3)
# 외부 데이터 가져오기
# 창으로 선택해서 가져오기
read.csv(file.choose())
# 경로 설정으로 가져오기
# 작업 폴더 = 프로젝트 폴더 = ./
example <- read.csv("./Syntax(R)/03/Sample Data Set.csv")
example
path = "./Syntax(R)/03/"
list.files(path, full.names = TRUE)
filenames <- list.files(path, full.names = TRUE)
filenames[3]
read.csv(filenames[1])
example <- read.csv("./Syntax(R)/03/Sample Data Set.csv")
example
# 간단한 기술 통계량 계산하기
# 연속형 변수에 해당하는 값들
# 최소값 = 0
# 1분위수 = 25분위수
# 2분위수 = 50분위수 = 중앙값(median)
# 3분위수 = 75분위수
# 최대값 = 4분위수 = 100분위수
# 평균
summary(example)
# 범주형 변수
example
# 빈도, 비율
table(example$Gender)
table(example$Treatment)
# 상관계수
data1
data2
cor(data1,data2)
# 산점도
plot(data1,data2)
# 패키지 검색
# 우하단의 Packages 창에서 검색
search()
'수업내용 정리' 카테고리의 다른 글
| 0202 수업 내용 정리 (0) | 2023.02.02 |
|---|---|
| 0201 수업 내용 정리 - 오라클 목차 01 (0) | 2023.02.01 |
| 0131 수업 내용 정리 (0) | 2023.01.31 |
| 2023-01-27 배운 것과 관련해서 설명 및 질문 (0) | 2023.01.27 |
| 2023 01 27 수업 내용 정리 (0) | 2023.01.27 |


