7장 머신러닝 데이터 분석
1. 머신러닝에 대해
1) 머신러닝 1
- 지도 학습 : 종속 변수 y를 토대로 정답이 있는 상태에서 회귀 분석(숫자) 분류를 한다.
- 비지도 학습 : 종속 변수 y를 토대로 정답이 없는 상태에서 군집 분석을 한다
단순 회귀 : x 변수 2개 이상 => y변수 1개(단순회귀) -> 학습, 파라미터, 개수
다중처리 : 소득 -> 소비 -> 다항 회귀
최종으로 구하고자 하는 값 : 절편, 기울기, 예측치
2) 머신러닝 2
지도학습 - 분류 - 그룹(범주형 변수) - 이진 분류 // 다층 분류
선형회귀 vs 로지스틱 회귀분석 (로지스틱 함수)
KNN : 다수결의 원칙으로 분류하는 알고리즘
3) 머신러닝 3 - 모형 평가 (confusion matrix)

모형 평가 - 회귀 (결정계수) // 분류 (정확도)
예측값과 실제값을 토대로 Postive, Negative를 판단함(T/F)
- 정확도 accuracy = prectston : 예측한 것 중에서 실제로 1인 비율 // 공식 : TP / TP+FP
- 재현율 = recall : 실제로 1인것 중에서 1이라고 예측한 비율 // 공식 : TP / TP+FN
- FL SCORE = 종합평가 (예측력) // 공식 : 2*a*b / a+b
4) 머신러닝 분류 모델
- KNN
- DT
- SVM
KNN(K-Nearest Neighbor) KNN은 지도 학습(Supervised Learning) 분류 알고리즘 중 하나로,
새로운 데이터를 분류할 때 가장 가까운 K개의 이웃 데이터들의 레이블을 확인하여 새로운 데이터가 어떤 클래스에 속하는지 판단하는 방법입니다. 이웃 데이터들의 거리 측정 방법에 따라 유클리드 거리, 맨하탄 거리 등의 방법을 사용할 수 있으며, K값을 조정하여 분류 정확도를 조절할 수 있습니다.
DT(Decision Tree) DT는 지도 학습 분류 알고리즘 중 하나로, 의사 결정 과정을 나무 구조로 표현한 것입니다. 이를 이용하여 새로운 데이터를 분류할 때, 나무 구조를 따라 분류하는 방법을 사용합니다. 이를 위해 각 노드마다 최적의 분기 기준을 찾아 분류 기준을 계속해서 세분화해가는 과정을 반복합니다. DT는 해석력이 높고, 데이터 전처리 과정이 필요하지 않으며, 이상치(Outlier)에 강건합니다.
SVM(Support Vector Machine) SVM은 지도 학습 분류 알고리즘 중 하나로, 두 개의 클래스를 분류하기 위해 초평면(Hyperplane)을 찾는 것을 목표로 합니다. 이를 위해 서포트 벡터(Support Vector)를 찾고, 이를 기반으로 최대 마진(Maximum Margin)을 가지는 초평면을 찾습니다. SVM은 데이터의 차원이 높을 때도 잘 작동하며, 이상치에 민감하지 않습니다. 다만, 초평면의 결정 경계가 선형적인 형태를 갖는 경우에만 사용할 수 있습니다.
2. 머신러닝 실습
1) 다중 회귀 모델
* 데이터 준비 ~ 데이터 탐색
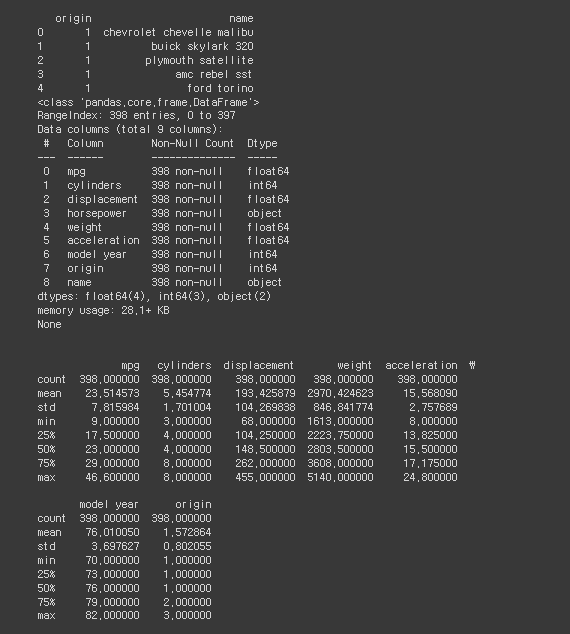
# 7장 머신러닝
# 데이터 준비
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# CSV 파일을 데이터프레임으로 변환
df = pd.read_csv(r"/content/drive/MyDrive/BDA/part3/auto-mpg.csv", header=None)
df.columns=["mpg","cylinders","displacement","horsepower","weight",
"acceleration","model year","origin","name"]
print(df.head())
print("\n")
# Ipython 디스플레이 설정 - 출력할 열의 개수 한도 늘리기
pd.set_option("display.max_columns", 10) # 출력할 열의 최대 개수
print(df.head())
# %%
# 데이터 탐색
# 데이터 자료형 확인
print(df.info())
print("\n")
# 데이터 통계 요약 정보 확인
print(df.describe())
* 변수 선택 ~ 데이터 분할 ~ 알고리즘 생성
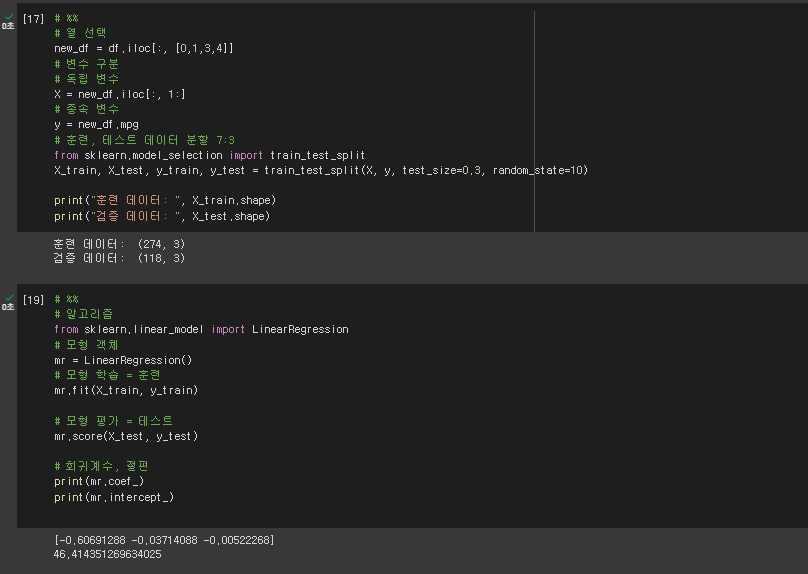
# %%
# 열 선택
new_df = df.iloc[:, [0,1,3,4]]
# 변수 구분
# 독립 변수
X = new_df.iloc[:, 1:]
# 종속 변수
y = new_df.mpg
# 훈련, 테스트 데이터 분할 7:3
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)
print("훈련 데이터: ", X_train.shape)
print("검증 데이터: ", X_test.shape)
# %%
# 알고리즘
from sklearn.linear_model import LinearRegression
# 모형 객체
mr = LinearRegression()
# 모형 학습 = 훈련
mr.fit(X_train, y_train)
# 모형 평가 = 테스트
mr.score(X_test, y_test)
# 회귀계수, 절편
print(mr.coef_)
print(mr.intercept_)
* 예측값과 비교 (그래프 생성)
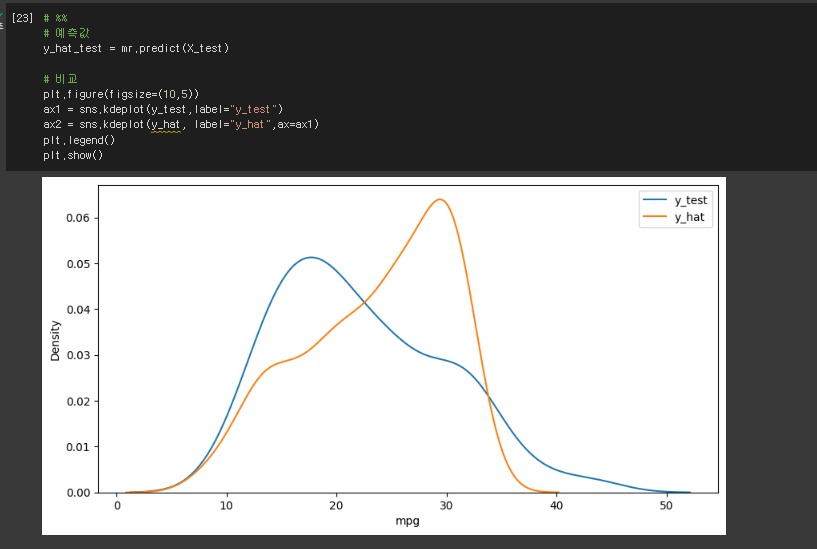
# %%
# 예측값
y_hat_test = mr.predict(X_test)
# 비교
plt.figure(figsize=(10,5))
ax1 = sns.kdeplot(y_test,label="y_test")
ax2 = sns.kdeplot(y_hat, label="y_hat",ax=ax1)
plt.legend()
plt.show()
2) 분류 모델 - KNN
* 알고리즘 생성 ~ 데이터 탐색
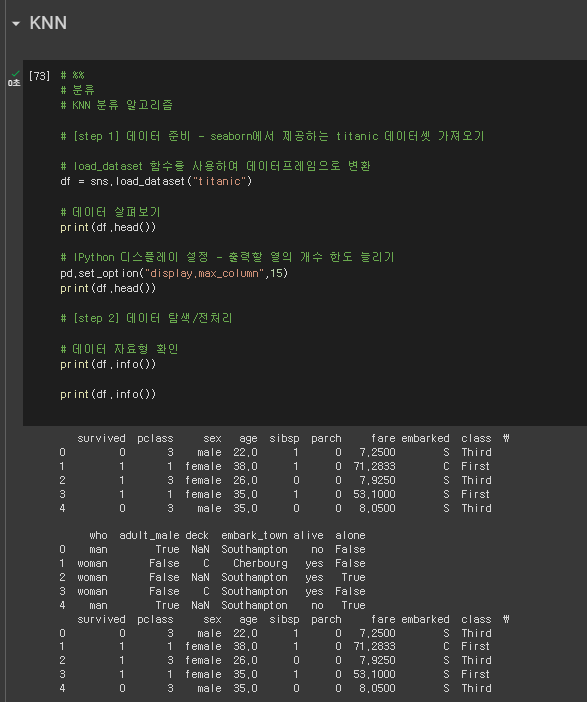
# %%
# 분류
# KNN 분류 알고리즘
# [step 1] 데이터 준비 - seaborn에서 제공하는 titanic 데이터셋 가져오기
# load_dataset 함수를 사용하여 데이터프레임으로 변환
df = sns.load_dataset("titanic")
# 데이터 살펴보기
print(df.head())
# IPython 디스플레이 설정 - 출력할 열의 개수 한도 늘리기
pd.set_option("display.max_column",15)
print(df.head())
# [step 2] 데이터 탐색/전처리
# 데이터 자료형 확인
print(df.info())
print(df.info())
* 전처리 ~ NaN 값 치환하기
# %%
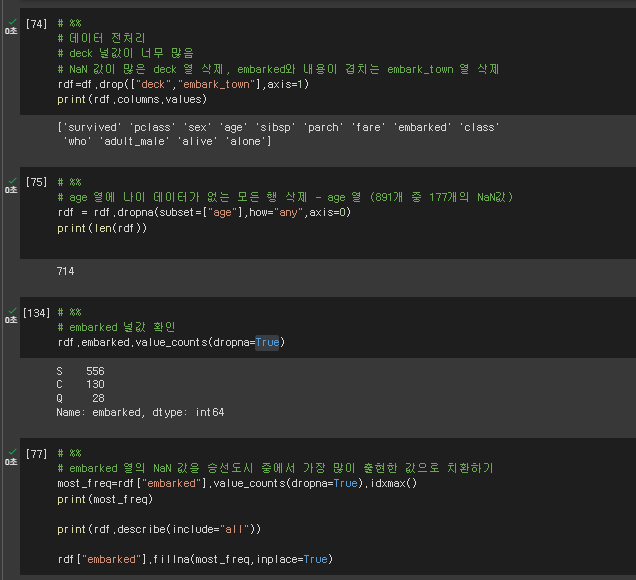
# 데이터 전처리
# deck 널값이 너무 많음
# NaN 값이 많은 deck 열 삭제, embarked와 내용이 겹치는 embark_town 열 삭제
rdf=df.drop(["deck","embark_town"],axis=1)
print(rdf.columns.values)
# %%
# age 열에 나이 데이터가 없는 모든 행 삭제 - age 열 (891개 중 177개의 NaN값)
rdf = rdf.dropna(subset=["age"],how="any",axis=0)
print(len(rdf))
# %%
# embarked 널값 확인
rdf.embarked.value_counts(dropna=True)
# %%
# embarked 열의 NaN 값을 승선도시 중에서 가장 많이 출현한 값으로 치환하기
most_freq=rdf["embarked"].value_counts(dropna=True).idxmax()
print(most_freq)
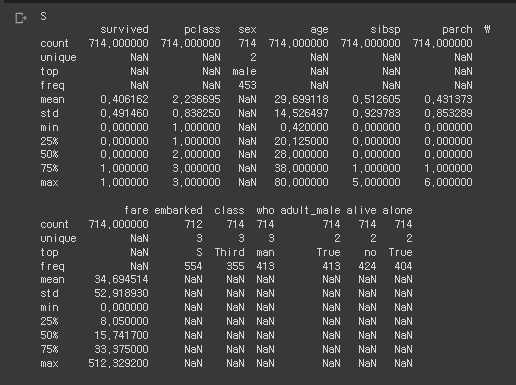
print(rdf.describe(include="all"))
rdf["embarked"].fillna(most_freq,inplace=True)
* 속성 선택 ~ 원핫인코딩(범주형 데이터 -> 숫자형 변환) ~ 변수 제거 및 더미 변수
# %%
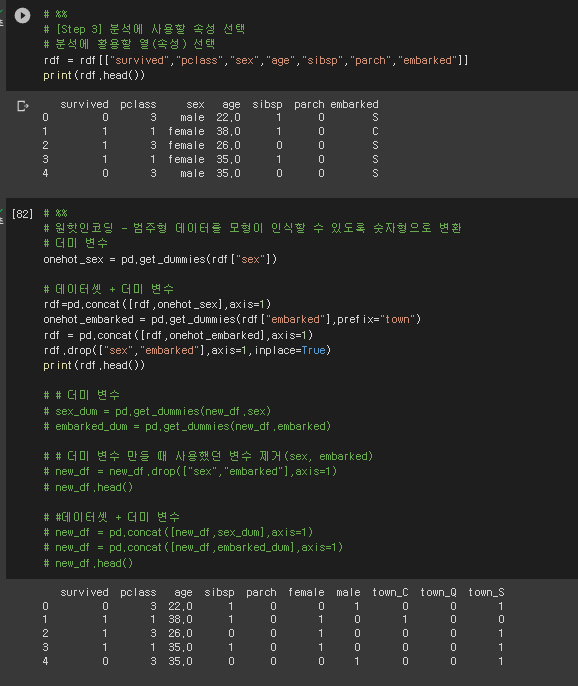
# [Step 3] 분석에 사용할 속성 선택
# 분석에 활용할 열(속성) 선택
rdf = rdf[["survived","pclass","sex","age","sibsp","parch","embarked"]]
print(rdf.head())
# %%
# 원핫인코딩 - 범주형 데이터를 모형이 인식할 수 있도록 숫자형으로 변환
# 더미 변수
onehot_sex = pd.get_dummies(rdf["sex"])
# 데이터셋 + 더미 변수
rdf=pd.concat([rdf,onehot_sex],axis=1)
onehot_embarked = pd.get_dummies(rdf["embarked"],prefix="town")
rdf = pd.concat([rdf,onehot_embarked],axis=1)
rdf.drop(["sex","embarked"],axis=1,inplace=True)
print(rdf.head())
# # 더미 변수
# sex_dum = pd.get_dummies(new_df.sex)
# embarked_dum = pd.get_dummies(new_df.embarked)
# # 더미 변수 만들 때 사용했던 변수 제거(sex, embarked)
# new_df = new_df.drop(["sex","embarked"],axis=1)
# new_df.head()
# #데이터셋 + 더미 변수
# new_df = pd.concat([new_df,sex_dum],axis=1)
# new_df = pd.concat([new_df,embarked_dum],axis=1)
# new_df.head()
* 훈련/검증 데이터 분할 (정규화 과정 및 구분 과정) ~ 모형 학습 및 검증
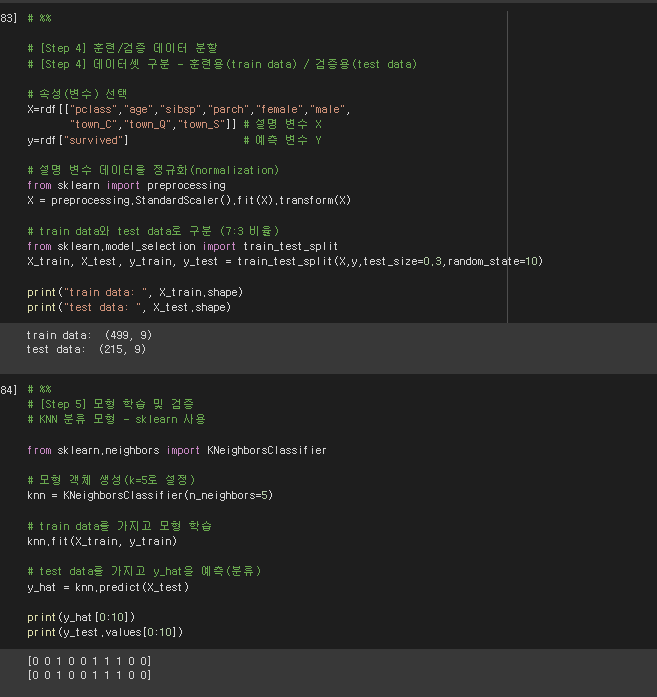
# %%
# [Step 4] 훈련/검증 데이터 분할
# [Step 4] 데이터셋 구분 - 훈련용(train data) / 검증용(test data)
# 속성(변수) 선택
X=rdf[["pclass","age","sibsp","parch","female","male",
"town_C","town_Q","town_S"]] # 설명 변수 X
y=rdf["survived"] # 예측 변수 Y
# 설명 변수 데이터를 정규화(normalization)
from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X)
# train data와 test data로 구분 (7:3 비율)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3,random_state=10)
print("train data: ", X_train.shape)
print("test data: ", X_test.shape)
# %%
# [Step 5] 모형 학습 및 검증
# KNN 분류 모형 - sklearn 사용
from sklearn.neighbors import KNeighborsClassifier
# 모형 객체 생성(k=5로 설정)
knn = KNeighborsClassifier(n_neighbors=5)
# train data를 가지고 모형 학습
knn.fit(X_train, y_train)
# test data를 가지고 y_hat을 예측(분류)
y_hat = knn.predict(X_test)
print(y_hat[0:10])
print(y_test.values[0:10])
* 모형 성능 평가 // f1 score 확인
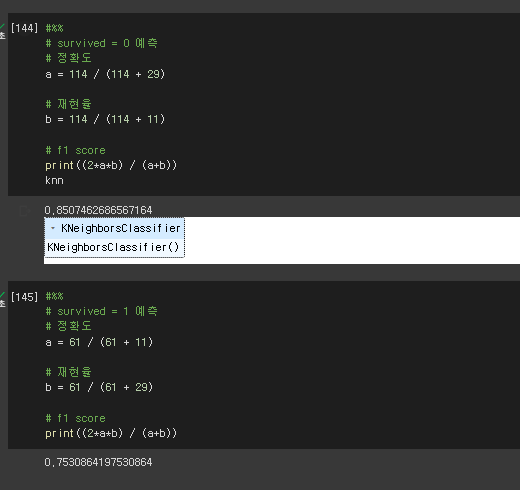
#%%
# survived = 0 예측
# 정확도
a = 114 / (114 + 29)
# 재현율
b = 114 / (114 + 11)
# f1 score
print((2*a*b) / (a+b))
knn
#%%
# survived = 1 예측
# 정확도
a = 61 / (61 + 11)
# 재현율
b = 61 / (61 + 29)
# f1 score
print((2*a*b) / (a+b))
3) 분류 모델 - DT
* 데이터 가져오기 ~ 데이터 탐색
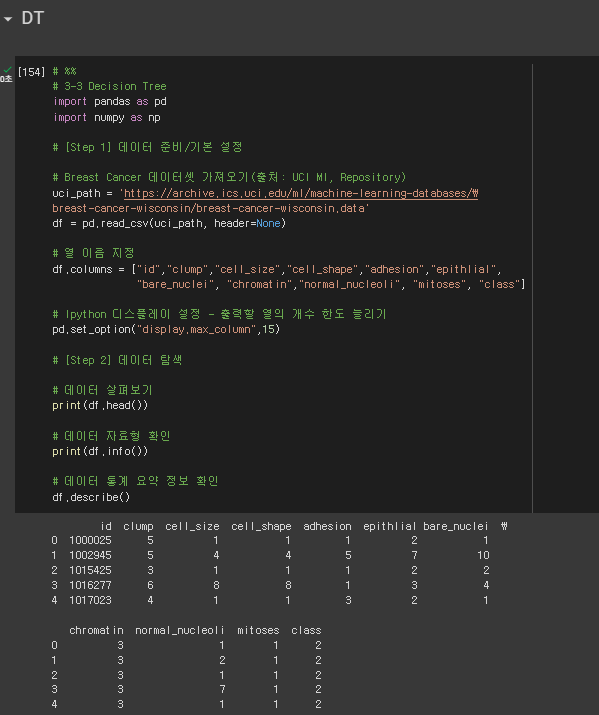
# %%
# 3-3 Decision Tree
import pandas as pd
import numpy as np
# [Step 1] 데이터 준비/기본 설정
# Breast Cancer 데이터셋 가져오기(출처: UCI MI, Repository)
uci_path = 'https://archive.ics.uci.edu/ml/machine-learning-databases/\
breast-cancer-wisconsin/breast-cancer-wisconsin.data'
df = pd.read_csv(uci_path, header=None)
# 열 이름 지정
df.columns = ["id","clump","cell_size","cell_shape","adhesion","epithlial",
"bare_nuclei", "chromatin","normal_nucleoli", "mitoses", "class"]
# Ipython 디스플레이 설정 - 출력할 열의 개수 한도 늘리기
pd.set_option("display.max_column",15)
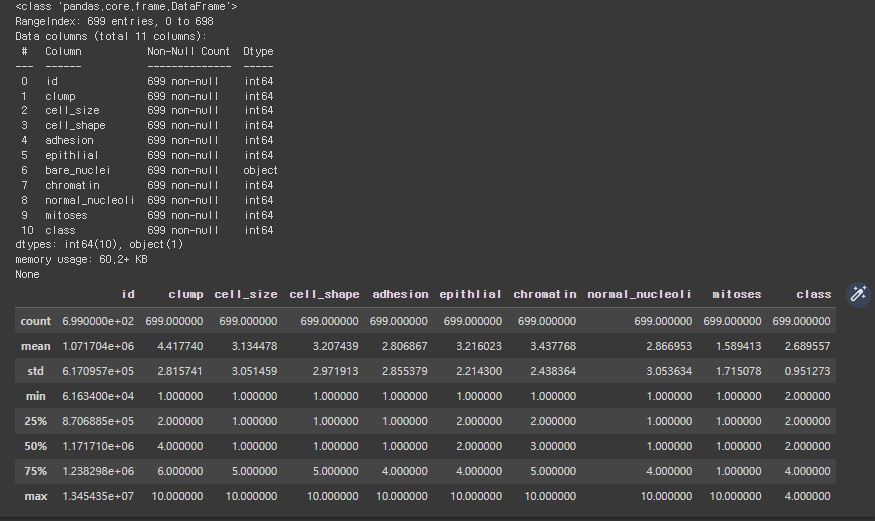
# [Step 2] 데이터 탐색
# 데이터 살펴보기
print(df.head())
# 데이터 자료형 확인
print(df.info())
# 데이터 통계 요약 정보 확인
df.describe()
* 데이터 전처리
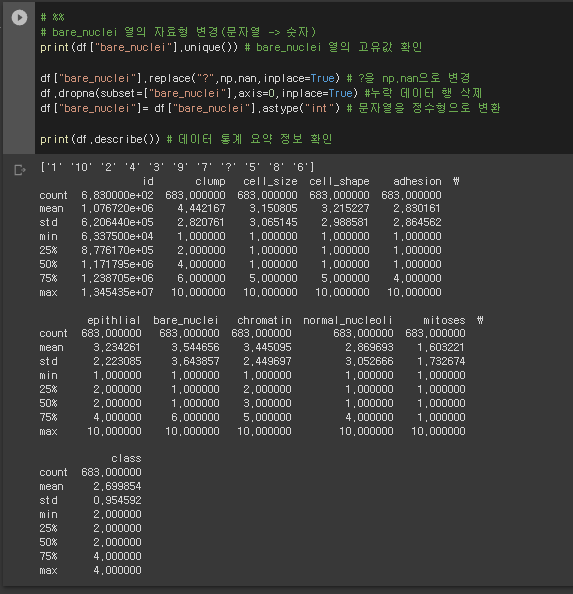
# %%
# bare_nuclei 열의 자료형 변경(문자열 -> 숫자)
print(df["bare_nuclei"].unique()) # bare_nuclei 열의 고유값 확인
df["bare_nuclei"].replace("?",np.nan,inplace=True) # ?을 np.nan으로 변경
df.dropna(subset=["bare_nuclei"],axis=0,inplace=True) #누락 데이터 행 삭제
df["bare_nuclei"]= df["bare_nuclei"].astype("int") # 문자열을 정수형으로 변환
print(df.describe()) # 데이터 통계 요약 정보 확인
* 데이터셋 구분 - 훈련용/검증용
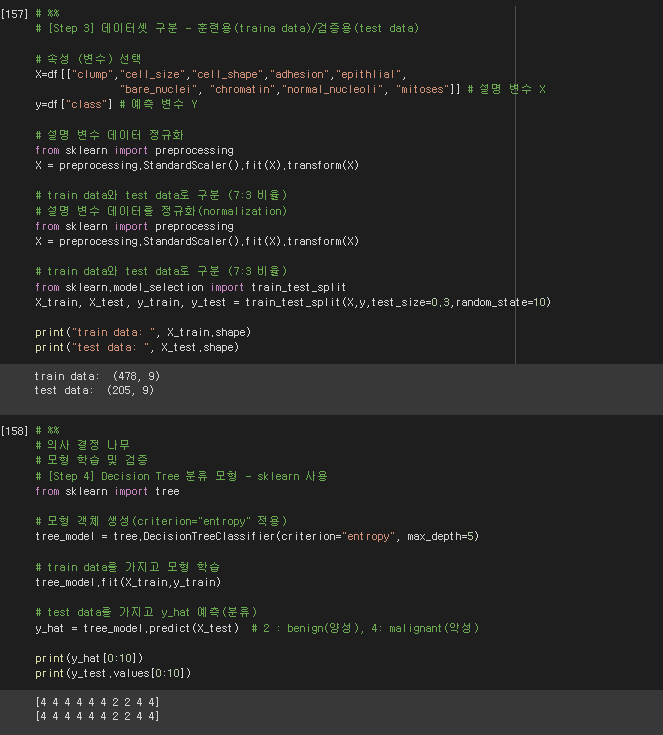
# %%
# [Step 3] 데이터셋 구분 - 훈련용(traina data)/검증용(test data)
# 속성 (변수) 선택
X=df[["clump","cell_size","cell_shape","adhesion","epithlial",
"bare_nuclei", "chromatin","normal_nucleoli", "mitoses"]] # 설명 변수 X
y=df["class"] # 예측 변수 Y
# 설명 변수 데이터 정규화
from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X)
# train data와 test data로 구분 (7:3 비율)
# 설명 변수 데이터를 정규화(normalization)
from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X)
# train data와 test data로 구분 (7:3 비율)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3,random_state=10)
print("train data: ", X_train.shape)
print("test data: ", X_test.shape)
# %%
# 의사 결정 나무
# 모형 학습 및 검증
# [Step 4] Decision Tree 분류 모형 - sklearn 사용
from sklearn import tree
# 모형 객체 생성(criterion="entropy" 적용)
tree_model = tree.DecisionTreeClassifier(criterion="entropy", max_depth=5)
# train data를 가지고 모형 학습
tree_model.fit(X_train,y_train)
# test data를 가지고 y_hat 예측(분류)
y_hat = tree_model.predict(X_test) # 2 : benign(양성), 4: malignant(악성)
print(y_hat[0:10])
print(y_test.values[0:10])
* 모형 성능 평가 - Confusion Matrix 계산
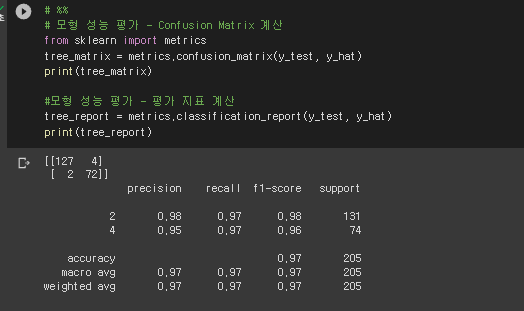
# %%
# 모형 성능 평가 - Confusion Matrix 계산
from sklearn import metrics
tree_matrix = metrics.confusion_matrix(y_test, y_hat)
print(tree_matrix)
#모형 성능 평가 - 평가 지표 계산
tree_report = metrics.classification_report(y_test, y_hat)
print(tree_report)
4) 분류 모델 - DT2 (시각화)
* 데이터 준비 ~ 데이터 탐색
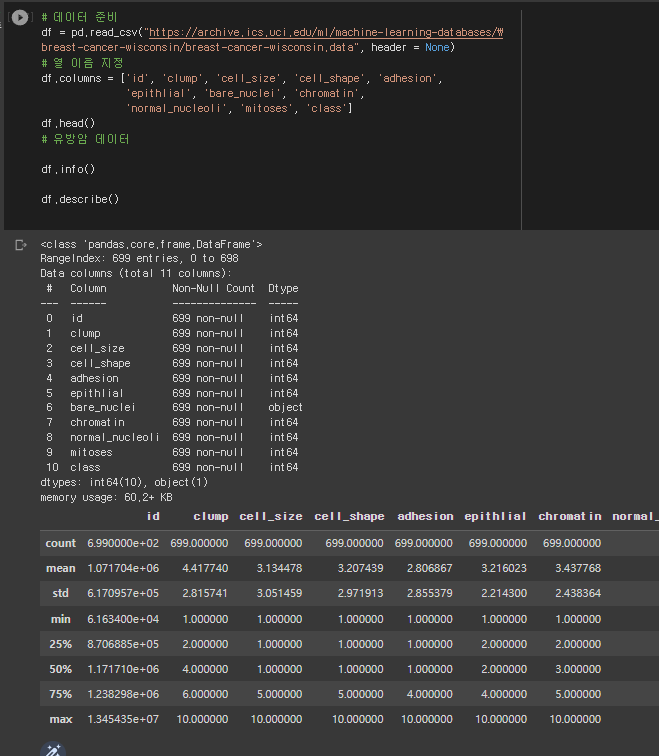
# 데이터 준비
df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/\
breast-cancer-wisconsin/breast-cancer-wisconsin.data", header = None)
# 열 이름 지정
df.columns = ['id', 'clump', 'cell_size', 'cell_shape', 'adhesion',
'epithlial', 'bare_nuclei', 'chromatin',
'normal_nucleoli', 'mitoses', 'class']
df.head()
# 유방암 데이터
df.info()
df.describe()
* 데이터 전처리 ~ 훈련, 테스트 데이터 분할
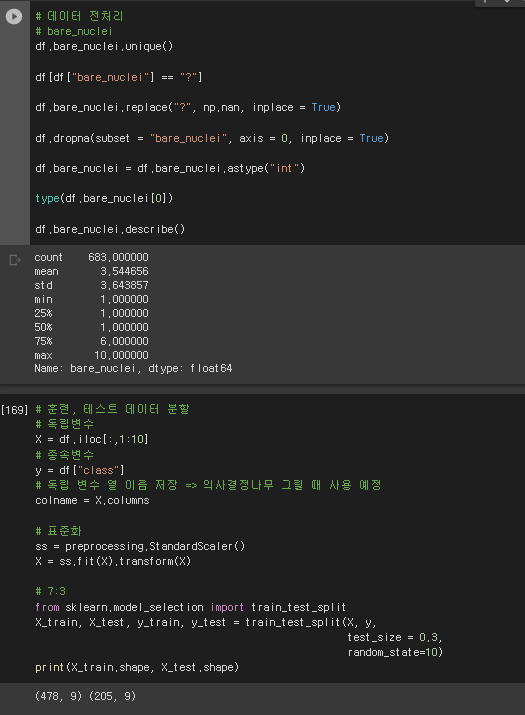
# 데이터 전처리
# bare_nuclei
df.bare_nuclei.unique()
df[df["bare_nuclei"] == "?"]
df.bare_nuclei.replace("?", np.nan, inplace = True)
df.dropna(subset = "bare_nuclei", axis = 0, inplace = True)
df.bare_nuclei = df.bare_nuclei.astype("int")
type(df.bare_nuclei[0])
df.bare_nuclei.describe()
# 훈련, 테스트 데이터 분할
# 독립변수
X = df.iloc[:,1:10]
# 종속변수
y = df["class"]
# 독립 변수 열 이름 저장 => 의사결정나무 그릴 때 사용 예정
colname = X.columns
# 표준화
ss = preprocessing.StandardScaler()
X = ss.fit(X).transform(X)
# 7:3
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 0.3,
random_state=10)
print(X_train.shape, X_test.shape)
* 의사 결정 나무
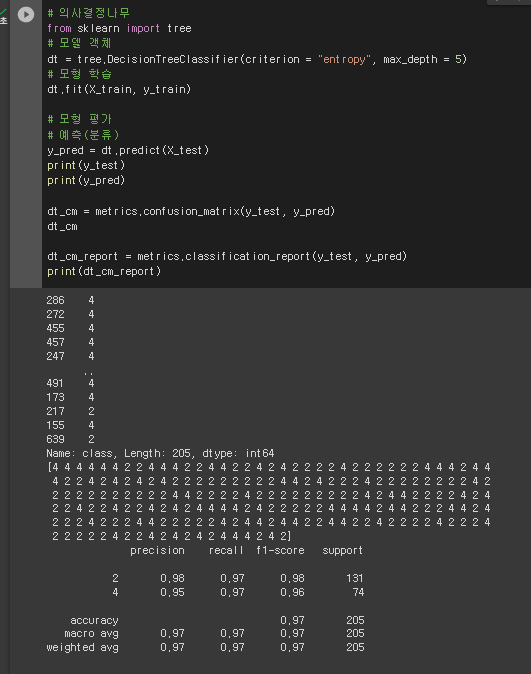
# 의사결정나무
from sklearn import tree
# 모델 객체
dt = tree.DecisionTreeClassifier(criterion = "entropy", max_depth = 5)
# 모형 학습
dt.fit(X_train, y_train)
# 모형 평가
# 예측(분류)
y_pred = dt.predict(X_test)
print(y_test)
print(y_pred)
dt_cm = metrics.confusion_matrix(y_test, y_pred)
dt_cm
dt_cm_report = metrics.classification_report(y_test, y_pred)
print(dt_cm_report)
* 양성클래스 확인
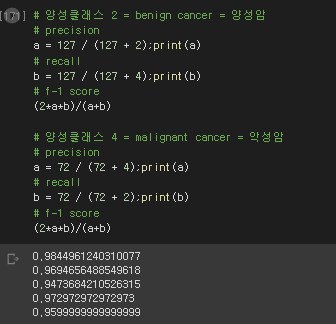
# 양성클래스 2 = benign cancer = 양성암
# precision
a = 127 / (127 + 2);print(a)
# recall
b = 127 / (127 + 4);print(b)
# f-1 score
(2*a*b)/(a+b)
# 양성클래스 4 = malignant cancer = 악성암
# precision
a = 72 / (72 + 4);print(a)
# recall
b = 72 / (72 + 2);print(b)
# f-1 score
(2*a*b)/(a+b)
* 시각화
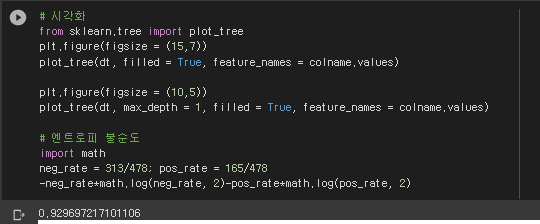
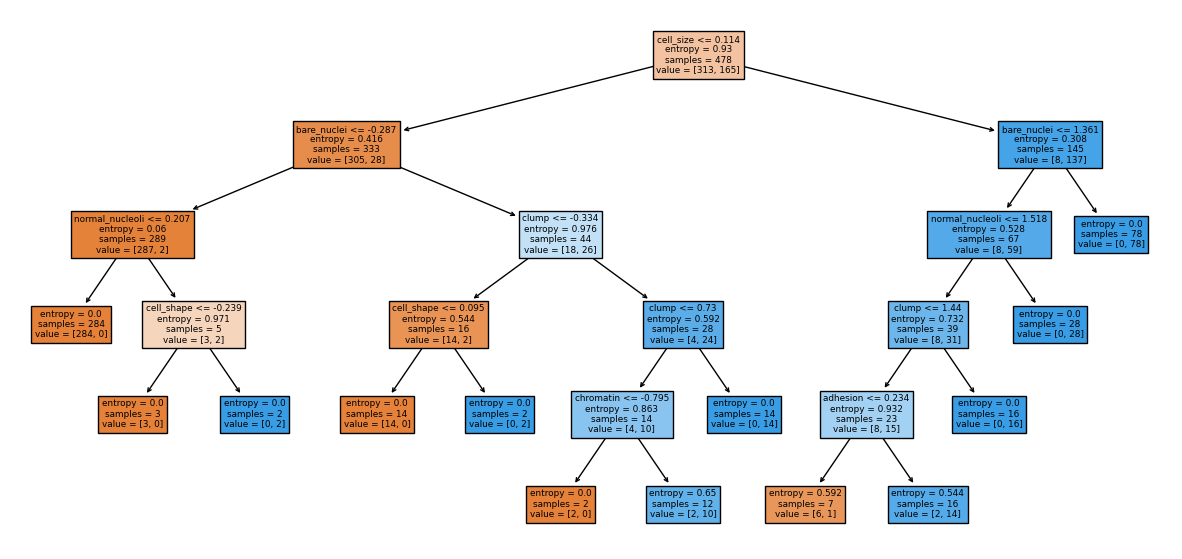
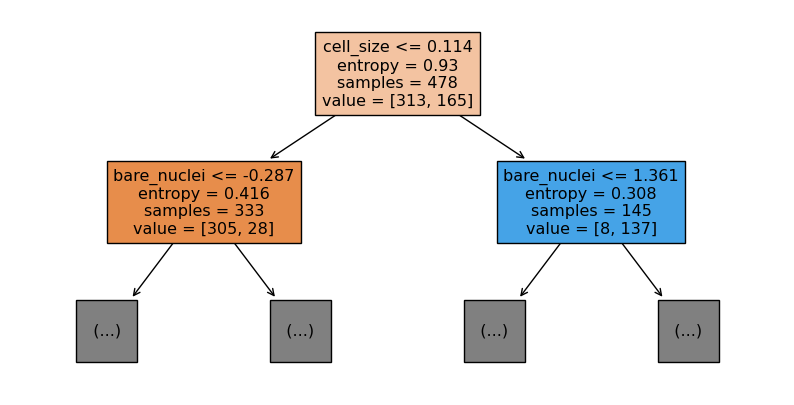
* 모델 객체 ~ 모형 학습 ~ 지니 불순도 까지 시각화
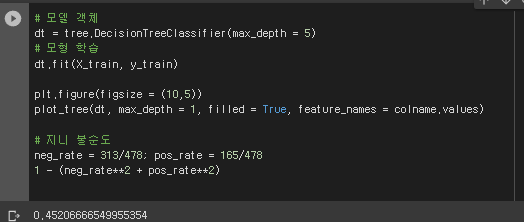
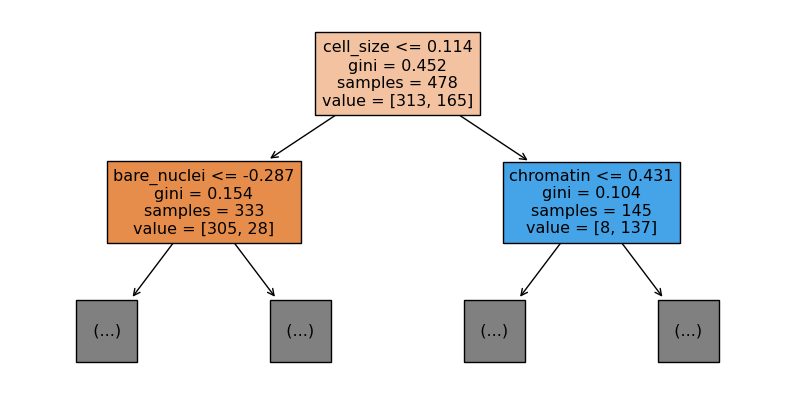
# 모델 객체
dt = tree.DecisionTreeClassifier(max_depth = 5)
# 모형 학습
dt.fit(X_train, y_train)
plt.figure(figsize = (10,5))
plot_tree(dt, max_depth = 1, filled = True, feature_names = colname.values)
# 지니 불순도
neg_rate = 313/478; pos_rate = 165/478
1 - (neg_rate**2 + pos_rate**2)
5) 분류 모델 - SVM
* 데이터 불러오기 ~ 탐색/전처리 ~ 분석할 열 선택
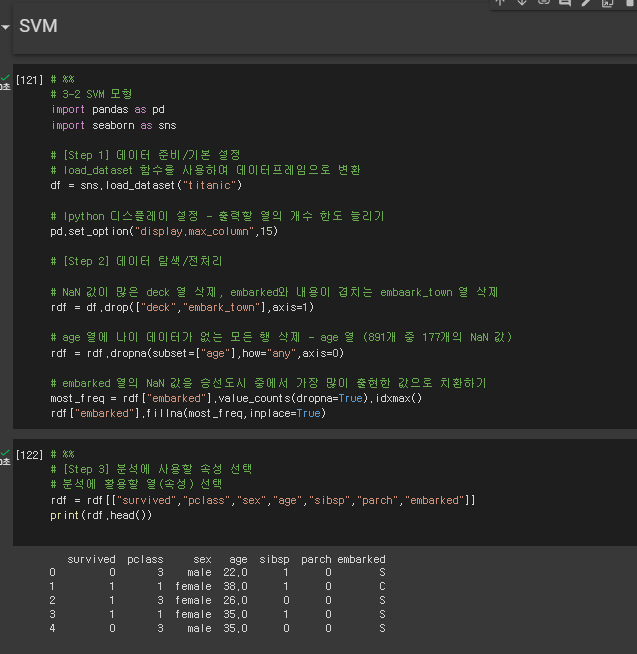
# %%
# 3-2 SVM 모형
import pandas as pd
import seaborn as sns
# [Step 1] 데이터 준비/기본 설정
# load_dataset 함수를 사용하여 데이터프레임으로 변환
df = sns.load_dataset("titanic")
# Ipython 디스플레이 설정 - 출력할 열의 개수 한도 늘리기
pd.set_option("display.max_column",15)
# [Step 2] 데이터 탐색/전처리
# NaN 값이 많은 deck 열 삭제, embarked와 내용이 겹치는 embaark_town 열 삭제
rdf = df.drop(["deck","embark_town"],axis=1)
# age 열에 나이 데이터가 없는 모든 행 삭제 - age 열 (891개 중 177개의 NaN 값)
rdf = rdf.dropna(subset=["age"],how="any",axis=0)
# embarked 열의 NaN 값을 승선도시 중에서 가장 많이 출현한 값으로 치환하기
most_freq = rdf["embarked"].value_counts(dropna=True).idxmax()
rdf["embarked"].fillna(most_freq,inplace=True)
# %%
# [Step 3] 분석에 사용할 속성 선택
# 분석에 활용할 열(속성) 선택
rdf = rdf[["survived","pclass","sex","age","sibsp","parch","embarked"]]
print(rdf.head())
* 모형 객체 생성 ~ 데이터 분류 ~ 모형 성능 평가
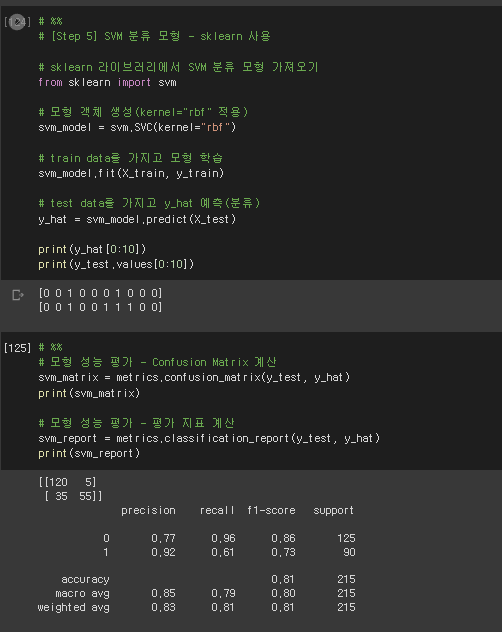
# %%
# [Step 5] SVM 분류 모형 - sklearn 사용
# sklearn 라이브러리에서 SVM 분류 모형 가져오기
from sklearn import svm
# 모형 객체 생성(kernel="rbf" 적용)
svm_model = svm.SVC(kernel="rbf")
# train data를 가지고 모형 학습
svm_model.fit(X_train, y_train)
# test data를 가지고 y_hat 예측(분류)
y_hat = svm_model.predict(X_test)
print(y_hat[0:10])
print(y_test.values[0:10])
# %%
# 모형 성능 평가 - Confusion Matrix 계산
svm_matrix = metrics.confusion_matrix(y_test, y_hat)
print(svm_matrix)
# 모형 성능 평가 - 평가 지표 계산
svm_report = metrics.classification_report(y_test, y_hat)
print(svm_report)
6) 결정 트리 구조 (수치로 확인하는)
* 데이터 준비/기본 설정 ~ 데이터 탐색
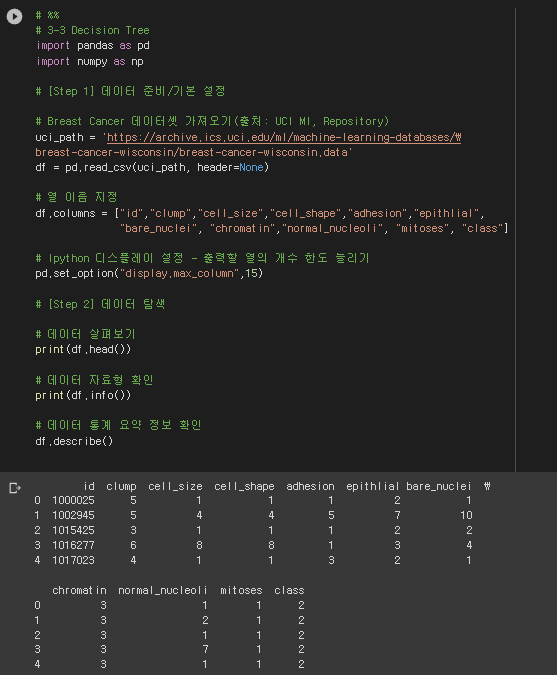
# %%
# 3-3 Decision Tree
import pandas as pd
import numpy as np
# [Step 1] 데이터 준비/기본 설정
# Breast Cancer 데이터셋 가져오기(출처: UCI MI, Repository)
uci_path = 'https://archive.ics.uci.edu/ml/machine-learning-databases/\
breast-cancer-wisconsin/breast-cancer-wisconsin.data'
df = pd.read_csv(uci_path, header=None)
# 열 이름 지정
df.columns = ["id","clump","cell_size","cell_shape","adhesion","epithlial",
"bare_nuclei", "chromatin","normal_nucleoli", "mitoses", "class"]
# Ipython 디스플레이 설정 - 출력할 열의 개수 한도 늘리기
pd.set_option("display.max_column",15)
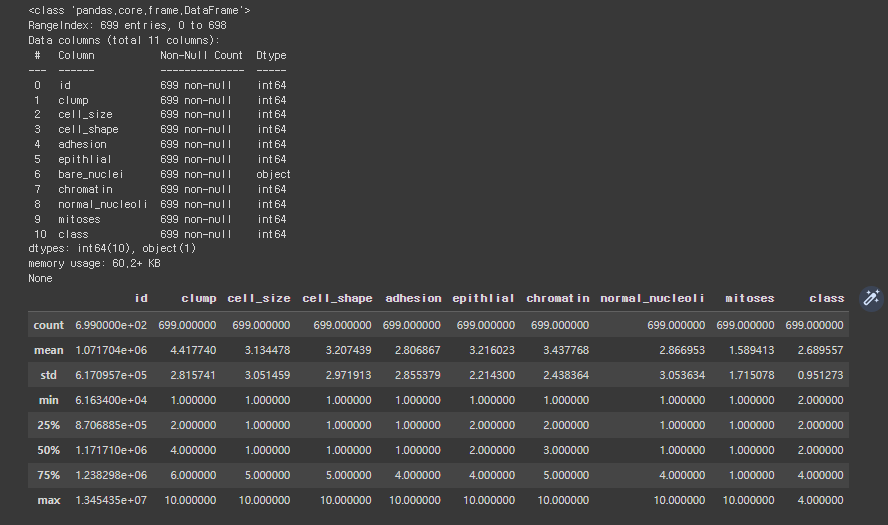
# [Step 2] 데이터 탐색
# 데이터 살펴보기
print(df.head())
# 데이터 자료형 확인
print(df.info())
# 데이터 통계 요약 정보 확인
df.describe()
* 데이터 전처리
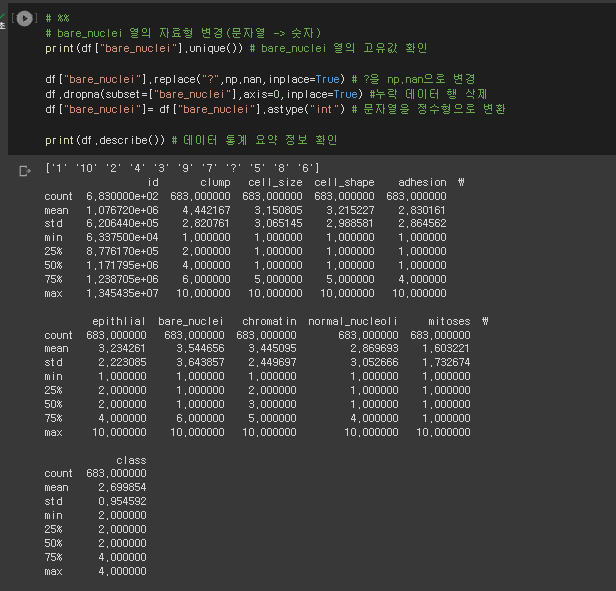
# %%
# bare_nuclei 열의 자료형 변경(문자열 -> 숫자)
print(df["bare_nuclei"].unique()) # bare_nuclei 열의 고유값 확인
df["bare_nuclei"].replace("?",np.nan,inplace=True) # ?을 np.nan으로 변경
df.dropna(subset=["bare_nuclei"],axis=0,inplace=True) #누락 데이터 행 삭제
df["bare_nuclei"]= df["bare_nuclei"].astype("int") # 문자열을 정수형으로 변환
print(df.describe()) # 데이터 통계 요약 정보 확인
* 데이터 셋 구분 - 훈련용/검증용 ~ 결정트리 분류 모형
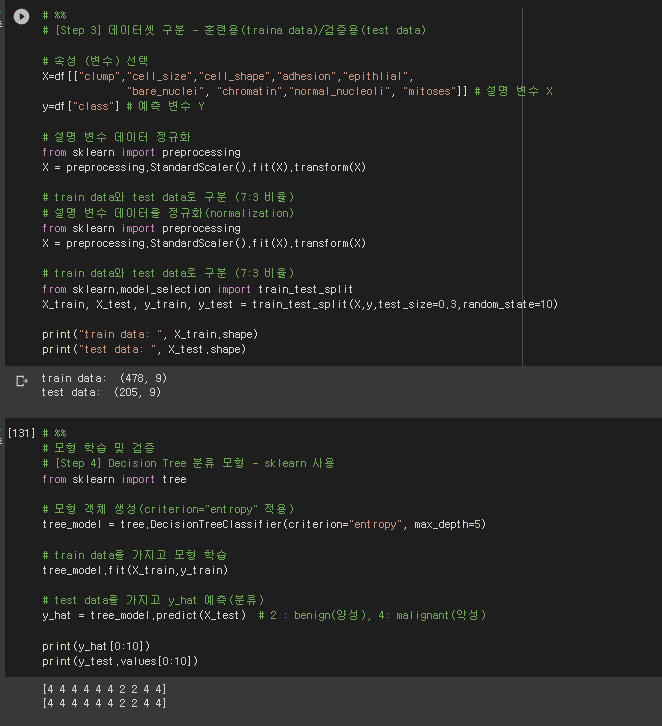
# %%
# [Step 3] 데이터셋 구분 - 훈련용(traina data)/검증용(test data)
# 속성 (변수) 선택
X=df[["clump","cell_size","cell_shape","adhesion","epithlial",
"bare_nuclei", "chromatin","normal_nucleoli", "mitoses"]] # 설명 변수 X
y=df["class"] # 예측 변수 Y
# 설명 변수 데이터 정규화
from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X)
# train data와 test data로 구분 (7:3 비율)
# 설명 변수 데이터를 정규화(normalization)
from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X)
# train data와 test data로 구분 (7:3 비율)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3,random_state=10)
print("train data: ", X_train.shape)
print("test data: ", X_test.shape)
# %%
# 모형 학습 및 검증
# [Step 4] Decision Tree 분류 모형 - sklearn 사용
from sklearn import tree
# 모형 객체 생성(criterion="entropy" 적용)
tree_model = tree.DecisionTreeClassifier(criterion="entropy", max_depth=5)
# train data를 가지고 모형 학습
tree_model.fit(X_train,y_train)
# test data를 가지고 y_hat 예측(분류)
y_hat = tree_model.predict(X_test) # 2 : benign(양성), 4: malignant(악성)
print(y_hat[0:10])
print(y_test.values[0:10])
* 모형 성능 평가
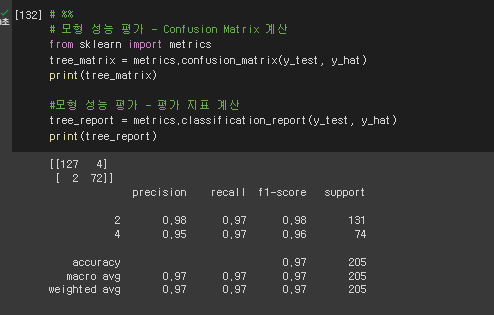
# %%
# 모형 성능 평가 - Confusion Matrix 계산
from sklearn import metrics
tree_matrix = metrics.confusion_matrix(y_test, y_hat)
print(tree_matrix)
#모형 성능 평가 - 평가 지표 계산
tree_report = metrics.classification_report(y_test, y_hat)
print(tree_report)
7) 분류 모델 - SVM2 (시각화에 필요한 자료)
* 데이터 준비 ~ 데이터 전처리
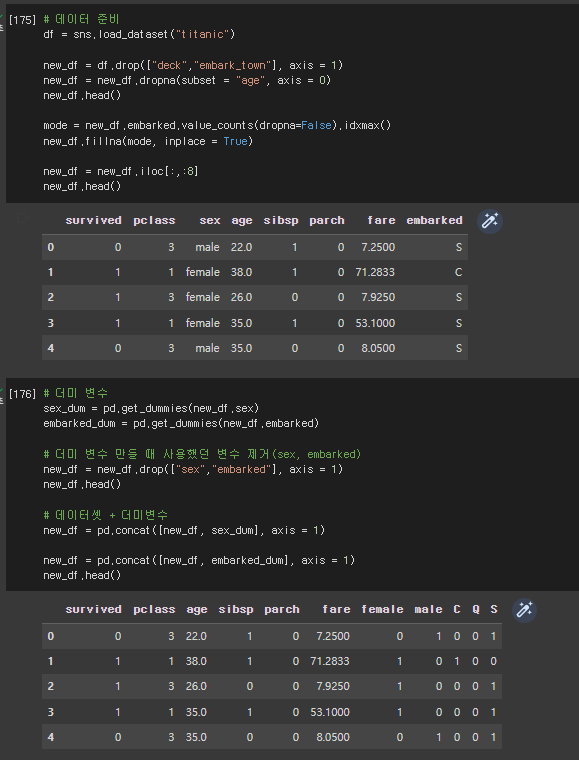
# 데이터 준비
df = sns.load_dataset("titanic")
new_df = df.drop(["deck","embark_town"], axis = 1)
new_df = new_df.dropna(subset = "age", axis = 0)
new_df.head()
mode = new_df.embarked.value_counts(dropna=False).idxmax()
new_df.fillna(mode, inplace = True)
new_df = new_df.iloc[:,:8]
new_df.head()
# 더미 변수
sex_dum = pd.get_dummies(new_df.sex)
embarked_dum = pd.get_dummies(new_df.embarked)
# 더미 변수 만들 때 사용했던 변수 제거(sex, embarked)
new_df = new_df.drop(["sex","embarked"], axis = 1)
new_df.head()
# 데이터셋 + 더미변수
new_df = pd.concat([new_df, sex_dum], axis = 1)
new_df = pd.concat([new_df, embarked_dum], axis = 1)
new_df.head()
* 데이터 분할 ~ 모형 학습
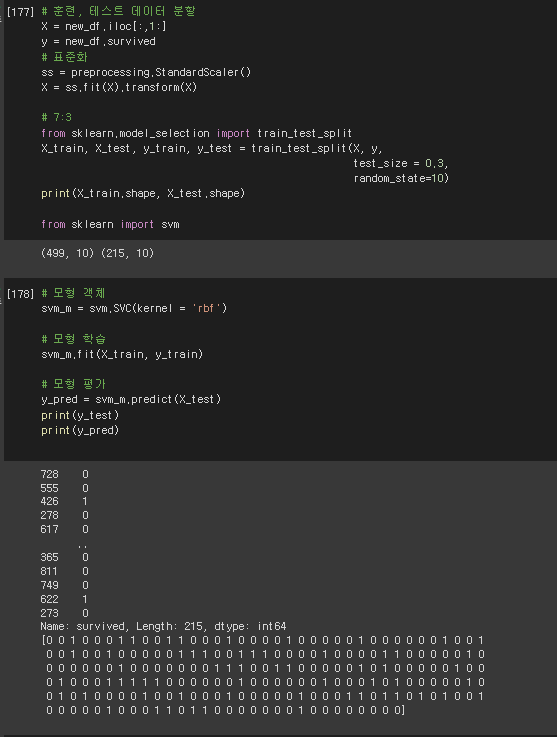
# 훈련, 테스트 데이터 분할
X = new_df.iloc[:,1:]
y = new_df.survived
# 표준화
ss = preprocessing.StandardScaler()
X = ss.fit(X).transform(X)
# 7:3
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 0.3,
random_state=10)
print(X_train.shape, X_test.shape)
from sklearn import svm
# 모형 객체
svm_m = svm.SVC(kernel = 'rbf')
# 모형 학습
svm_m.fit(X_train, y_train)
# 모형 평가
y_pred = svm_m.predict(X_test)
print(y_test)
print(y_pred)
* 모형 성능 평가 - 지표 계산
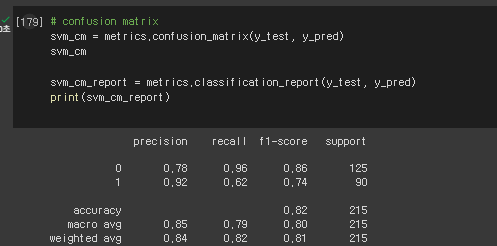
# confusion matrix
svm_cm = metrics.confusion_matrix(y_test, y_pred)
svm_cm
svm_cm_report = metrics.classification_report(y_test, y_pred)
print(svm_cm_report)
* 핵심
- 모형 평가 (confusion matrix) 이해하기
- 머신러닝에서 결정 트리 구조에 대해 이해하기 (시각화 이미지 참고하여)
- 엔트로피 불순도 이해하기
- 지니 불순도 이해하기
* 코랩 링크 (작성한 계정으로 로그인)
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
* 오늘 실습 링크 (0502.py)
guromd1
guromd1.blogspot.com
'배운 책들 정리 > 혼자 공부하는 파이썬' 카테고리의 다른 글
| 혼자 공부하는 파이썬 8 - 객체, 클래스, 메소드 // 복습 (0) | 2023.04.20 |
|---|---|
| 혼자 공부하는 파이썬 6,7 - 예외 처리, 모듈 (1) | 2023.04.19 |
| 혼자 공부하는 파이썬 5,6 - 함수 고급, 예외 처리 (1) | 2023.04.18 |
| 혼자 공부하는 파이썬 5 - 함수 만들기, 함수의 활용 (1) | 2023.04.17 |
| 혼자 공부하는 파이썬 4 - 문자열, 리스트, 딕셔너리와 관련된 기본 함수(while,range,reversed,enumerate,Counter 등등) (0) | 2023.04.14 |



