Q1. SQL에서 기존에 있는 EMP_HW 테이블에 EMP 테이블을 입력하고 싶어.
대신 EMP_HW에만 존재하는 REMARK라는 열의 테이블에는 NULL 값으로 지정하고 싶어.
INSERT INTO EMP_HW (col1, col2, ..., REMARK)
SELECT col1, col2, ..., NULL
FROM EMP;
Q2. SQL 객체 종류에서 사용자 테이블과 시스템 테이블에 대해 설명해줄래


SQL에서 테이블은 사용자 테이블 또는 시스템 테이블로 분류될 수 있습니다.
사용자 테이블은 사용자가 데이터를 저장하기 위해 만든 테이블입니다. 이 테이블에는 사용자가 입력한 데이터가 포함되어 있으며 필요에 따라 사용자가 쿼리, 업데이트 및 삭제할 수 있습니다. 사용자 테이블은 CREATE TABLE명령문을 사용하여 생성되며 해당 이름은 일반적으로 데이터베이스의 다른 테이블과 구별하기 위해 사용자 고유의 이름 또는 사용자 지정 접두사로 시작합니다.
반면에 시스템 테이블은 테이블, 인덱스 및 저장 프로시저에 대한 정보와 같은 데이터베이스에 대한 메타데이터를 저장하기 위해 데이터베이스 관리 시스템(DBMS)에서 만들고 유지 관리하는 테이블입니다. 시스템 테이블은 데이터베이스를 관리하기 위해 DBMS에서 내부적으로 사용되며 사용자가 직접 수정할 수 없습니다. 시스템 테이블에는 일반적으로 DBMS 자체 접두사로 시작하는 이름이 있으며 특수 스키마에 저장됩니다.
시스템 테이블을 직접 수정하거나 삭제하면 데이터베이스 손상 또는 기타 의도하지 않은 결과가 발생할 수 있으므로 주의해야 합니다. 대신 사용자는 DBMS에서 제공하는 API 및 인터페이스를 사용하여 데이터베이스와 상호 작용하고 사용자 테이블에 저장된 데이터를 수정해야 합니다.
Q3. 데이터 사전 뷰의 접두어에 대해 설명해줄래?
SQL에서 데이터 딕셔너리 뷰의 접두사는 뷰가 데이터베이스에 대한 메타데이터 정보를 제공하는 시스템 정의 뷰임을 나타내는 명명 규칙입니다. 접두사는 일반적으로 "데이터 사전" 또는 "시스템 카탈로그"를 나타내는 약어이며 이러한 보기를 데이터베이스의 다른 유형의 보기 및 테이블과 구별하는 데 사용됩니다.
데이터 딕셔너리 뷰에 사용되는 특정 접두사는 사용 중인 데이터베이스 관리 시스템(DBMS)에 따라 다를 수 있습니다. 다음은 다양한 DBMS에서 사용되는 몇 가지 일반적인 접두사입니다.
- Oracle에서는 접두사 "DBA_", "ALL_", "USER_" 또는 "V_$"가 데이터 사전 보기에 자주 사용됩니다.
- SQL Server에서 접두사 "sys." 데이터 딕셔너리 뷰에 자주 사용됩니다.
- MySQL에서 접두사 "INFORMATION_SCHEMA." 데이터 딕셔너리 뷰에 사용됩니다.
- PostgreSQL에서 접두사 "pg_catalog." 데이터 딕셔너리 뷰에 사용됩니다.
데이터 딕셔너리 뷰는 데이터베이스의 스키마, 보안 설정 및 성능 통계에 대한 정보뿐만 아니라 테이블, 열, 인덱스, 제약 조건 및 저장 프로시저의 이름과 같은 데이터베이스에 대한 풍부한 정보를 제공합니다. 이 정보는 데이터베이스의 구조와 동작을 이해하고 데이터베이스 관리 스크립트 및 도구를 작성해야 하는 데이터베이스 관리자 및 개발자에게 유용할 수 있습니다.
Q4. SELECT * FROM USER_IND_COLUMNS; 에서 IND의 뜻이 뭐야?
SELECT * FROM USER_IND_COLUMNS;IND 은 USER_IND_COLUMNS에서 "INDEX"를 나타냅니다. USER_IND_COLUMNS데이터베이스의 사용자 테이블에 있는 인덱스의 일부인 열에 대한 정보를 제공하는 Oracle의 데이터 딕셔너리 뷰입니다.
Oracle에서 인덱스는 쿼리 성능을 향상시키기 위해 테이블에 만들 수 있는 선택적 구조입니다. 인덱스는 데이터베이스가 전체 테이블을 스캔하지 않고도 테이블에서 특정 행을 찾을 수 있는 빠르고 효율적인 방법을 제공합니다. 테이블이 인덱싱되면 데이터베이스는 인덱싱된 열의 값을 테이블의 해당 행에 매핑하는 데이터 구조를 생성합니다.
USER_IND_COLUMNS뷰는 인덱스 이름, 테이블 이름, 인덱싱된 열 이름, 인덱스 내 열 위치와 같이 사용자 테이블의 인덱스에 속하는 열에 대한 세부 정보를 제공합니다 . 이 정보는 데이터베이스에서 인덱스의 구조와 동작을 이해하고 데이터베이스 관리 스크립트 및 도구를 작성해야 하는 데이터베이스 관리자 및 개발자에게 유용할 수 있습니다.
USER_IND_COLUMNS다음은 보기 를 사용하는 쿼리의 예입니다 .
SELECT index_name, table_name, column_name, column_position
FROM USER_IND_COLUMNS;이 쿼리는 데이터베이스의 모든 사용자 테이블에 대한 인덱스 이름, 테이블 이름, 인덱싱된 열 이름 및 인덱스 내 열 위치를 검색합니다. 쿼리 결과는 인덱스 구조를 이해하고 인덱스가 쿼리 성능을 개선하는 데 사용되는 방식을 이해하는 데 사용할 수 있습니다.
Q5. 테이블을 생성하는 것과 인덱스를 생성하는 것의 차이를 모르겠어
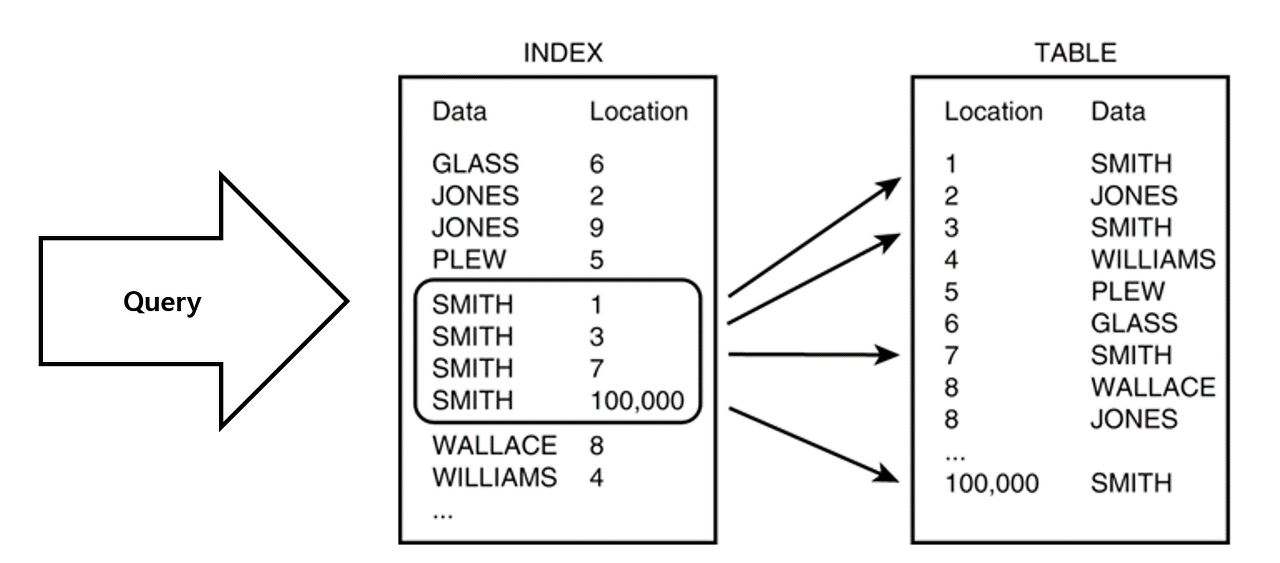
테이블과 인덱스는 SQL에서 서로 다른 두 가지입니다.
테이블은 행과 열에 데이터를 저장하는 데이터베이스 개체입니다. 테이블의 각 행은 데이터베이스의 단일 레코드를 나타내고 각 열은 해당 레코드의 특정 속성을 나타냅니다. 이 문을 사용하여 테이블을 만들고 CREATE TABLE필요에 따라 수정, 쿼리 및 삭제할 수 있습니다.
반면에 인덱스는 쿼리 성능을 향상시키기 위해 테이블에 생성할 수 있는 선택적 구조입니다. 인덱스는 데이터베이스가 전체 테이블을 스캔하지 않고도 테이블에서 특정 행을 찾을 수 있는 빠르고 효율적인 방법을 제공합니다. 테이블이 인덱싱되면 데이터베이스는 인덱싱된 열의 값을 테이블의 해당 행에 매핑하는 데이터 구조를 생성합니다. 인덱스는 CREATE INDEX명령문을 사용하여 생성되며 필요에 따라 삭제하거나 수정할 수 있습니다.
다음은 SQL에서 테이블과 인덱스를 만드는 방법의 예입니다.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100)
);
CREATE INDEX idx_customers_email ON customers (email);이 예에서 첫 번째 명령문은 , , 및 의 customers4개 열로 명명된 테이블을 생성합니다 . 열은 테이블 의 각 행에 대한 고유 식별자인 기본 키로 정의됩니다.customer_idfirst_namelast_nameemailcustomer_id
두 번째 문은 테이블 idx_customers_email의 email열에 이름이 지정된 인덱스를 만듭니다. 이 인덱스를 사용하면 데이터베이스가 전체 테이블을 스캔하지 않고도 열의 값을 기반으로 테이블 customers의 행을 빠르게 찾을 수 있습니다 'customers', 'email'
Q6. SQL 객체에서 시퀀스의 다양한 옵션들을 설명해줄래
- START WITH: 시퀀스에서 생성할 첫 번째 번호를 지정합니다.
- INCREMENT BY: 시퀀스에 의해 생성되는 연속 번호 사이의 간격을 지정합니다.
- MAXVALUE: 시퀀스가 생성할 수 있는 최대값을 지정합니다. a MAXVALUE를 지정하지 않으면 대부분의 데이터베이스에서 기본값은 2^31-1입니다.
- MINVALUE: 시퀀스가 생성할 수 있는 최소값을 지정합니다. a MINVALUE를 지정하지 않으면 대부분의 데이터베이스에서 기본값은 1입니다.
- CYCLE: 시퀀스가 에 도달하면 MINVALUE또는 값 에서 다시 시작할지 여부를 지정합니다 . 기본값은 입니다 . 즉, 시퀀스가 최대값에 도달하면 오류가 발생합니다.START WITHMAXVALUENO CYCLE
- CACHE: 빠른 액세스를 위해 미리 할당하고 메모리에 저장해야 하는 시퀀스 번호의 수를 지정합니다. 대부분의 데이터베이스에서 기본값은 일반적으로 20입니다.
- ORDER: 시퀀스가 순서대로 번호를 생성해야 하는지 여부를 지정합니다. 기본값은 NO ORDER입니다.
다음은 이러한 옵션 중 일부를 사용하여 SQL에서 시퀀스를 생성하는 방법의 예입니다.
CREATE SEQUENCE my_sequence
START WITH 1
INCREMENT BY 1
MINVALUE 1
MAXVALUE 10000
CYCLE
CACHE 20
ORDER;시퀀스 생성을 위한 정확한 구문은 사용 중인 특정 데이터베이스에 따라 다를 수 있습니다.
Q7. 해당 데이터에 왜 NULL값이 입력이 안되는거야?
제공 한 CREATE SEQUENCE문은 SQL에서 특정 순서로 고유한 번호를 생성하는 시퀀스 개체를 만드는 데 사용됩니다. 명령문( INCREMENT BY, START WITH, MAXVALUE, MINVALUE, NOCYCLE, 및 CACHE)에서 지정한 시퀀스 옵션은 시퀀스의 동작을 결정합니다.
NULL 값이 아닌 CREATE SEQUENCE숫자 값을 생성하기 위해 시퀀스를 사용하기 때문에 문장에 NULL 값을 입력할 수 없습니다. 명령문을 사용하면 시퀀스에 의해 생성된 실제 값 이 CREATE SEQUENCE아닌 시퀀스에 대한 옵션만 지정할 수 있습니다.
시퀀스를 만든 후에는 NEXT VALUE FOR절을 사용하여 시퀀스의 다음 번호를 생성할 수 있습니다. 그러면 예를 들어 열의 기본값으로 사용할 수 있습니다.
INSERT INTO your_table (column1, column2, ..., sequence_column)
VALUES (value1, value2, ..., NEXT VALUE FOR SEQ_DPET_SEQUENCE);Q8. 해당 조건을 8번 실행하라는 코드
--실행만 7번
INSERT INTO DEPT_SEQUENCE (DEPTNO,DNAME,LOC)
VALUES (SEQ_DEPT_SEQUENCE.NEXTVAL, 'DATABASE','SEOUL');
SELECT * FROM DEPT_SEQUENCE ORDER BY DEPTNO;
--1번 더 실행하면 에러, 이미 최대값 도달했기 때문--while문을 통한 실행 (AI)
DECLARE
i INTEGER := 1;
BEGIN
WHILE i <= 7 LOOP
INSERT INTO DEPT_SEQUENCE (DEPTNO, DNAME, LOC)
VALUES (SEQ_DEPT_SEQUENCE.NEXTVAL, 'DATABASE', 'SEOUL');
i := i + 1;
END LOOP;
END;
/
SELECT * FROM DEPT_SEQUENCE ORDER BY DEPTNO;Q9. CACHE는 왜 음수가 존재할 수 없는거야?
명령문 의 CACHE옵션은 CREATE SEQUENCE더 빠른 액세스를 위해 메모리에 미리 할당되고 저장되는 시퀀스 값의 수를 지정합니다.
CACHE음수 시퀀스 값을 사전 할당하는 것이 의미가 없기 때문에 옵션 에 음수를 지정할 수 없습니다 . 옵션 은 CACHE양의 정수여야 하며 필요하기 전에 메모리에 저장되는 시퀀스 값의 수를 결정합니다.
시퀀스의 다음 값이 필요한 경우 즉시 생성되는 대신 메모리에서 다음 값을 검색합니다. 이렇게 하면 특히 단기간에 많은 수의 시퀀스 값을 생성해야 하는 경우 성능이 향상될 수 있습니다. 그러나 CACHE너무 많은 시퀀스 값을 미리 할당하면 많은 메모리를 소비하고 성능에 부정적인 영향을 미칠 수 있으므로 설정에 유의해야 합니다.
Q10. MINVALUE 값에 NULL이 들어갈 수 없는 이유가 뭘까?
문의 MINVALUE옵션 CREATE SEQUENCE은 시퀀스에서 생성할 수 있는 최소값을 지정합니다. 옵션은 NULL 이 MINVALUE아닌 숫자 값이어야 합니다.
SQL에서 알 수 없거나 누락된 값을 나타내 므로 옵션 NULL에 대해 값을 지정할 수 없습니다 . 시퀀스를 만들 때 시퀀스 생성기가 생성할 수 있는 값의 범위를 알 수 있도록 최소값을 지정해야 합니다.MINVALUENULL
예를 들어 CREATE SEQUENCE제공한 문에서 MINVALUE옵션이 로 설정되어 있습니다. 0즉, 시퀀스에서 생성할 수 있는 가장 낮은 값은 입니다 0. NULL에 대한 값 을 지정하려고 MINVALUE하면 명령문이 오류와 함께 실패합니다.
Q11.SQL 객체에서 시퀀스에 대해 정확히 설명해줄래?
SQL에서 시퀀스는 사용될 때마다 고유 번호를 생성하는 데이터베이스 개체입니다. 시퀀스에 의해 생성된 숫자는 종종 테이블의 행에 대한 고유 식별자인 기본 키 값으로 사용됩니다.
CREATE SEQUENCE명령문을 사용하여 시퀀스를 생성 하고 다음 값은 NEXTVAL또는 CURRVAL의사 열을 사용하여 얻을 수 있습니다.
CREATE SEQUENCE명령문에는 시퀀스 동작을 제어하는 여러 옵션이 포함되어 있습니다 .
- START WITH: 시퀀스에서 생성할 첫 번째 값을 지정합니다.
- INCREMENT BY: 시퀀스에서 생성된 각 연속 값 간의 차이를 지정합니다.
- MAXVALUE: 시퀀스에서 생성할 수 있는 최대값을 지정합니다.
- MINVALUE: 시퀀스에서 생성할 수 있는 최소값을 지정합니다.
- CYCLE: 시퀀스가 최대값에 도달한 후 시작부터 값을 계속 생성할지 여부를 지정합니다.
- CACHE: 빠른 액세스를 위해 미리 할당하고 메모리에 저장할 값의 수를 지정합니다.
- NOCACHE: 값을 미리 할당하지 않도록 지정합니다.
시퀀스는 SQL에서 고유한 값을 생성하는 편리하고 효율적인 방법이며 고유한 기본 키 생성, 버전 번호 추적 또는 테이블의 행에 대한 고유 식별자 생성과 같은 다양한 방법으로 사용할 수 있습니다.
Q12. 그냥 시퀀스는 반복하는 것이라고 생각하면 될까?
예, 시퀀스가 반복되는 것으로 생각할 수 있지만 명령문 CYCLE에 지정된 옵션에 따라 다릅니다.CREATE SEQUENCE
CYCLE옵션을 로 설정하면 최대 CYCLE값( 으로 지정)에 도달한 후 시퀀스가 반복됩니다 MAXVALUE. 최대값에 도달하면 시퀀스는 최소값( 으로 지정 MINVALUE)에서 다시 시작하여 다시 최대값에 도달할 때까지 계속해서 값을 생성합니다.
CYCLE옵션으로 설정 하면 NOCYCLE 시퀀스가 반복되지 않습니다. 최대값에 도달하면 시퀀스 생성기가 중지되고 더 이상 값을 생성하지 않습니다.
따라서 시퀀스가 반복되는 것으로 생각할 수 있지만 실제로 반복되는지 여부 는 명령문 CYCLE에 지정된 옵션 에 따라 다릅니다.
Q13. 내 눈에는 시퀀스와 WHILE문과 같아 보이는데 맞아?
맞습니다. 일련의 값을 생성하거나 코드 블록을 반복할 수 있다는 점에서 시퀀스와 명령문 사이에 유사점이 있다고 말할 수 있습니다. 그러나 주요 차이점은 시퀀스는 일련의 고유 번호를 생성하는 반면 WHILE 명령문은 지정된 조건에 따라 코드 블록을 반복한다는 것입니다.
즉, 시퀀스는 주로 기본 키 또는 기타 식별자 열에 대한 고유한 값을 생성하는 데 사용되는 반면 WHILE명령문은 SQL에서 보다 범용적인 루핑 및 반복에 사용됩니다.
Q14. 그렇다면 빅데이터 의료 산업에서 WHILE문이 필요한 상황과 시퀀스가 필요한 상황이 무엇이 있을까?
빅 데이터 의료 산업에서 WHILE문과 시퀀스는 서로 다른 시나리오에서 유용할 수 있습니다. 다음은 몇 가지 예입니다.
- WHILE성명서: 대량의 의료 데이터를 처리할 때 WHILE루프를 사용하여 데이터를 반복하고 데이터 필터링, 집계 또는 변환과 같은 다양한 작업을 수행할 수 있습니다. 예를 들어 WHILE루프를 사용하여 대규모 전자 건강 기록(EHR) 데이터베이스에서 환자 데이터를 추출하고 데이터를 처리한 다음 추가 분석을 위해 데이터 웨어하우징 시스템에 삽입할 수 있습니다.
- 시퀀스: 의료 데이터에서 환자, 방문, 진단 및 기타 엔터티에 대한 고유 식별자 값을 생성해야 하는 경우가 많습니다. 시퀀스를 사용하여 일관되고 고유한 방식으로 이러한 값을 생성할 수 있습니다. 예를 들어 고유한 환자 ID를 생성하는 시퀀스를 생성한 다음 NEXTVAL함수를 사용하여 생성된 ID를 환자 테이블에 삽입할 수 있습니다.
- 모두: 경우에 따라 WHILE루프와 시퀀스를 함께 사용할 수 있습니다. 예를 들어 WHILE루프를 사용하여 EHR 시스템에서 환자 데이터를 추출하고 시퀀스를 사용하여 데이터가 처리될 때 각 환자에 대한 고유 식별자 값을 생성할 수 있습니다.
이는 몇 가지 예에 불과하지만 WHILE프로젝트의 특정 요구 사항과 요구 사항에 따라 빅 데이터 의료 산업에서 명령문과 시퀀스를 사용할 수 있는 다른 많은 가능성이 있습니다.
Q15. 반복문을 생성하고 싶다면?
PL_SQL를 사용해라
Q16. SQL 객체에서 동의어에 대해 설명해줄래?
SQL에서 동의어는 테이블, 뷰 또는 저장 프로시저와 같은 다른 데이터베이스 개체에 대한 참조입니다. 참조된 개체의 별칭 또는 별칭 역할을 합니다. 동의어 사용의 주요 이점은 추상화 및 캡슐화 수준을 제공하여 이를 참조하는 코드에 영향을 주지 않고 기본 개체를 변경할 수 있다는 것입니다.
예를 들어 원격 데이터베이스에 있는 "EMPLOYEES"라는 테이블의 동의어를 만들 수 있습니다. 이렇게 하면 전체 테이블 이름 대신 동의어 이름을 사용하여 마치 로컬 테이블인 것처럼 원격 테이블에 액세스할 수 있습니다. 기본 테이블의 이름이 변경되거나 이동된 경우 코드에서 테이블에 대한 모든 참조를 변경하는 대신 동의어 정의만 수정하면 됩니다.
다음은 SQL에서 동의어를 만드는 방법의 예입니다.
CREATE SYNONYM employees_synonym FOR remote_schema.employees;동의어를 만든 후에는 원래 테이블 이름을 사용하는 것처럼 SQL 문에서 사용할 수 있습니다.
SELECT * FROM employees_synonym;동의어는 사용자 또는 스키마에 따라 다르므로 여러 사용자 또는 스키마에서 동일한 개체에 액세스해야 하는 경우 각각에 대해 별도의 동의어를 생성해야 합니다.
Q17. 이게 왜 안될까? Q3번 문제 358P
INSERT ALL
INTO DEPT_SEQUENCE VALUES (SEQ_DEPT_SEQUENCE.NEXTVAL, 'DATABASE', 'SEOUL')
INTO DEPT_SEQUENCE VALUES (SEQ_DEPT_SEQUENCE.NEXTVAL, 'WEB', 'BUSAN')
INTO DEPT_SEQUENCE VALUES (SEQ_DEPT_SEQUENCE.NEXTVAL, 'MOBILE', 'ILSAN')
SELECT SEQ_DEPT_SEQUENCE.CURRVAL FROM DUAL;
SELECT * FROM DEPT_SEQUENCE;이 구가 작동하지 않는 이유는 문의 구문 INSERT ALL이 올바르지 않기 때문입니다. 이 INSERT ALL명령문은 단일 테이블 또는 단일 명령문의 여러 테이블에 여러 행을 삽입하는 데 사용되지만 값을 반환하지 않습니다.
시퀀스의 현재 값을 반환하려면 다음과 같이 명령문 뒤에 명령문을 SEQ_DEPT_SEQUENCE사용할 수 있습니다 .SELECT, INSERT
INSERT INTO DEPT_SEQUENCE (DEPTNO, DNAME, LOC)
VALUES (SEQ_DEPT_SEQUENCE.NEXTVAL, 'DATABASE', 'SEOUL');
INSERT INTO DEPT_SEQUENCE (DEPTNO, DNAME, LOC)
VALUES (SEQ_DEPT_SEQUENCE.NEXTVAL, 'WEB', 'BUSAN');
INSERT INTO DEPT_SEQUENCE (DEPTNO, DNAME, LOC)
VALUES (SEQ_DEPT_SEQUENCE.NEXTVAL, 'MOBILE', 'ILSAN');
SELECT SEQ_DEPT_SEQUENCE.CURRVAL FROM DUAL;
SELECT * FROM DEPT_SEQUENCE;이 예에서 각 INSERT명령문은 단일 행을 DEPT_SEQUENCE 테이블에 삽입 SELECT하고
끝에 있는 명령문은 시퀀스의 현재 값을 반환합니다 , SEQ_DEPT_SEQUENCE.
Q18. 왜 DEPTNO에 해당하는 SEQ_DEPTSEQ_SEQUENCE.NEXTVAL 값이 중복되는지 모르겠어. 숫자가 순차적으로 안나오는 이유가 뭐야? : Q3번 문제 358P
INSERT ALL
INTO DEPTSEQ VALUES (SEQ_DEPTSEQ_SEQUENCE.NEXTVAL, 'DATABASE', 'SEOUL')
INTO DEPTSEQ VALUES (SEQ_DEPTSEQ_SEQUENCE.NEXTVAL, 'WEB', 'BUSAN')
INTO DEPTSEQ VALUES (SEQ_DEPTSEQ_SEQUENCE.NEXTVAL, 'MOBILE', 'ILSAN')
SELECT * FROM DUAL;
Oracle의 시퀀스는 고유하고 점진적인 값을 생성하도록 설계되었습니다. 값이 순차적으로 나오지 않으면 다음과 같은 몇 가지 이유 때문일 수 있습니다.
- 순서가 변경됨: 증분 값, 시작 값 또는 최대값/최소값을 변경하도록 순서가 변경되어 중복 값을 생성할 수 있습니다.
- 캐시가 고갈되었습니다: 특정 수의 값을 캐시하도록 시퀀스를 설정할 수 있으며, 해당 값이 모두 사용된 경우 생성되는 다음 값은 시퀀스의 다음 값이 되며, 이는 중복일 수 있습니다.
- 시퀀스에 대한 동시 액세스: 여러 트랜잭션이 동시에 시퀀스에 액세스하는 경우 여러 트랜잭션이 동일한 시퀀스 값을 얻을 수 있습니다.
- 롤백 또는 커밋 문제: 시퀀스를 사용하는 트랜잭션이 롤백되면 해당 트랜잭션에서 사용한 시퀀스 값이 손실되어 다시 사용되지 않습니다.
시퀀스 사용을 모니터링하고 중복을 피하기 위해 적절한 설정이 있는지 확인하는 것이 중요합니다. 이 문제를 해결하기 위해 시퀀스를 변경하여 증분 값, 캐시 크기 또는 시작 값을 변경할 수 있습니다. 중복을 피하기 위해 정렬할 시퀀스를 설정할 수도 있습니다.
차이가 없음
* SEQ_DEPTSEQ_SEQUENCE.NEXTVAL에 관해서 문제가 생긴게 아닐까? 이유를 알려줘
그리고 해결 법을 알려줘
시퀀스가 캐시되고 있을 가능성이 있습니다. 즉, 한 번에 하나씩 검색되는 대신 데이터베이스에 대한 단일 왕복으로 여러 값이 검색되고 있음을 의미합니다. 여러 동시 트랜잭션이 시퀀스에 액세스하는 경우 중복이 발생할 수 있습니다. 이를 방지하기 위해 시퀀스의 캐시 크기를 1로 설정할 수 있습니다. 다음 명령을 실행하여 이를 수행할 수 있습니다.
ALTER SEQUENCE SEQ_DEPTSEQ_SEQUENCE 캐시 1;
CREATE SEQUENCE SEQ_DEPTSEQ_SEQUENCE
START WITH 1
INCREMENT BY 1
MAXVALUE 99
MINVALUE 1
NOCYCLE
CACHE 1;
차이가 없음
* DEPTNO 값이 1,2,3으로 나와야 하는 아래의 쿼리가 DEPTNO 값이 1,1,1로 나왔어 이유에 대해 알려줄 수 있니?
그리고 해결 법을 알려줘
시퀀스 "SEQ_DEPTSEQ_SEQUENCE"는 메모리에 특정 수의 값을 캐시하도록 설정되어 NEXTVAL에 대한 후속 호출이 데이터베이스에 도달하지 않고 값을 반환할 수 있습니다. 이로 인해 행이 동일한 캐시 주기 내에 삽입되는 경우 동일한 DEPTNO 값을 갖는 테이블의 여러 행이 생성될 수 있습니다. 이 문제를 해결하려면 캐시 크기를 1로 설정하거나 커밋 빈도를 늘려 캐시를 플러시하고 새 주기를 시작할 수 있습니다.
위와 같은 답안. 차이가 없음.
INSERT ALL
INTO DEPTSEQ VALUES (SEQ_DEPTSEQ_SEQUENCE.NEXTVAL, 'DATABASE', 'SEOUL')
INTO DEPTSEQ VALUES (SEQ_DEPTSEQ_SEQUENCE.NEXTVAL+1, 'WEB', 'BUSAN')
INTO DEPTSEQ VALUES (SEQ_DEPTSEQ_SEQUENCE.NEXTVAL+2, 'MOBILE', 'ILSAN')
SELECT * FROM DUAL;해당 문법을 사용하면 해결 되긴 함.

Q19. 그럼 위와 같이 NEXTVAL에 +1을 입력하면 안되는 이유가 뭐야? Q3번 문제 358P
SEQ_DEPTSEQ_SEQUENCE.NEXTVAL+1여러 세션이 동일한 쿼리를 동시에 실행하는 경우 DEPTNO 값이 중복될 수 있으므로 및 SEQ_DEPTSEQ_SEQUENCE.NEXTVAL+2DEPTNO 값으로 사용 SEQ_DEPTSEQ_SEQUENCE.NEXTVAL하는 것은 실제로 권장되지 않습니다. 시퀀스는 고유 번호를 생성하며 두 세션이 동시에 시퀀스에서 다음 값을 검색하면 둘 다 동일한 번호를 수신하여 테이블에 삽입될 때 중복됩니다.
SEQ_DEPTSEQ_SEQUENCE.NEXTVAL테이블에 삽입된 각 행이 고유한 DEPTNO 값을 갖도록 항상 값 목록에서 사용하는 시퀀스에서 다음 값을 검색하는 것이 좋습니다
* 해당 문제에 대한 총 정리
- INSERT ALL은 한번 실행할 때 동시에 실행하기 때문에 NEXTVAL을 쓰면 1을 출력한다.
- 그냥 조용하게 INSERT INTO를 쓰자. INTO를 줄이기 위해 여러개를 찾아봐도 오히려 쓸 코딩 양만 늘어난다.
Q20. SQL에서 CURRVAL이 뭐야 설명해줘
SQL에서 'CURRVAL' Oracle과 같은 데이터베이스의 시퀀스와 함께 사용되는 의사 시퀀스 함수입니다. 시퀀스 개체의 현재 값을 반환합니다. 함수는 새로운 시퀀스 값을 생성하기 위해 함수 CURRVAL가 사용된 후에 사용됩니다. NEXTVAL이 CURRVAL함수는 가장 최근 함수에 의해 생성된 시퀀스의 현재 값을 반환합니다 NEXTVAL.
예를 들어 다음 코드를 사용하여 새 시퀀스 값을 생성한 다음 다음을 사용하여 값을 검색할 수 있습니다 CURRVAL
INSERT INTO mytable (id, name) VALUES (myseq.NEXTVAL, 'John Doe');
SELECT myseq.CURRVAL FROM DUAL;
Q21. 시퀀스 생성문에서 ORDER를 쓰는 것과 쓰지 않는 것의 차이
시퀀스 생성 문에서 "ORDER"의 역할은 시퀀스가 생성되는 순서를 지정하는 것입니다. 이 옵션은 일반적으로 각 시퀀스가 올바른 순서로 생성되도록 여러 시퀀스가 병렬로 생성될 때 사용됩니다. "ORDER" 옵션을 지정하지 않으면 시퀀스가 정의되지 않은 순서로 생성되어 예기치 않은 결과가 발생할 수 있습니다. 시퀀스 생성문에 지정된 대로 시퀀스가 올바른 순서로 생성되도록 병렬로 시퀀스를 생성할 때 "ORDER" 옵션을 사용하는 것이 중요합니다.
Q22. 시퀀스 문제 해결
--수정방법 인라인뷰를 사용한 것이지만 (FOR문을 돌리는 것)
INSERT ALL
INTO DEPTSEQ
SELECT SEQ_DEPTSEQ_SEQUENCE, SB.*
FROM (SELECT 'DATABASE', 'SEOUL' FROM DUAL
UNION ALL
SELECT 'WEB', 'BUSAN' FROM DUAL
UNION ALL
SELECT 'MOBILE', 'ILSAN' FROM DUAL
) ;다중 인설트를 쓰지 말고 해당 문제 해결 // 또는 포문으로 해결
'개인공부 정리 > 다양한 질문들' 카테고리의 다른 글
| 0209 수업 질문 - PL/SQL, 커서와 예외처리 (0) | 2023.02.09 |
|---|---|
| 0208 수업 질문 - 제약 조건 및 사용자, 권한, 롤 관리 (0) | 2023.02.08 |
| 0206 수업 질문 - 데이터 조작어, 트랜잭션, 데이터 정의어 (0) | 2023.02.06 |
| 0203 수업 질문 - 조인(JOIN), 서브쿼리, DML (0) | 2023.02.03 |
| 0202 수업 질문 - 형 변환 함수, 날짜 함수 (0) | 2023.02.02 |



